Pythia Un conjunto de 16 LLMs para investigación en profundidad
Pythia un conjunto de 16 LLMs para investigación profunda

Hoy en día, los grandes modelos de lenguaje y los chatbots basados en LLM, como ChatGPT y GPT-4, se han integrado bien en nuestra vida diaria.
Sin embargo, los modelos transformadores autogresivos solo con decodificador se han utilizado ampliamente para aplicaciones generativas de PLN mucho antes de que las aplicaciones de LLM se volvieran populares. Puede ser útil comprender cómo evolucionan durante el entrenamiento y cómo cambia su rendimiento a medida que aumentan de escala.
Pythia, un proyecto de Eleuther AI, es una suite de 16 grandes modelos de lenguaje que proporciona reproducibilidad para el estudio, análisis e investigación adicional. Este artículo es una introducción a Pythia.
- Una guía completa sobre la arquitectura UNET | Dominando la segmentación de imágenes
- Un enfoque sistemático para elegir la mejor tecnología/proveedor versión MLOps
- 4 formas en las que no puedes usar el intérprete de código ChatGPT que perturbarán tus análisis
¿Qué ofrece la suite Pythia?
Como se mencionó, Pythia es una suite de 16 grandes modelos de lenguaje, modelos transformadores autogresivos solo con decodificador, entrenados en conjuntos de datos disponibles públicamente. Los modelos en la suite tienen tamaños que van desde 70M hasta 12B de parámetros.
- Toda la suite se entrenó con los mismos datos en el mismo orden. Esto facilita la reproducibilidad del proceso de entrenamiento. Por lo tanto, no solo podemos replicar la tubería de entrenamiento, sino también analizar los modelos de lenguaje y estudiar su comportamiento en profundidad.
- También proporciona facilidades para descargar los cargadores de datos de entrenamiento y más de 154 puntos de control del modelo para cada uno de los 16 modelos de lenguaje.
Datos de entrenamiento y proceso de entrenamiento
Ahora profundicemos en los detalles de la suite Pythia LLM.
Conjunto de datos de entrenamiento
La suite Pythia LLM se entrenó con los siguientes conjuntos de datos:
- Conjunto de datos Pile con 300B tokens
- Conjunto de datos Pile deduplicado con 207B tokens
Hay 8 tamaños de modelos diferentes, siendo los modelos más pequeños y más grandes los que tienen 70M y 12B de parámetros, respectivamente. Otros tamaños de modelo incluyen 160M, 410M, 1B, 1.4B, 2.8B y 6.9B.
Cada uno de estos modelos se entrenó tanto en los conjuntos de datos Pile como en los conjuntos de datos Pile duplicados, lo que resulta en un total de 16 modelos. La siguiente tabla muestra los tamaños de los modelos y un subconjunto de hiperparámetros.
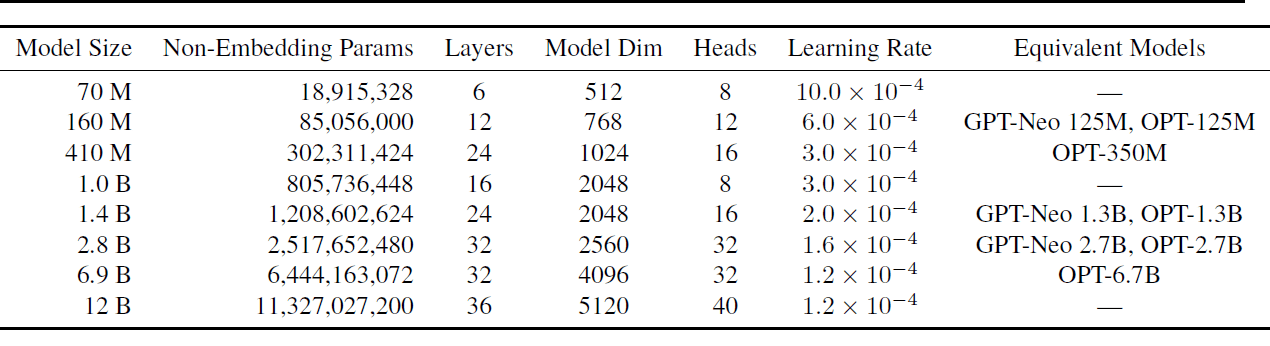
Para obtener todos los detalles de los hiperparámetros utilizados, lea Pythia: Una suite para analizar grandes modelos de lenguaje a través del entrenamiento y la escala.
Proceso de entrenamiento
Aquí hay una descripción general de la arquitectura y el proceso de entrenamiento:
- Todos los modelos tienen capas completamente densas y utilizan atención flash.
- Para una interpretación más fácil, se utilizan matrices de inserción no vinculadas.
- Se utiliza un tamaño de lote de 1024 con una longitud de secuencia de 2048. Este tamaño de lote grande reduce sustancialmente el tiempo de entrenamiento en el reloj.
- El proceso de entrenamiento también aprovecha técnicas de optimización como la paralelización de datos y tensores.
Para el proceso de entrenamiento, se utiliza la biblioteca GPT-Neo-X (que incluye características de la biblioteca DeepSpeed) desarrollada por Eleuther AI.
Puntos de control del modelo
Hay 154 puntos de control para cada modelo. Hay un punto de control cada 1000 iteraciones. Además, hay puntos de control en intervalos espaciados de registro al comienzo del proceso de entrenamiento: 1, 2, 4, 8, 16, 32, 64, 128, 256 y 512.
¿Cómo se compara Pythia con otros modelos de lenguaje?
La suite Pythia LLM se evaluó en comparación con los puntos de referencia de modelado de lenguaje disponibles, incluida la variante LAMBADA de OpenAI. Se encontró que el rendimiento de Pythia es comparable a los modelos de lenguaje OPT y BLOOM.
Ventajas y Limitaciones
La principal ventaja de la suite Pythia LLM es la reproducibilidad. El conjunto de datos está disponible públicamente, así como los cargadores de datos pre-tokenizados y 154 puntos de control del modelo. También se ha publicado la lista completa de hiperparámetros. Esto facilita la replicación del entrenamiento del modelo y el análisis.
En [1], los autores explican su razonamiento para elegir un conjunto de datos en inglés en lugar de un corpus de texto multilingüe. Pero tener flujos de trabajo de entrenamiento reproducibles para modelos de lenguaje multilingües puede ser útil. Especialmente para fomentar más investigación y estudio de la dinámica de los modelos de lenguaje multilingües a gran escala.
Una Visión General de Estudios de Caso
La investigación también presenta interesantes estudios de caso que aprovechan la reproducibilidad del proceso de entrenamiento de modelos de lenguaje grandes en la suite Pythia.
Sesgo de Género
Todos los modelos de lenguaje grandes son propensos a sesgos y desinformación. El estudio se centra en mitigar el sesgo de género modificando los datos de preentrenamiento de manera que un porcentaje fijo contenga pronombres de un género específico. Este preentrenamiento también es reproducible.
Memorización
La memorización en modelos de lenguaje grandes es otra área que se ha estudiado ampliamente. La memorización de secuencias se modela como un proceso de punto de Poisson. El estudio tiene como objetivo comprender si la ubicación de la secuencia específica en el conjunto de datos de entrenamiento influye en la memorización. Se observó que la ubicación no afecta la memorización.
Efecto de las Frecuencias de Términos de Preentrenamiento
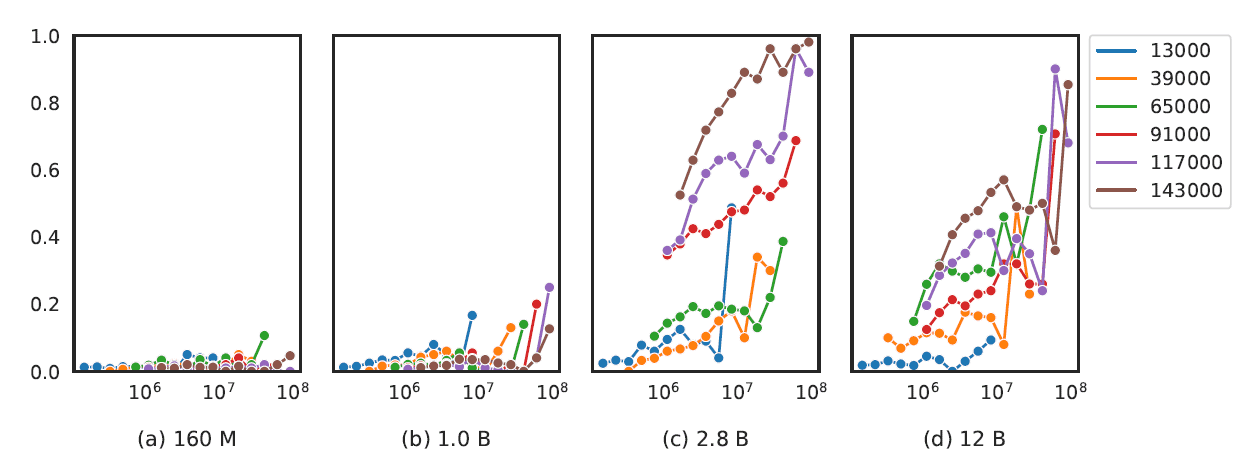
Para modelos de lenguaje con 2.8B de parámetros y más, se encontró que la aparición de términos específicos de la tarea en el corpus de preentrenamiento mejora el rendimiento del modelo en tareas como la respuesta a preguntas.
También hay una correlación entre el tamaño del modelo y el rendimiento en tareas más complejas como el cálculo y el razonamiento matemático.
Resumen y Siguientes Pasos
Resumamos los puntos clave de nuestra discusión.
- Pythia de Eleuther AI es una suite de 16 LLMs entrenados en los conjuntos de datos públicamente disponibles Pile y Pile deduplicados.
- El tamaño de los LLMs varía desde 70M hasta 12B de parámetros.
- Los datos de entrenamiento y los puntos de control del modelo son de código abierto y es posible reconstruir los mismos cargadores de datos de entrenamiento exactos. Por lo tanto, la suite LLM puede ser útil para comprender mejor la dinámica del entrenamiento de modelos de lenguaje grandes.
Como próximo paso, puedes explorar la suite de modelos Pythia y los puntos de control del modelo en Hugging Face Hub.
Referencia
[1] Pythia: Una Suite para Analizar Modelos de Lenguaje Grandes a lo Largo del Entrenamiento y Escalado, arXiv, 2023 Bala Priya C es una desarrolladora y escritora técnica de India. Le gusta trabajar en la intersección entre matemáticas, programación, ciencia de datos y creación de contenido. Sus áreas de interés y experiencia incluyen DevOps, ciencia de datos y procesamiento del lenguaje natural. Le gusta leer, escribir, programar y tomar café. Actualmente, está trabajando en aprender y compartir sus conocimientos con la comunidad de desarrolladores mediante la creación de tutoriales, guías prácticas, opiniones y más.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Implementación de ParDo y DoFn en Apache Beam en Detalles
- Generando datos sintéticos con Python
- Todos los Modelos de Lenguaje Grande (LLMs) que Debes Conocer en 2023
- ¿Es bueno tu modelo? Un análisis en profundidad de las métricas avanzadas de Amazon SageMaker Canvas
- Esta semana en IA, 31 de julio de 2023
- AI Equipaje para Personas con Discapacidad Visual Recibe Excelentes Críticas
- ¡Ahora puedes ver la Cumbre de IA Generativa a pedido aquí!






