PyTorch LSTM Formas de entrada, estado oculto, estado de celda y salida
PyTorch LSTM Entradas, estado oculto, estado de celda y salida
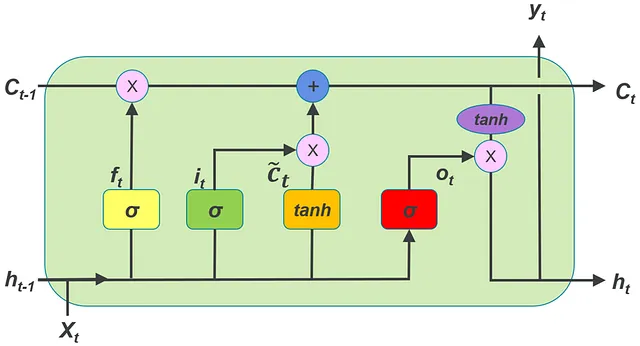
En Pytorch, para usar un LSTM (con nn.LSTM()), necesitamos entender cómo deben tener forma los tensores que representan la serie temporal de entrada, el vector de estado oculto y el vector de estado de celda. En este artículo, vamos a suponer que estás trabajando con una serie temporal multivariada. Cada serie temporal multivariada en el conjunto de datos contiene múltiples series temporales univariadas.
Las siguientes son las diferencias del LSTMCell de Pytorch que se discuten en el siguiente enlace:
Pytorch LSTMCell — formas de la entrada, estado oculto y estado de celda
En Pytorch, para usar un LSTMCell, necesitamos entender cómo deben tener forma los tensores que representan la serie temporal de entrada, el estado oculto…
VoAGI.com
- ¿Cómo elimina el nuevo paradigma de Google AI el costo de composición en algoritmos de aprendizaje automático de múltiples pasos para una mayor utilidad?
- Una nueva investigación de IA de Tel Aviv y la Universidad de Copenhague introduce un enfoque de conectar y usar para ajustar rápidamente modelos de difusión de texto a imagen utilizando una señal discriminativa.
- Investigadores de Google AI presentan MADLAD-400 un conjunto de datos de dominio web con tokens de 2.8T que abarca 419 idiomas.
- Con nn.LSTM se pueden crear múltiples capas de LSTM apilándolas para formar un LSTM apilado. El segundo LSTM toma la salida del primer LSTM como entrada y así sucesivamente.
2. Se puede agregar dropout en la clase nn.LSTM.
3. Se pueden proporcionar entradas no agrupadas a nn.LSTM.
Hay una diferencia más significativa que se discutirá más adelante en esta publicación.
En este artículo utilizamos la siguiente terminología:
batch = número de series temporales multivariadas en un solo lote del conjunto de datos
input_features = número de series temporales univariadas en una serie temporal multivariada
time steps = número de pasos de tiempo en cada serie temporal multivariada
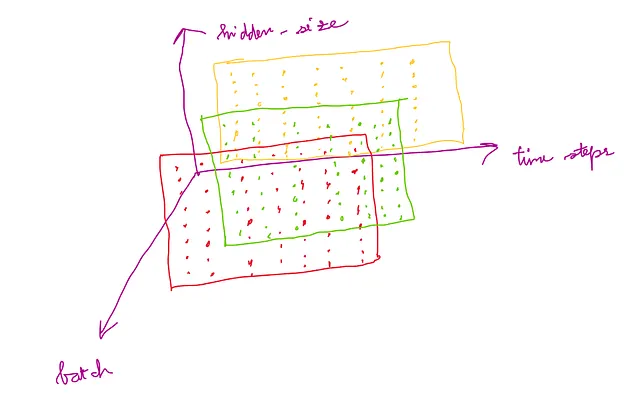
El lote de series temporales multivariadas que se va a proporcionar como entrada al LSTM debe ser un tensor de forma (time_steps, batch, input_features)
La siguiente imagen muestra una comprensión de esta forma para la entrada:

Pero, en LSTM, también hay otra forma de dar forma a la entrada. Esto se explica a continuación.
Al inicializar un objeto LSTM, se deben proporcionar los argumentos input_features y hidden_size.
Aquí,
input_features = número de series temporales univariadas en una serie temporal multivariada (mismo valor que input_features mencionado anteriormente)
hidden_size = número de dimensiones en el vector de estado oculto.
Otros argumentos que puede tener la clase LSTM:
num_layers = número de capas LSTM apiladas una encima de la otra. Cuando se apilan varias capas una encima de la otra, se llama LSTM apilada. Por defecto, el número de capas = 1
dropout = si es distinto de cero, se agregará una capa de dropout a la salida de cada capa LSTM con una probabilidad de dropout igual a este valor. Por defecto, este valor es 0, lo que significa que no hay dropout.
batch_first = si esto es True, los tensores de entrada y salida tendrán dimensiones (batch, time_steps, input_features) en lugar de (time_steps, batch, input_features). Por defecto, esto es False.
proj_size = tamaño de proyección. Si proj_size > 0, se utilizará LSTM con proyecciones.
La serie temporal y el estado oculto inicial y el estado de celda inicial deben proporcionarse como entrada para una propagación hacia adelante a través del LSTM.
La propagación hacia adelante de la entrada, el estado oculto inicial y el estado de celda inicial a través del objeto LSTM debe tener el siguiente formato:
LSTM(serie_temporal_entrada, (h_0, c_0))
Vamos a ver cómo dar forma al vector de estado oculto y al vector de estado de celda antes de darlos al LSTM para la propagación hacia adelante.
h_0 — (num_layers, batch, h_out). Aquí h_out = proj_size si proj_size > 0, de lo contrario, hidden_size
c_0 — (num_layers, batch, hidden_size)
La siguiente imagen ayuda a entender la forma de los vectores ocultos.

Una imagen similar se aplica también a los vectores de estado de las celdas.
A partir de la imagen se puede entender que la dimensionalidad de los estados ocultos y de las celdas para todas las capas es la misma.
Considera el siguiente fragmento de código:
import torchimport torch.nn as nn lstm_0 = nn.LSTM(10, 20, 2) # (input_features, hidden_size, num_layers)inp = torch.randn(4, 3, 10) # (time_steps, batch, input_features) -> serie de tiempo de entradah0 = torch.randn(2, 3, 20) # (num_layers, batch, hidden_size) -> valor inicial del estado oculto c0 = torch.randn(2, 3, 20) # (num_layers, batch, hidden_size) -> valor inicial del estado de la celdaoutput, (hn, cn) = lstm_0(input, (h0, c0)) # paso hacia adelante de la entrada a través de la LSTMLlamar a nn.LSTM() llamará al método mágico __init__() y creará el objeto LSTM. En el código anterior, este objeto se referencia como lstm_0.
En las RNN en general (LSTM es un tipo de RNN), cada paso de tiempo de la serie de tiempo de entrada debe pasar por la RNN uno por uno en orden secuencial para ser procesado por la RNN.
Para procesar una serie de tiempo multivariable en un lote utilizando una LSTM, cada paso de tiempo en todas las series de tiempo en el lote debe pasar por la LSTM secuencialmente.
Una única llamada al paso hacia adelante de la LSTM procesa toda la serie al procesar cada paso de tiempo secuencialmente. Esto es diferente de LSTMCell, en la que una única llamada procesa solo un paso de tiempo y no toda la serie.
La salida del código anterior es:
tensor([[[ 3.8995e-02, 1.1831e-01, 1.1922e-01, 1.3734e-01, 1.6157e-02, 3.3094e-02, 2.8738e-01, -6.9250e-02, -1.8313e-01, -1.2594e-01, 1.4951e-01, -3.2489e-01, 2.1723e-01, -1.1722e-01, -2.5523e-01, -6.5740e-02, -5.2556e-02, -2.7092e-01, 3.0432e-01, 1.4228e-01], [ 9.2476e-02, 1.1557e-02, -9.3600e-03, -5.2662e-02, 5.5299e-03, -6.2017e-02, -1.9826e-01, -2.7072e-01, -5.5575e-02, -2.3024e-03, -2.6832e-01, -5.8481e-01, -8.3415e-03, -2.8817e-01, 4.6101e-03, 3.5043e-02, -6.2501e-01, 4.2930e-02, -5.4698e-01, -5.8626e-01], [-2.8034e-01, -3.4194e-01, -2.1888e-02, -2.1787e-01, -4.0497e-01, -3.6124e-01, -1.5303e-01, -1.3310e-01, -3En esta salida hay 4 arrays correspondientes a los 4 pasos de tiempo. Cada uno de estos time_steps contiene 3 arrays correspondientes a los 3 MTS en el lote. Cada uno de estos 3 arrays contiene 20 elementos -> este es el estado oculto. Por lo tanto, para cada vector x_t en cada time_step en cada MTS, se produce un estado oculto. Estos son los estados ocultos en la última capa del LSTM apilado.
Salida: (output_multivariate_time_series, (h_n, c_n))
Si imprime hn que está presente en el código anterior, el siguiente es la salida:
tensor([[[-0.3046, -0.1601, -0.0024, -0.0138, -0.1810, -0.1406, -0.1181, 0.0634, 0.0936, -0.1094, -0.2822, -0.2263, -0.1090, 0.2933, 0.0760, -0.1877, -0.0877, -0.0813, 0.0848, 0.0121], [ 0.0349, -0.2068, 0.1353, 0.1121, 0.1940, -0.0663, -0.0031, -0.2047, -0.0008, -0.0439, -0.0249, 0.0679, -0.0530, 0.1078, -0.0631, 0.0430, 0.0873, -0.1087, 0.3161, -0.1618], [-0.0528, -0.2693, 0.1001, -0.1097, 0.0097, -0.0677, -0.0048, 0.0509, 0.0655, 0.0075, -0.1127, -0.0641, 0.0050, 0.1991, 0.0370, -0.0923, 0.0629, 0.0122, 0.0688, -0.2374]], [[ 0.0273, -0.1082, 0.0243, -0.0924, 0.0077, 0.0359, 0.1209, 0.0545, -0.0838, 0.0139, 0.0086, -0.2110, 0.0880, -0.1371, -0.0171, 0.0332, 0.0509, -0.1481, 0.2044, -0.1747], [ 0.0087, -0.0943, 0.0111, -0.0618, -0.0376, -0.1297, 0.0497, 0.0071, -0.0905, 0.0700, -0.1282, -0.2104, 0.1350, -0.1672, 0.0697, 0.0679, 0.0512, 0.0183, 0.1531, -0.2602], [-0.0705, -0.1263, 0.0099, -0.0797, -0.1074, -0.0752, 0.1020, 0.0254, -0.1382, -0.0007, -0.0787, -0.1934, 0.1283, -0.0721, 0.1132, 0.0252, 0.0765, 0.0238, 0.1846, -0.2379]]], grad_fn=<StackBackward0>)
Esto contiene los vectores de estado oculto en la primera capa y la segunda capa en el LSTM apilado para el último time_step en cada uno de los 3 MTS en el lote. Si te fijas, el estado oculto de la segunda capa (última capa) es el mismo que el estado oculto del último paso de tiempo mencionado anteriormente.
Entonces, la dimensionalidad de salida de MTS es (time_steps, batch, hidden_size).
Esta dimensionalidad de salida se puede entender a partir de la imagen a continuación:
La dimensionalidad de h_n es: (num_layers, batch, h_out)
La dimensionalidad de c_n es: (num_layers, batch, hidden_size)
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
-
Este artículo de Alibaba Group presenta FederatedScope-LLM un paquete integral para el ajuste fino de LLMs en el aprendizaje federado
-
Una técnica de mapeo de posturas podría evaluar de forma remota a pacientes con parálisis cerebral
-
Desplegando modelos de PyTorch con el servidor de inferencia Nvidia Triton
-
Cómo construir gráficos de cascada con Plotly Graph Objects
-
¡Pide tus documentos con Langchain y Deep Lake!
-
Inteligencia Artificial y la Estética de la Generación de Imágenes
-
Hoja de referencia de Scikit-learn para Aprendizaje Automático





