Pronóstico de series de tiempo probabilísticas con 🤗 Transformers
'Pronóstico de series de tiempo con 🤗 Transformers'
![]()
Introducción
La predicción de series temporales es un problema científico y empresarial esencial y, como tal, también ha experimentado mucha innovación recientemente con el uso de modelos basados en aprendizaje profundo además de los métodos clásicos. Una diferencia importante entre los métodos clásicos como ARIMA y los nuevos métodos de aprendizaje profundo es la siguiente.
Predicción probabilística
Típicamente, los métodos clásicos se ajustan individualmente a cada serie temporal en un conjunto de datos. A menudo se les llama métodos “individuales” o “locales”. Sin embargo, al tratar con una gran cantidad de series temporales para algunas aplicaciones, es beneficioso entrenar un modelo “global” en todas las series temporales disponibles, lo que permite al modelo aprender representaciones latentes de muchas fuentes diferentes.
Algunos métodos clásicos son de valor puntual (es decir, solo devuelven un valor único por paso de tiempo) y los modelos se entrenan minimizando una pérdida del tipo L2 o L1 con respecto a los datos de verdad fundamentales. Sin embargo, dado que las predicciones se utilizan a menudo en un proceso de toma de decisiones del mundo real, incluso con humanos involucrados, es mucho más beneficioso proporcionar las incertidumbres de las predicciones. Esto también se llama “predicción probabilística”, en contraposición a la “predicción puntual”. Esto implica modelar una distribución probabilística, a partir de la cual se puede muestrear.
- Usando la Difusión Estable con Core ML en Apple Silicon
- De GPT2 a Stable Diffusion Hugging Face llega a la comunidad de Elixir
- Ilustrando el Aprendizaje por Reforzamiento a través de la Retroalimentación Humana (RLHF)
Entonces, en resumen, en lugar de entrenar modelos locales de predicción puntual, esperamos entrenar modelos globales probabilísticos. El aprendizaje profundo es muy adecuado para esto, ya que las redes neuronales pueden aprender representaciones de varias series temporales relacionadas y también modelar la incertidumbre de los datos.
Es común en el entorno probabilístico aprender los parámetros futuros de alguna distribución paramétrica elegida, como Gaussiana o Student-T; o aprender la función cuantil condicional; o utilizar el marco de Predicción Conforme adaptado al entorno de series temporales. La elección del método no afecta al aspecto del modelado y, por lo tanto, se puede considerar típicamente como otro hiperparámetro. Siempre se puede convertir un modelo probabilístico en un modelo de predicción puntual, tomando medias o medianas empíricas.
El Transformador de Series Temporales
En términos de modelado de datos de series temporales que son secuenciales por naturaleza, como se puede imaginar, los investigadores han creado modelos que utilizan Redes Neuronales Recurrentes (RNN) como LSTM o GRU, o Redes Convolucionales (CNN), y más recientemente métodos basados en Transformadores que se ajustan naturalmente al entorno de pronóstico de series temporales.
En esta publicación de blog, vamos a aprovechar el Transformador básico (Vaswani et al., 2017) para la tarea de pronóstico probabilístico univariado (es decir, predecir la distribución de 1 dimensión de cada serie temporal individualmente). El Transformador Codificador-Decodificador es una elección natural para el pronóstico, ya que encapsula varios sesgos inductivos de manera agradable.
Para empezar, el uso de una arquitectura Codificador-Decodificador es útil en el momento de la inferencia, donde típicamente para algunos datos registrados deseamos pronosticar algunos pasos de predicción en el futuro. Esto se puede considerar como análogo a la tarea de generación de texto donde, dada cierto contexto, muestreamos el siguiente token y lo pasamos de nuevo al decodificador (también llamado “generación autoregresiva”). De manera similar, aquí también podemos, dada cierta distribución, muestrear de ella para proporcionar pronósticos hasta nuestro horizonte de predicción deseado. Esto se conoce como Muestreo/Busqueda Gula y hay una excelente publicación de blog al respecto aquí para el entorno de Procesamiento de Lenguaje Natural (NLP, por sus siglas en inglés).
En segundo lugar, un Transformador nos ayuda a entrenar con datos de series temporales que pueden contener miles de puntos de tiempo. Puede que no sea factible ingresar todo el historial de una serie temporal de una vez al modelo, debido a las restricciones de tiempo y memoria del mecanismo de atención. Por lo tanto, se puede considerar alguna ventana de contexto apropiada y muestrear esta ventana y la ventana de longitud de predicción subsiguiente de los datos de entrenamiento al construir lotes para el descenso de gradiente estocástico (SGD). La ventana de tamaño de contexto se puede pasar al codificador y la ventana de predicción al decodificador con máscara causal. Esto significa que el decodificador solo puede mirar pasos de tiempo anteriores al aprender el siguiente valor. Esto es equivalente a cómo se entrenaría un Transformador básico para la traducción de máquina, conocido como “forzamiento del maestro” (teacher forcing en inglés).
Otra ventaja de los Transformadores sobre las otras arquitecturas es que podemos incorporar valores faltantes (que son comunes en el entorno de series temporales) como una máscara adicional al codificador o decodificador y aún entrenar sin recurrir al relleno o imputación. Esto es equivalente a la attention_mask de modelos como BERT y GPT-2 en la biblioteca Transformers, para no incluir tokens de relleno en el cálculo de la matriz de atención.
Una desventaja de la arquitectura Transformer es el límite en el tamaño del contexto y las ventanas de predicción debido a los requisitos computacionales y de memoria cuadráticos del Transformer básico, ver Tay et al., 2020. Además, dado que el Transformer es una arquitectura potente, podría sobreajustar o aprender correlaciones espurias con mayor facilidad en comparación con otros métodos.
La biblioteca 🤗 Transformers viene con un modelo Transformer de series de tiempo probabilístico básico, simplemente llamado Time Series Transformer. En las secciones siguientes, mostraremos cómo entrenar dicho modelo en un conjunto de datos personalizado.
Configurar el entorno
Primero, instalemos las bibliotecas necesarias: 🤗 Transformers, 🤗 Datasets, 🤗 Evaluate, 🤗 Accelerate y GluonTS.
Como mostraremos, GluonTS se utilizará para transformar los datos y crear características, así como para crear lotes de entrenamiento, validación y prueba adecuados.
!pip install -q transformers
!pip install -q datasets
!pip install -q evaluate
!pip install -q accelerate
!pip install -q gluonts ujsonCargar conjunto de datos
En esta publicación de blog, utilizaremos el conjunto de datos tourism_monthly, que está disponible en el Hugging Face Hub. Este conjunto de datos contiene volúmenes de turismo mensuales para 366 regiones en Australia.
Este conjunto de datos es parte del repositorio de pronóstico de series de tiempo de Monash, una colección de conjuntos de datos de series de tiempo de varios dominios. Se puede ver como el punto de referencia GLUE para el pronóstico de series de tiempo.
from datasets import load_dataset
dataset = load_dataset("monash_tsf", "tourism_monthly")Como se puede ver, el conjunto de datos contiene 3 divisiones: entrenamiento, validación y prueba.
dataset
>>> DatasetDict({
train: Dataset({
features: ['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'],
num_rows: 366
})
test: Dataset({
features: ['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'],
num_rows: 366
})
validation: Dataset({
features: ['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'],
num_rows: 366
})
})Cada ejemplo contiene algunas claves, de las cuales start y target son las más importantes. Echemos un vistazo a la primera serie de tiempo en el conjunto de datos:
train_example = dataset['train'][0]
train_example.keys()
>>> dict_keys(['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'])El start indica simplemente el comienzo de la serie de tiempo (como una fecha y hora), y el target contiene los valores reales de la serie de tiempo.
El start será útil para agregar características relacionadas con el tiempo a los valores de la serie de tiempo, como entrada adicional al modelo (como “mes del año”). Dado que conocemos la frecuencia de los datos, que es mensual, sabemos, por ejemplo, que el segundo valor tiene la marca de tiempo 1979-02-01, etc.
print(train_example['start'])
print(train_example['target'])
>>> 1979-01-01 00:00:00
[1149.8699951171875, 1053.8001708984375, ..., 5772.876953125]El conjunto de validación contiene los mismos datos que el conjunto de entrenamiento, solo que para un período de tiempo más largo determinado por prediction_length. Esto nos permite validar las predicciones del modelo con respecto a los datos reales.
El conjunto de prueba es nuevamente un conjunto de datos más largo en prediction_length en comparación con el conjunto de validación (o múltiplos de prediction_length más largo en comparación con el conjunto de entrenamiento para probar en múltiples ventanas deslizantes).
validation_example = dataset['validation'][0]
validation_example.keys()
>>> dict_keys(['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'])Los valores iniciales son exactamente los mismos que en el ejemplo de entrenamiento correspondiente:
print(validation_example['start'])
print(validation_example['target'])
>>> 1979-01-01 00:00:00
[1149.8699951171875, 1053.8001708984375, ..., 5985.830078125]Sin embargo, este ejemplo tiene prediction_length=24 valores adicionales en comparación con el ejemplo de entrenamiento. Verifiquemos esto.
freq = "1M"
prediction_length = 24
assert len(train_example["target"]) + prediction_length == len(
validation_example["target"]
)Visualicemos esto:
import matplotlib.pyplot as plt
figure, axes = plt.subplots()
axes.plot(train_example["target"], color="blue")
axes.plot(validation_example["target"], color="red", alpha=0.5)
plt.show()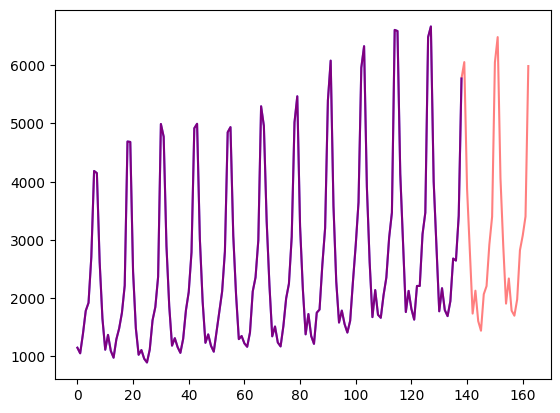
Dividamos los datos:
train_dataset = dataset["train"]
test_dataset = dataset["test"]Actualiza start a pd.Period
Lo primero que haremos es convertir la característica start de cada serie de tiempo a un índice de pandas Period usando la frecuencia de los datos (freq):
from functools import lru_cache
import pandas as pd
import numpy as np
@lru_cache(10_000)
def convert_to_pandas_period(date, freq):
return pd.Period(date, freq)
def transform_start_field(batch, freq):
batch["start"] = [convert_to_pandas_period(date, freq) for date in batch["start"]]
return batchAhora utilizamos la funcionalidad set_transform de datasets para hacer esto sobre la marcha en su lugar:
from functools import partial
train_dataset.set_transform(partial(transform_start_field, freq=freq))
test_dataset.set_transform(partial(transform_start_field, freq=freq))Define el Modelo
A continuación, instanciemos un modelo. El modelo será entrenado desde cero, por lo tanto, no utilizaremos el método from_pretrained aquí, sino que inicializaremos el modelo aleatoriamente desde una config.
Especificamos un par de parámetros adicionales para el modelo:
prediction_length(en nuestro caso,24meses): este es el horizonte que el decodificador del Transformer aprenderá a predecir;context_length: el modelo establecerá elcontext_length(entrada del codificador) igual aprediction_length, si no se especifica uncontext_length;lagspara una frecuencia determinada: esto especifica cuánto “miramos hacia atrás”, para agregar como características adicionales. Por ejemplo, para una frecuenciaDailypodríamos considerar un mirar hacia atrás de[1, 2, 7, 30, ...], es decir, mirar hacia atrás 1, 2, … días, mientras que para datosMinutepodríamos considerar[1, 30, 60, 60*24, ...], etc.;- el número de características de tiempo: en nuestro caso, esto será
2, ya que agregaremos características deMonthOfYearyAge; - el número de características categóricas estáticas: en nuestro caso, esto será solo
1, ya que agregaremos una sola característica de “ID de serie de tiempo”; - la cardinalidad: el número de valores de cada característica categórica estática, como una lista que en nuestro caso será
[366], ya que tenemos 366 series de tiempo diferentes; - la dimensión de incrustación: la dimensión de incrustación para cada característica categórica estática, como una lista, por ejemplo
[3]significa que el modelo aprenderá un vector de incrustación de tamaño3para cada una de las366series de tiempo (regiones).
Utilicemos los desfases predeterminados proporcionados por GluonTS para la frecuencia dada (“mensual”):
from gluonts.time_feature import get_lags_for_frequency
lags_sequence = get_lags_for_frequency(freq)
print(lags_sequence)
>>> [1, 2, 3, 4, 5, 6, 7, 11, 12, 13, 23, 24, 25, 35, 36, 37]Esto significa que retrocederemos hasta 37 meses para cada paso de tiempo, como características adicionales.
También verifiquemos las características de tiempo predeterminadas que GluonTS nos proporciona:
from gluonts.time_feature import time_features_from_frequency_str
time_features = time_features_from_frequency_str(freq)
print(time_features)
>>> [<function month_of_year at 0x7fa496d0ca70>]En este caso, solo hay una única característica, es decir, “mes del año”. Esto significa que para cada paso de tiempo, agregaremos el mes como un valor escalar (por ejemplo, 1 en caso de que la marca de tiempo sea “enero”, 2 en caso de que la marca de tiempo sea “febrero”, etc.).
Ahora tenemos todo lo necesario para definir el modelo:
from transformers import TimeSeriesTransformerConfig, TimeSeriesTransformerForPrediction
config = TimeSeriesTransformerConfig(
prediction_length=prediction_length,
# longitud del contexto:
context_length=prediction_length * 2,
# desfases proporcionados por el ayudante dada la frecuencia:
lags_sequence=lags_sequence,
# agregaremos 2 características de tiempo ("mes del año" y "edad", ver más adelante):
num_time_features=len(time_features) + 1,
# tenemos una única característica categórica estática, es decir, la identificación de la serie temporal:
num_static_categorical_features=1,
# hay 366 valores posibles:
cardinality=[len(train_dataset)],
# el modelo aprenderá una incrustación de tamaño 2 para cada uno de los 366 valores posibles:
embedding_dimension=[2],
# parámetros del transformador:
encoder_layers=4,
decoder_layers=4,
d_model=32,
)
model = TimeSeriesTransformerForPrediction(config)Nótese que, al igual que otros modelos en la biblioteca 🤗 Transformers, TimeSeriesTransformerModel corresponde al codificador-decodificador Transformer sin ninguna capa superior, y TimeSeriesTransformerForPrediction corresponde a TimeSeriesTransformerModel con una capa de distribución en la parte superior. De forma predeterminada, el modelo utiliza una distribución t de Student (pero esto es configurable):
model.config.distribution_output
>>> student_tEsta es una diferencia importante con los Transformers para NLP, donde la capa típicamente consiste en una distribución categórica fija implementada como una capa nn.Linear.
Definir Transformaciones
A continuación, definimos las transformaciones para los datos, en particular para la creación de las características de tiempo (basadas en el conjunto de datos o en características universales).
Nuevamente, utilizaremos la biblioteca GluonTS para esto. Definimos una Chain de transformaciones (que es un poco comparable a torchvision.transforms.Compose para imágenes). Nos permite combinar varias transformaciones en un solo pipeline.
from gluonts.time_feature import (
time_features_from_frequency_str,
TimeFeature,
get_lags_for_frequency,
)
from gluonts.dataset.field_names import FieldName
from gluonts.transform import (
AddAgeFeature,
AddObservedValuesIndicator,
AddTimeFeatures,
AsNumpyArray,
Chain,
ExpectedNumInstanceSampler,
InstanceSplitter,
RemoveFields,
SelectFields,
SetField,
TestSplitSampler,
Transformation,
ValidationSplitSampler,
VstackFeatures,
RenameFields,
)Las transformaciones a continuación están anotadas con comentarios para explicar qué hacen. En términos generales, iteraremos sobre las series de tiempo individuales de nuestro conjunto de datos y agregaremos/eliminaremos campos o características:
from transformers import PretrainedConfig
def create_transformation(freq: str, config: PretrainedConfig) -> Transformation:
remove_field_names = []
if config.num_static_real_features == 0:
remove_field_names.append(FieldName.FEAT_STATIC_REAL)
if config.num_dynamic_real_features == 0:
remove_field_names.append(FieldName.FEAT_DYNAMIC_REAL)
if config.num_static_categorical_features == 0:
remove_field_names.append(FieldName.FEAT_STATIC_CAT)
# algo similar a torchvision.transforms.Compose
return Chain(
# paso 1: eliminar campos estáticos/dinámicos si no se especifican
[RemoveFields(field_names=remove_field_names)]
# paso 2: convertir los datos a NumPy (potencialmente no necesario)
+ (
[
AsNumpyArray(
field=FieldName.FEAT_STATIC_CAT,
expected_ndim=1,
dtype=int,
)
]
if config.num_static_categorical_features > 0
else []
)
+ (
[
AsNumpyArray(
field=FieldName.FEAT_STATIC_REAL,
expected_ndim=1,
)
]
if config.num_static_real_features > 0
else []
)
+ [
AsNumpyArray(
field=FieldName.TARGET,
# esperamos una dimensión adicional para el caso multivariado:
expected_ndim=1 if config.input_size == 1 else 2,
),
# paso 3: manejar los NaN's llenando el objetivo con cero
# y devolver la máscara (que está en los valores observados)
# verdadero para valores observados, falso para NaN's
# el decodificador utiliza esta máscara (no se incurre en pérdida para valores no observados)
# ver loss_weights dentro del modelo xxxForPrediction
AddObservedValuesIndicator(
target_field=FieldName.TARGET,
output_field=FieldName.OBSERVED_VALUES,
),
# paso 4: agregar características temporales según la frecuencia del conjunto de datos
# mes del año en el caso en que freq="M"
# estas sirven como codificaciones posicionales
AddTimeFeatures(
start_field=FieldName.START,
target_field=FieldName.TARGET,
output_field=FieldName.FEAT_TIME,
time_features=time_features_from_frequency_str(freq),
pred_length=config.prediction_length,
),
# paso 5: agregar otra característica temporal (solo un número)
# indica al modelo dónde se encuentra en su vida el valor de la serie temporal,
# una especie de contador en funcionamiento
AddAgeFeature(
target_field=FieldName.TARGET,
output_field=FieldName.FEAT_AGE,
pred_length=config.prediction_length,
log_scale=True,
),
# paso 6: apilar verticalmente todas las características temporales en la clave FEAT_TIME
VstackFeatures(
output_field=FieldName.FEAT_TIME,
input_fields=[FieldName.FEAT_TIME, FieldName.FEAT_AGE]
+ (
[FieldName.FEAT_DYNAMIC_REAL]
if config.num_dynamic_real_features > 0
else []
),
),
# paso 7: renombrar para que coincida con los nombres de HuggingFace
RenameFields(
mapping={
FieldName.FEAT_STATIC_CAT: "static_categorical_features",
FieldName.FEAT_STATIC_REAL: "static_real_features",
FieldName.FEAT_TIME: "time_features",
FieldName.TARGET: "values",
FieldName.OBSERVED_VALUES: "observed_mask",
}
),
]
)Define InstanceSplitter
Para el entrenamiento/validación/prueba, a continuación creamos un InstanceSplitter que se utiliza para muestrear ventanas del conjunto de datos (ya que, recuerde, no podemos pasar todo el historial de valores al Transformer debido a restricciones de tiempo y memoria).
El instance splitter muestrea ventanas de tamaño aleatorio de context_length y de tamaño siguiente de prediction_length a partir de los datos y agrega una clave past_ o future_ a cualquier clave temporal para las ventanas respectivas. Esto asegura que los values se dividirán en las claves past_values y future_values, que servirán como las entradas del codificador y del decodificador respectivamente. Lo mismo ocurre con cualquier clave en el argumento time_series_fields:
from gluonts.transform.sampler import InstanceSampler
from typing import Optional
def create_instance_splitter(
config: PretrainedConfig,
mode: str,
train_sampler: Optional[InstanceSampler] = None,
validation_sampler: Optional[InstanceSampler] = None,
) -> Transformation:
assert mode in ["train", "validation", "test"]
instance_sampler = {
"train": train_sampler
or ExpectedNumInstanceSampler(
num_instances=1.0, min_future=config.prediction_length
),
"validation": validation_sampler
or ValidationSplitSampler(min_future=config.prediction_length),
"test": TestSplitSampler(),
}[mode]
return InstanceSplitter(
target_field="values",
is_pad_field=FieldName.IS_PAD,
start_field=FieldName.START,
forecast_start_field=FieldName.FORECAST_START,
instance_sampler=instance_sampler,
past_length=config.context_length + max(config.lags_sequence),
future_length=config.prediction_length,
time_series_fields=["time_features", "observed_mask"],
)Crear DataLoaders
A continuación, es hora de crear los DataLoaders, que nos permiten tener lotes de pares (entrada, salida) – o en otras palabras (past_values, future_values).
from typing import Iterable
import torch
from gluonts.itertools import Cached, Cyclic
from gluonts.dataset.loader import as_stacked_batches
def create_train_dataloader(
config: PretrainedConfig,
freq,
data,
batch_size: int,
num_batches_per_epoch: int,
shuffle_buffer_length: Optional[int] = None,
cache_data: bool = True,
**kwargs,
) -> Iterable:
PREDICTION_INPUT_NAMES = [
"past_time_features",
"past_values",
"past_observed_mask",
"future_time_features",
]
if config.num_static_categorical_features > 0:
PREDICTION_INPUT_NAMES.append("static_categorical_features")
if config.num_static_real_features > 0:
PREDICTION_INPUT_NAMES.append("static_real_features")
TRAINING_INPUT_NAMES = PREDICTION_INPUT_NAMES + [
"future_values",
"future_observed_mask",
]
transformation = create_transformation(freq, config)
transformed_data = transformation.apply(data, is_train=True)
if cache_data:
transformed_data = Cached(transformed_data)
# inicializamos una instancia de Training
instance_splitter = create_instance_splitter(config, "train")
# el instance splitter muestreará una ventana de longitud de contexto + lags + longitud de predicción
# (de las 366 posibles series de tiempo transformadas)
# de manera aleatoria desde la serie de tiempo objetivo y devolverá un iterador.
stream = Cyclic(transformed_data).stream()
training_instances = instance_splitter.apply(
stream, is_train=True
)
return as_stacked_batches(
training_instances,
batch_size=batch_size,
shuffle_buffer_length=shuffle_buffer_length,
field_names=TRAINING_INPUT_NAMES,
output_type=torch.tensor,
num_batches_per_epoch=num_batches_per_epoch,
)
def create_test_dataloader(
config: PretrainedConfig,
freq,
data,
batch_size: int,
**kwargs,
):
PREDICTION_INPUT_NAMES = [
"past_time_features",
"past_values",
"past_observed_mask",
"future_time_features",
]
if config.num_static_categorical_features > 0:
PREDICTION_INPUT_NAMES.append("static_categorical_features")
if config.num_static_real_features > 0:
PREDICTION_INPUT_NAMES.append("static_real_features")
transformation = create_transformation(freq, config)
transformed_data = transformation.apply(data, is_train=False)
# creamos un Test Instance splitter que muestreará la última ventana de contexto vista durante el entrenamiento solo para el codificador.
instance_sampler = create_instance_splitter(config, "test")
# aplicamos las transformaciones en modo de prueba
testing_instances = instance_sampler.apply(transformed_data, is_train=False)
return as_stacked_batches(
testing_instances,
batch_size=batch_size,
output_type=torch.tensor,
field_names=PREDICTION_INPUT_NAMES,
)
train_dataloader = create_train_dataloader(
config=config,
freq=freq,
data=train_dataset,
batch_size=256,
num_batches_per_epoch=100,
)
test_dataloader = create_test_dataloader(
config=config,
freq=freq,
data=test_dataset,
batch_size=64,
)Vamos a verificar el primer lote:
lote = next(iter(train_dataloader))
for k, v in lote.items():
print(k, v.shape, v.type())
>>> past_time_features torch.Size([256, 85, 2]) torch.FloatTensor
past_values torch.Size([256, 85]) torch.FloatTensor
past_observed_mask torch.Size([256, 85]) torch.FloatTensor
future_time_features torch.Size([256, 24, 2]) torch.FloatTensor
static_categorical_features torch.Size([256, 1]) torch.LongTensor
future_values torch.Size([256, 24]) torch.FloatTensor
future_observed_mask torch.Size([256, 24]) torch.FloatTensorComo se puede ver, no alimentamos input_ids y attention_mask al codificador (como sería el caso de los modelos de NLP), sino past_values, junto con past_observed_mask, past_time_features y static_categorical_features.
Las entradas del decodificador consisten en future_values, future_observed_mask y future_time_features. Los future_values se pueden ver como el equivalente de decoder_input_ids en NLP.
Consulte la documentación para obtener una explicación detallada de cada uno de ellos.
Pase hacia adelante
Vamos a realizar un solo pase hacia adelante con el lote que acabamos de crear:
# realizar pase hacia adelante
salidas = modelo(
past_values=lote["past_values"],
past_time_features=lote["past_time_features"],
past_observed_mask=lote["past_observed_mask"],
static_categorical_features=lote["static_categorical_features"]
if config.num_static_categorical_features > 0
else None,
static_real_features=lote["static_real_features"]
if config.num_static_real_features > 0
else None,
future_values=lote["future_values"],
future_time_features=lote["future_time_features"],
future_observed_mask=lote["future_observed_mask"],
output_hidden_states=True,
)
print("Pérdida:", salidas.loss.item())
>>> Pérdida: 9.069628715515137Tenga en cuenta que el modelo está devolviendo una pérdida. Esto es posible ya que el decodificador desplaza automáticamente los future_values una posición a la derecha para tener las etiquetas. Esto permite calcular una pérdida entre los valores predichos y las etiquetas.
También tenga en cuenta que el decodificador utiliza una máscara causal para no mirar hacia el futuro, ya que los valores que necesita predecir están en el tensor future_values.
Entrenar el modelo
¡Es hora de entrenar el modelo! Utilizaremos un bucle de entrenamiento estándar de PyTorch.
Aquí utilizaremos la biblioteca 🤗 Accelerate, que coloca automáticamente el modelo, el optimizador y el dataloader en el device apropiado.
from accelerate import Accelerator
from torch.optim import AdamW
acelerador = Accelerator()
device = acelerador.device
modelo.to(device)
optimizador = AdamW(modelo.parameters(), lr=6e-4, betas=(0.9, 0.95), weight_decay=1e-1)
modelo, optimizador, train_dataloader = acelerador.prepare(
modelo,
optimizador,
train_dataloader,
)
modelo.train()
for epoch in range(40):
for idx, lote in enumerate(train_dataloader):
optimizador.zero_grad()
salidas = modelo(
static_categorical_features=lote["static_categorical_features"].to(device)
if config.num_static_categorical_features > 0
else None,
static_real_features=lote["static_real_features"].to(device)
if config.num_static_real_features > 0
else None,
past_time_features=lote["past_time_features"].to(device),
past_values=lote["past_values"].to(device),
future_time_features=lote["future_time_features"].to(device),
future_values=lote["future_values"].to(device),
past_observed_mask=lote["past_observed_mask"].to(device),
future_observed_mask=lote["future_observed_mask"].to(device),
)
pérdida = salidas.loss
# Retropropagación
acelerador.backward(pérdida)
optimizador.step()
if idx % 100 == 0:
print(pérdida.item())Inferencia
En el momento de la inferencia, se recomienda utilizar el método generate() para la generación autoregresiva, similar a los modelos de procesamiento del lenguaje natural (NLP).
La predicción implica obtener datos del muestreador de instancias de prueba, que muestreará la última ventana de tamaño context_length de valores de cada serie temporal en el conjunto de datos, y pasarla al modelo. Tenga en cuenta que pasamos future_time_features, que se conocen de antemano, al decodificador.
El modelo muestreará autoregresivamente un cierto número de valores de la distribución predicha y los devolverá al decodificador para obtener las salidas de predicción:
model.eval()
forecasts = []
for batch in test_dataloader:
outputs = model.generate(
static_categorical_features=batch["static_categorical_features"].to(device)
if config.num_static_categorical_features > 0
else None,
static_real_features=batch["static_real_features"].to(device)
if config.num_static_real_features > 0
else None,
past_time_features=batch["past_time_features"].to(device),
past_values=batch["past_values"].to(device),
future_time_features=batch["future_time_features"].to(device),
past_observed_mask=batch["past_observed_mask"].to(device),
)
forecasts.append(outputs.sequences.cpu().numpy())El modelo devuelve un tensor de forma ( tamaño_lote , número_de_muestras , longitud_predicción ).
En este caso, obtenemos 100 posibles valores para los próximos 24 meses (para cada ejemplo en el lote, que tiene un tamaño de 64 ):
forecasts[0].shape
>>> (64, 100, 24)Los apilaremos verticalmente para obtener las predicciones de todas las series de tiempo en el conjunto de datos de prueba:
forecasts = np.vstack(forecasts)
print(forecasts.shape)
>>> (366, 100, 24)Podemos evaluar la predicción resultante con respecto a los valores fuera de muestra del conjunto de prueba. Utilizaremos las métricas MASE y sMAPE, que calculamos para cada serie de tiempo en el conjunto de datos:
from evaluate import load
from gluonts.time_feature import get_seasonality
mase_metric = load("evaluate-metric/mase")
smape_metric = load("evaluate-metric/smape")
forecast_median = np.median(forecasts, 1)
mase_metrics = []
smape_metrics = []
for item_id, ts in enumerate(test_dataset):
training_data = ts["target"][:-prediction_length]
ground_truth = ts["target"][-prediction_length:]
mase = mase_metric.compute(
predictions=forecast_median[item_id],
references=np.array(ground_truth),
training=np.array(training_data),
periodicity=get_seasonality(freq))
mase_metrics.append(mase["mase"])
smape = smape_metric.compute(
predictions=forecast_median[item_id],
references=np.array(ground_truth),
)
smape_metrics.append(smape["smape"])
print(f"MASE: {np.mean(mase_metrics)}")
>>> MASE: 1.2564196892177717
print(f"sMAPE: {np.mean(smape_metrics)}")
>>> sMAPE: 0.1609541520852549También podemos trazar las métricas individuales de cada serie de tiempo en el conjunto de datos y observar que algunas series de tiempo contribuyen mucho a la métrica de prueba final:
plt.scatter(mase_metrics, smape_metrics, alpha=0.3)
plt.xlabel("MASE")
plt.ylabel("sMAPE")
plt.show()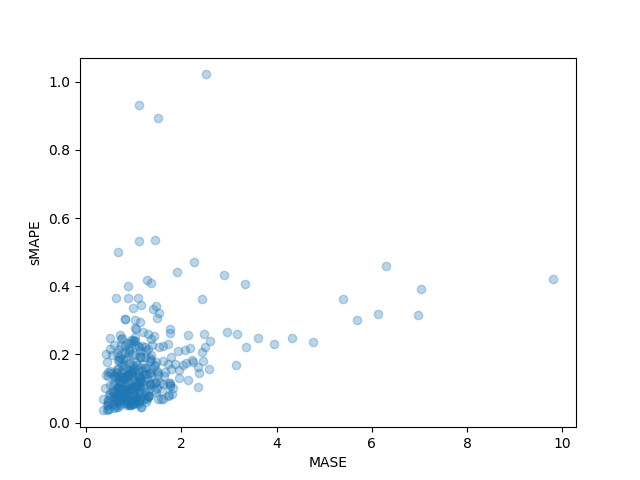
Para trazar la predicción para cualquier serie de tiempo con respecto a los datos de prueba de verdad fundamental, definimos el siguiente helper:
import matplotlib.dates as mdates
def plot(ts_index):
fig, ax = plt.subplots()
index = pd.period_range(
start=test_dataset[ts_index][FieldName.START],
periods=len(test_dataset[ts_index][FieldName.TARGET]),
freq=freq,
).to_timestamp()
# Mayor ticks cada medio año, minor ticks cada mes,
ax.xaxis.set_major_locator(mdates.MonthLocator(bymonth=(1, 7)))
ax.xaxis.set_minor_locator(mdates.MonthLocator())
ax.plot(
index[-2*prediction_length:],
test_dataset[ts_index]["target"][-2*prediction_length:],
label="actual",
)
plt.plot(
index[-prediction_length:],
np.median(forecasts[ts_index], axis=0),
label="median",
)
plt.fill_between(
index[-prediction_length:],
forecasts[ts_index].mean(0) - forecasts[ts_index].std(axis=0),
forecasts[ts_index].mean(0) + forecasts[ts_index].std(axis=0),
alpha=0.3,
interpolate=True,
label="+/- 1-std",
)
plt.legend()
plt.show()Por ejemplo:
plot(334)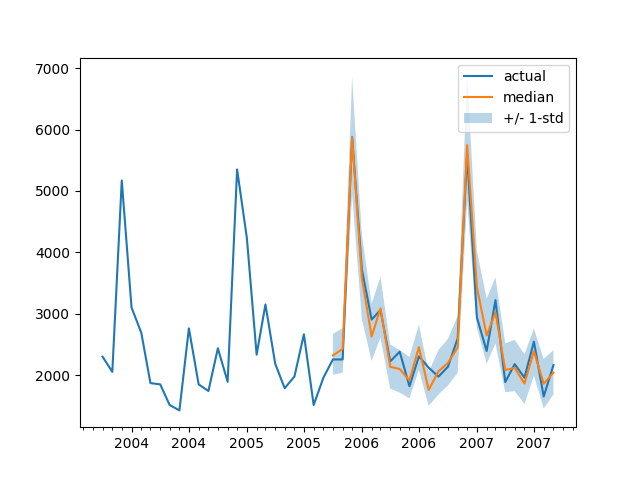
¿Cómo nos comparamos con otros modelos? El Repositorio de Series de Tiempo de Monash tiene una tabla de comparación de métricas MASE en el conjunto de pruebas que podemos agregar:
Tenga en cuenta que, con nuestro modelo, estamos superando a todos los demás modelos informados (consulte también la tabla 2 en el documento correspondiente) y no hicimos ninguna sintonización de hiperparámetros. Simplemente entrenamos el Transformer durante 40 épocas.
Por supuesto, debemos tener cuidado al afirmar simplemente resultados de vanguardia en series de tiempo con redes neuronales, ya que parece que “XGBoost es todo lo que necesitas”. Solo estamos muy curiosos por ver hasta dónde pueden llevarnos las redes neuronales y si los Transformers serán útiles en este ámbito. Este conjunto de datos en particular parece indicar que definitivamente vale la pena explorarlo.
Siguientes pasos
Animamos a los lectores a probar el cuaderno con otros conjuntos de datos de series de tiempo del Hub y reemplazar los parámetros adecuados de frecuencia y longitud de predicción. Para sus conjuntos de datos, sería necesario convertirlos a la convención utilizada por GluonTS, que se explica muy bien en su documentación aquí. También hemos preparado un cuaderno de ejemplo que muestra cómo convertir su conjunto de datos al formato de 🤗 datasets aquí.
Como sabrán los investigadores de series de tiempo, ha habido mucho interés en aplicar modelos basados en Transformers al problema de las series de tiempo. El Transformer básico es solo uno de los muchos modelos basados en atención, por lo que es necesario agregar más modelos a la biblioteca.
Actualmente, nada nos impide modelar series de tiempo multivariadas, sin embargo, para eso sería necesario instanciar el modelo con una cabeza de distribución multivariada. Actualmente se admiten distribuciones independientes diagonales y se agregarán otras distribuciones multivariadas. Estén atentos a una futura publicación en el blog que incluirá un tutorial.
Otra cosa en el plan de desarrollo es la clasificación de series de tiempo. Esto implica agregar un modelo de series de tiempo con una cabeza de clasificación a la biblioteca, por ejemplo, para la detección de anomalías.
El modelo actual asume la presencia de una fecha y hora junto con los valores de la serie de tiempo, lo cual puede no ser el caso para todas las series de tiempo en la naturaleza. Vea, por ejemplo, conjuntos de datos de neurociencia como el de WOODS. Por lo tanto, sería necesario generalizar el modelo actual para hacer que algunas entradas sean opcionales en toda la cadena de procesamiento.
Finalmente, el dominio de NLP/Vision ha beneficiado enormemente de los modelos pre-entrenados grandes, mientras que esto no es el caso en lo que sabemos para el dominio de las series de tiempo. Los modelos basados en Transformers parecen la elección obvia para seguir esta línea de investigación y ¡no podemos esperar a ver qué descubren los investigadores y profesionales!
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Una Guía Completa de Conjuntos de Datos de Audio
- ¡Hablemos de sesgos en el aprendizaje automático! Boletín de Ética y Sociedad #2
- Segmentación de imágenes sin entrenamiento previo con CLIPSeg
- Introducción al Aprendizaje de Máquina en Grafos
- ¿Qué hace útil a un agente de diálogo?
- Optimum+ONNX Runtime Entrenamiento más fácil y rápido para tus modelos de Hugging Face
- El estado de la Visión por Computadora en Hugging Face 🤗






