Pricing Dinámico con Aprendizaje por Reforzamiento desde Cero Q-Learning
Pricing Dinámico con Aprendizaje por Reforzamiento Q-Learning
Una introducción a Q-Learning con un ejemplo práctico en Python
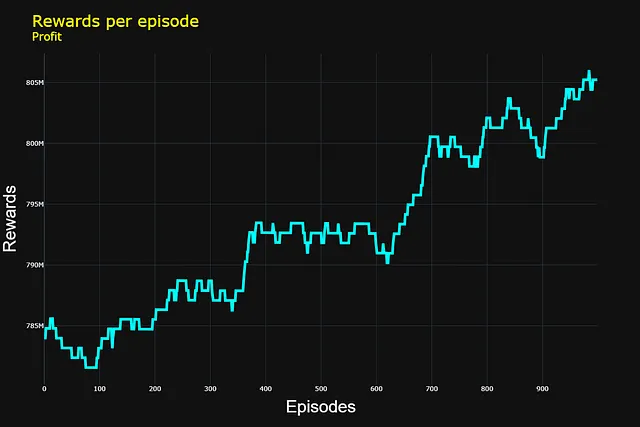
Tabla de contenidos
- Introducción
- Una introducción al Aprendizaje por Reforzamiento2.1 Conceptos clave2.2 Función Q2.3 Valor Q2.4 Q-Learning2.5 La ecuación de Bellman2.6 Exploración vs. explotación2.7 Tabla Q
- El problema de la fijación dinámica de precios3.1 Declaración del problema3.2 Implementación
- Conclusiones
- Referencias
1. Introducción
En esta publicación, presentamos los conceptos fundamentales del Aprendizaje por Reforzamiento y nos adentramos en el Q-Learning, un enfoque que permite a los agentes inteligentes aprender políticas óptimas tomando decisiones informadas basadas en recompensas y experiencias.
También compartimos un ejemplo práctico en Python construido desde cero. En particular, entrenamos a un agente para dominar el arte de la fijación de precios, un aspecto crucial de los negocios, para que pueda aprender a maximizar las ganancias.
Sin más preámbulos, comencemos nuestro viaje.
2. Una introducción al Aprendizaje por Reforzamiento
2.1 Conceptos clave
El Aprendizaje por Reforzamiento (RL) es un área del Aprendizaje Automático donde un agente aprende a realizar una tarea mediante prueba y error.
- Conoce a TADA Un enfoque potente de IA para convertir descripciones verbales en un expresivo avatar 3D
- Aquí está lo que te estás perdiendo
- Métodos de aproximación de Monte Carlo ¿Cuál deberías elegir y cuándo?
En resumen, el agente prueba acciones que están asociadas a una retroalimentación positiva o negativa a través de un mecanismo de recompensa. El agente ajusta su comportamiento para maximizar una recompensa, aprendiendo así la mejor acción a tomar para lograr el objetivo final.
Presentemos los conceptos clave del RL a través de un ejemplo práctico. Imagina un juego de arcade simplificado, donde un gato debe navegar un laberinto para recolectar tesoros: un vaso de leche y una bola de estambre, evitando al mismo tiempo los sitios de construcción:
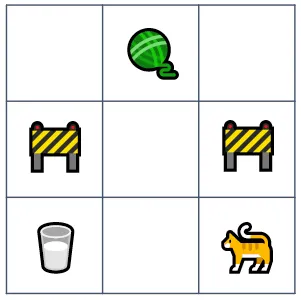
- El agente es quien elige las acciones a tomar. En el ejemplo, el agente es el jugador que controla el joystick y decide el siguiente movimiento del gato.
- El entorno es el…
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Cómo definir un problema de IA
- Científicos secuencian la última pieza del genoma humano el cromosoma Y
- 3 Formas Inteligentes de Usar ChatGPT para Acelerar tu Próximo Proyecto de Ciencia de Datos
- Ciencia de Datos para el Bienestar Más allá de las Ganancias, Hacia un Mundo Mejor
- Streamlit y MongoDB Almacenando tus datos en la nube
- Perspectivas legales y éticas sobre la IA generativa
- Más que solo reptiles Explorando el conjunto de herramientas de las iguanas para la explicabilidad de IA más allá de los modelos de caja negra






