Anunciando el primer Desafío de Desaprendizaje Automático
'Primer Desafío de Desaprendizaje Automático anunciado'
Publicado por Fabián Pedregosa y Eleni Triantafillou, Científicos Investigadores de Google
El aprendizaje profundo ha impulsado recientemente un tremendo progreso en una amplia gama de aplicaciones, desde la generación realista de imágenes y sistemas impresionantes de búsqueda, hasta modelos de lenguaje capaces de mantener conversaciones similares a las humanas. Si bien este progreso es muy emocionante, el uso generalizado de modelos de redes neuronales profundas requiere precaución: siguiendo los Principios de IA de Google, buscamos desarrollar tecnologías de IA de manera responsable comprendiendo y mitigando riesgos potenciales, como la propagación y amplificación de sesgos injustos y la protección de la privacidad del usuario.
Eliminar por completo la influencia de los datos que se solicita eliminar es un desafío, ya que, además de eliminarlos de las bases de datos donde se almacenan, también requiere eliminar la influencia de esos datos en otros artefactos, como modelos de aprendizaje automático entrenados. Además, investigaciones recientes [1, 2] han demostrado que en algunos casos es posible inferir con alta precisión si se utilizó un ejemplo para entrenar un modelo de aprendizaje automático mediante ataques de inferencia de membresía (MIAs). Esto puede plantear preocupaciones de privacidad, ya que implica que, incluso si los datos de un individuo se eliminan de una base de datos, aún puede ser posible inferir si esos datos se utilizaron para entrenar un modelo.
Dado lo anterior, el desaprendizaje automático es un subcampo emergente del aprendizaje automático que tiene como objetivo eliminar la influencia de un subconjunto específico de ejemplos de entrenamiento, conocido como “conjunto de olvido”, de un modelo entrenado. Además, un algoritmo de desaprendizaje ideal eliminaría la influencia de ciertos ejemplos mientras mantiene otras propiedades beneficiosas, como la precisión en el resto del conjunto de entrenamiento y la generalización a ejemplos reservados. Una forma sencilla de producir este modelo desaprendido es volver a entrenar el modelo en un conjunto de entrenamiento ajustado que excluya las muestras del conjunto de olvido. Sin embargo, esto no siempre es una opción viable, ya que el entrenamiento nuevamente de modelos profundos puede ser computacionalmente costoso. Un algoritmo de desaprendizaje ideal utilizaría en su lugar el modelo ya entrenado como punto de partida y realizaría ajustes de manera eficiente para eliminar la influencia de los datos solicitados.
- ‘Mi aplicación 3D favorita’ Fanático de Blender comparte su escena inspirada en Japón esta semana ‘En el NVIDIA Studio’
- 10 millones se registran en la aplicación rival de Twitter de Meta, Threads.
- Las ventas de automóviles nuevos despegan a medida que se alivia la escasez de chips.
Hoy nos complace anunciar que nos hemos asociado con un amplio grupo de investigadores académicos e industriales para organizar el primer Desafío de Desaprendizaje Automático. La competencia considera un escenario realista en el que, después del entrenamiento, se deben olvidar ciertos subconjuntos de imágenes de entrenamiento para proteger la privacidad o los derechos de las personas involucradas. La competencia se llevará a cabo en Kaggle y las presentaciones serán evaluadas automáticamente en términos de calidad de olvido y utilidad del modelo. Esperamos que esta competencia ayude a avanzar en el estado del arte en el desaprendizaje automático y fomente el desarrollo de algoritmos de desaprendizaje eficientes, efectivos y éticos.
Aplicaciones del desaprendizaje automático
El desaprendizaje automático tiene aplicaciones más allá de la protección de la privacidad del usuario. Por ejemplo, se puede utilizar el desaprendizaje para eliminar información inexacta o desactualizada de los modelos entrenados (por ejemplo, debido a errores en la etiquetación o cambios en el entorno) o eliminar datos dañinos, manipulados o atípicos.
El campo del desaprendizaje automático está relacionado con otras áreas del aprendizaje automático, como la privacidad diferencial, el aprendizaje de por vida y la equidad. La privacidad diferencial tiene como objetivo garantizar que ningún ejemplo de entrenamiento en particular tenga demasiada influencia en el modelo entrenado; una meta más fuerte en comparación con la del desaprendizaje, que solo requiere eliminar la influencia del conjunto de olvido designado. La investigación sobre el aprendizaje de por vida tiene como objetivo diseñar modelos que puedan aprender de manera continua mientras mantienen habilidades adquiridas previamente. A medida que avanza el trabajo sobre el desaprendizaje, también puede abrir formas adicionales de promover la equidad en los modelos, corrigiendo sesgos injustos o tratamiento dispar de miembros pertenecientes a diferentes grupos (por ejemplo, demográficos, grupos de edad, etc.).
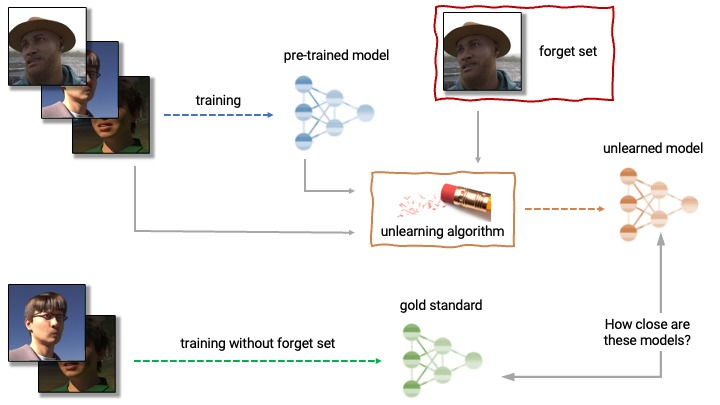 |
| Anatomía del desaprendizaje. Un algoritmo de desaprendizaje toma como entrada un modelo preentrenado y uno o más ejemplos del conjunto de entrenamiento para desaprender (el “conjunto de olvido”). A partir del modelo, el conjunto de olvido y el conjunto de retención, el algoritmo de desaprendizaje produce un modelo actualizado. Un algoritmo de desaprendizaje ideal produce un modelo que es indistinguible del modelo entrenado sin el conjunto de olvido. |
Desafíos del olvido en las máquinas
El problema del olvido es complejo y multifacético, ya que implica varios objetivos conflictivos: olvidar los datos solicitados, mantener la utilidad del modelo (por ejemplo, precisión en los datos retenidos y no vistos) y eficiencia. Debido a esto, los algoritmos existentes de olvido hacen diferentes compromisos. Por ejemplo, la reentrenamiento completo logra un olvido exitoso sin dañar la utilidad del modelo, pero con poca eficiencia, mientras que agregar ruido a los pesos logra el olvido a expensas de la utilidad.
Además, la evaluación de los algoritmos de olvido en la literatura ha sido hasta ahora muy inconsistente. Mientras algunos trabajos informan la precisión de clasificación en las muestras a olvidar, otros informan la distancia al modelo completamente reentrenado, y otros utilizan la tasa de error de los ataques de inferencia de membresía como métrica de calidad del olvido [4, 5, 6].
Creemos que la inconsistencia de las métricas de evaluación y la falta de un protocolo estandarizado son un serio impedimento para el progreso en el campo; no podemos hacer comparaciones directas entre los diferentes métodos de olvido en la literatura. Esto nos deja con una visión miope de los méritos relativos y las desventajas de diferentes enfoques, así como desafíos abiertos y oportunidades para desarrollar algoritmos mejorados. Para abordar el problema de la evaluación inconsistente y avanzar en el estado del arte en el campo del olvido en las máquinas, nos hemos unido a un amplio grupo de investigadores académicos e industriales para organizar el primer desafío de olvido.
Anunciando el primer Desafío de Olvido en las Máquinas
Nos complace anunciar el primer Desafío de Olvido en las Máquinas, que se llevará a cabo como parte de la Competencia Track de NeurIPS 2023. El objetivo de la competencia es doble. En primer lugar, al unificar y estandarizar las métricas de evaluación para el olvido, esperamos identificar las fortalezas y debilidades de diferentes algoritmos a través de comparaciones equitativas. En segundo lugar, al abrir esta competencia a todos, esperamos fomentar soluciones novedosas y arrojar luz sobre los desafíos abiertos y las oportunidades.
La competencia se llevará a cabo en Kaggle y se llevará a cabo entre mediados de julio de 2023 y mediados de septiembre de 2023. Como parte de la competencia, hoy anunciamos la disponibilidad del kit de inicio. Este kit de inicio proporciona una base para que los participantes construyan y prueben sus modelos de olvido en un conjunto de datos de juguete.
La competencia considera un escenario realista en el que se ha entrenado un predictor de edad en imágenes faciales y, después del entrenamiento, cierto subconjunto de las imágenes de entrenamiento debe olvidarse para proteger la privacidad o los derechos de las personas involucradas. Para esto, pondremos a disposición como parte del kit de inicio un conjunto de datos de rostros sintéticos (muestras que se muestran a continuación) y también utilizaremos varios conjuntos de datos de rostros reales para la evaluación de las presentaciones. Se solicita a los participantes que envíen código que tome como entrada el predictor entrenado, los conjuntos de olvido y retención, y produzca los pesos de un predictor que haya olvidado el conjunto de olvido designado. Evaluaremos las presentaciones en función tanto de la fortaleza del algoritmo de olvido como de la utilidad del modelo. También aplicaremos un límite estricto que rechazará los algoritmos de olvido que se ejecuten más lentamente que una fracción del tiempo que lleva volver a entrenar. Un resultado valioso de esta competencia será caracterizar los compromisos de diferentes algoritmos de olvido.
 |
| Extracto de imágenes del conjunto de datos de Rostros Sintéticos junto con anotaciones de edad. La competencia considera el escenario en el que se ha entrenado un predictor de edad en imágenes faciales como las anteriores y, después del entrenamiento, cierto subconjunto de las imágenes de entrenamiento debe olvidarse. |
Para evaluar el olvido, utilizaremos herramientas inspiradas en MIAs, como LiRA. Las MIAs fueron desarrolladas por primera vez en la literatura de privacidad y seguridad y su objetivo es inferir qué ejemplos formaron parte del conjunto de entrenamiento. Intuitivamente, si el olvido tiene éxito, el modelo olvidado no contiene rastros de los ejemplos olvidados, lo que hace que las MIAs fallen: el atacante no podrá inferir que el conjunto de olvido era, de hecho, parte del conjunto de entrenamiento original. Además, también utilizaremos pruebas estadísticas para cuantificar cuán diferente es la distribución de los modelos olvidados (producidos por un algoritmo de olvido enviado en particular) en comparación con la distribución de los modelos reentrenados desde cero. Para un algoritmo de olvido ideal, estos dos serán indistinguibles.
Conclusión
El desaprendizaje de máquinas es una herramienta poderosa que tiene el potencial de abordar varios problemas abiertos en el aprendizaje automático. A medida que la investigación en esta área continúa, esperamos ver nuevos métodos que sean más eficientes, efectivos y responsables. Estamos emocionados de tener la oportunidad a través de esta competencia de despertar interés en este campo y esperamos compartir nuestros conocimientos y hallazgos con la comunidad.
Agradecimientos
Los autores de este artículo ahora forman parte de Google DeepMind. Estamos escribiendo esta publicación en nombre del equipo organizador de la Competencia de Desaprendizaje: Eleni Triantafillou*, Fabian Pedregosa* (*contribución igual), Meghdad Kurmanji, Kairan Zhao, Gintare Karolina Dziugaite, Peter Triantafillou, Ioannis Mitliagkas, Vincent Dumoulin, Lisheng Sun Hosoya, Peter Kairouz, Julio C. S. Jacques Junior, Jun Wan, Sergio Escalera e Isabelle Guyon.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- AI Sesgo Desafíos y Soluciones
- ¿Qué tan fácil es engañar a las herramientas de detección de inteligencia artificial?
- Actuadores neumáticos proporcionan aceleración similar a la de un robot cheetah
- Construyendo estructuras ópticas robustas hechas de oscuridad
- Cómo crear un plan de estudio autodidacta de ciencia de datos de 1 año utilizando la estacionalidad de tu cerebro
- ¿Puede la data sintética mejorar el rendimiento del aprendizaje automático?
- Jugando ¿Dónde está Wally? en 3D OpenMask3D es un modelo de IA que puede segmentar instancias en 3D con consultas de vocabulario abierto.






