Presentando IDEFICS una reproducción abierta de un modelo de lenguaje visual de última generación.
Presenting IDEFICS, an open reproduction of a state-of-the-art visual language model.
Estamos emocionados de lanzar IDEFICS (Image-aware Decoder Enhanced à la Flamingo with Interleaved Cross-attentionS), un modelo de lenguaje visual de acceso abierto. IDEFICS se basa en Flamingo, un modelo de lenguaje visual de última generación desarrollado inicialmente por DeepMind, que no ha sido lanzado públicamente. Similarmente a GPT-4, el modelo acepta secuencias arbitrarias de imágenes y texto como entrada y produce salidas de texto. IDEFICS se construye únicamente sobre datos y modelos disponibles públicamente (LLaMA v1 y OpenCLIP) y viene en dos variantes: la versión base y la versión instruida. Cada variante está disponible en tamaños de 9 mil millones y 80 mil millones de parámetros.
El desarrollo de modelos de IA de última generación debería ser más transparente. Nuestro objetivo con IDEFICS es reproducir y proporcionar a la comunidad de IA sistemas que igualen las capacidades de los grandes modelos propietarios como Flamingo. Como tal, hemos tomado medidas importantes para llevar transparencia a estos sistemas de IA: hemos utilizado solo datos disponibles públicamente, hemos proporcionado herramientas para explorar conjuntos de datos de entrenamiento, hemos compartido lecciones técnicas y errores de construir tales artefactos y hemos evaluado la nocividad del modelo al provocarlo adversarialmente antes de lanzarlo. Esperamos que IDEFICS sirva como una base sólida para una investigación más abierta en sistemas de IA multimodales, junto con modelos como OpenFlamingo, otra reproducción abierta de Flamingo en la escala de 9 mil millones de parámetros.
¡Prueba la demostración y los modelos en el Hub!
- Tus instrucciones personalizadas para Copiar y Pegar ChatGPT aquí mismo
- Bibliotecas de Aprendizaje Automático para Cualquier Proyecto
- Aprovechando XGBoost para pronóstico de series temporales
¿Qué es IDEFICS?
IDEFICS es un modelo multimodal de 80 mil millones de parámetros que acepta secuencias de imágenes y texto como entrada y genera texto coherente como salida. Puede responder preguntas sobre imágenes, describir contenido visual, crear historias basadas en múltiples imágenes, etc.
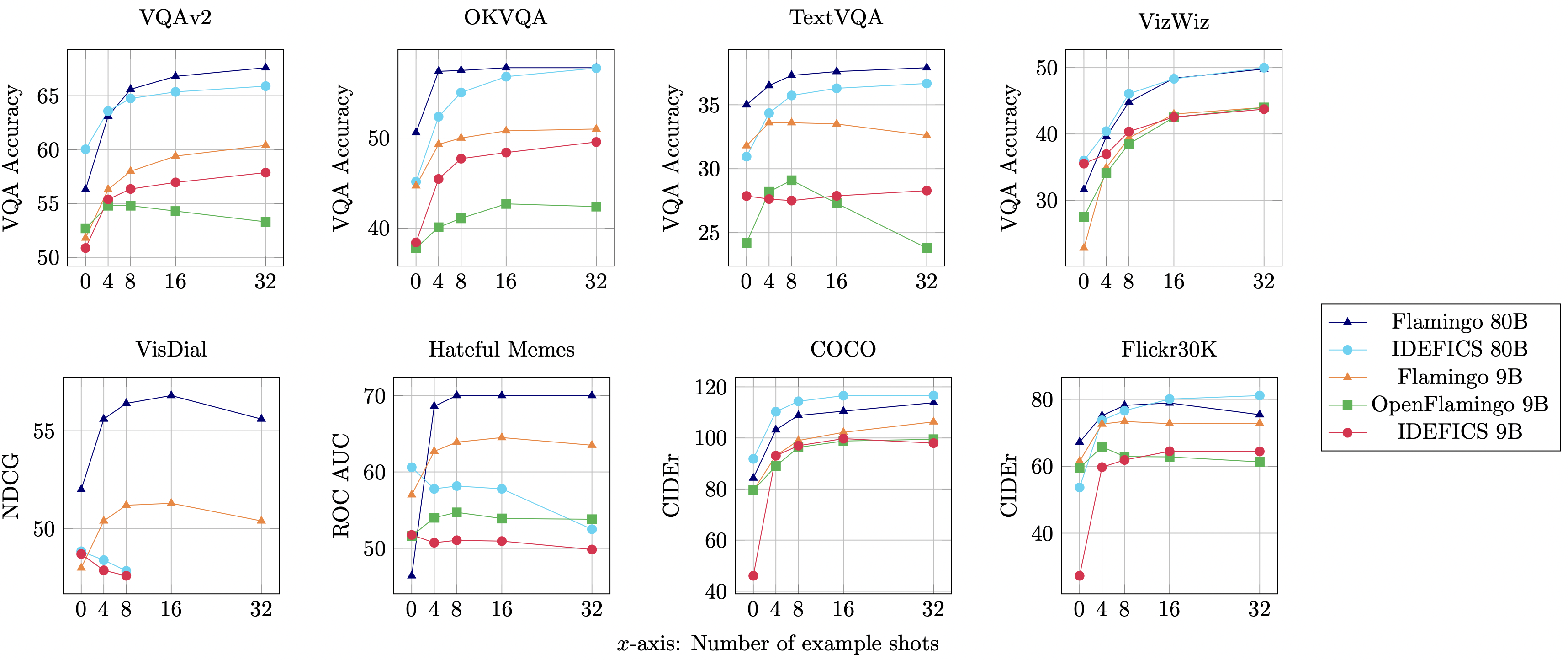
IDEFICS es una reproducción de acceso abierto de Flamingo y tiene un rendimiento comparable al del modelo original de código cerrado en diversos benchmarks de comprensión de imágenes y texto. Viene en dos variantes: 80 mil millones de parámetros y 9 mil millones de parámetros.
También proporcionamos versiones ajustadas idefics-80B-instruct y idefics-9B-instruct adaptadas para casos de uso conversacional.
Datos de entrenamiento
IDEFICS fue entrenado en una mezcla de conjuntos de datos disponibles abiertamente: Wikipedia, Public Multimodal Dataset y LAION, así como un nuevo conjunto de datos de 115 mil millones de tokens llamado OBELICS que creamos. OBELICS consiste en 141 millones de documentos interleaved de imágenes y texto extraídos de la web y contiene 353 millones de imágenes.
Proporcionamos una visualización interactiva de OBELICS que permite explorar el contenido del conjunto de datos con Nomic AI.

Los detalles de la arquitectura de IDEFICS, la metodología de entrenamiento y las evaluaciones, así como información sobre el conjunto de datos, están disponibles en la tarjeta del modelo y en nuestro documento de investigación. Además, hemos documentado conocimientos técnicos y aprendizajes del entrenamiento del modelo, ofreciendo una perspectiva valiosa sobre el desarrollo de IDEFICS.
Evaluación ética
Al comienzo de este proyecto, a través de un conjunto de discusiones, desarrollamos una carta ética que ayudaría a guiar las decisiones tomadas durante el proyecto. Esta carta establece valores, incluyendo la autocrítica, la transparencia y la equidad, que hemos buscado seguir en cómo abordamos el proyecto y el lanzamiento de los modelos.
Como parte del proceso de lanzamiento, evaluamos internamente el modelo en busca de posibles sesgos al provocarlo adversarialmente con imágenes y texto que podrían provocar respuestas no deseadas del modelo (un proceso conocido como red teaming).
¡Por favor, prueba IDEFICS con la demostración, consulta las tarjetas de modelo y la tarjeta de conjunto de datos correspondientes y haznos saber tus comentarios usando la pestaña de la comunidad! Estamos comprometidos a mejorar estos modelos y a hacer que los modelos de IA multimodales grandes sean accesibles para la comunidad de aprendizaje automático.
Licencia
El modelo se construye sobre dos modelos preentrenados: laion/CLIP-ViT-H-14-laion2B-s32B-b79K y huggyllama/llama-65b. El primero se lanzó bajo una licencia MIT, mientras que el segundo se lanzó bajo una licencia específica no comercial centrada en fines de investigación. Como tal, los usuarios deben cumplir con esa licencia solicitando directamente el formulario de Meta.
Los dos modelos pre-entrenados están conectados entre sí con parámetros recién inicializados que entrenamos. Estos no se basan en ninguno de los dos modelos base congelados que forman el modelo compuesto. Liberamos los pesos adicionales que entrenamos bajo una licencia MIT.
Comenzando con IDEFICS
Los modelos de IDEFICS están disponibles en el Hub de Hugging Face y son compatibles con la última versión de transformers. Aquí tienes un ejemplo de código para probarlo:
import torch
from transformers import IdeficsForVisionText2Text, AutoProcessor
device = "cuda" if torch.cuda.is_available() else "cpu"
checkpoint = "HuggingFaceM4/idefics-9b-instruct"
model = IdeficsForVisionText2Text.from_pretrained(checkpoint, torch_dtype=torch.bfloat16).to(device)
processor = AutoProcessor.from_pretrained(checkpoint)
# Alimentamos al modelo una secuencia arbitraria de cadenas de texto e imágenes. Las imágenes pueden ser URLs o imágenes PIL.
prompts = [
[
"Usuario: ¿Qué hay en esta imagen?",
"https://upload.wikimedia.org/wikipedia/commons/8/86/Id%C3%A9fix.JPG",
"<end_of_utterance>",
"\nAsistente: Esta imagen representa a Idefix, el perro de Obelix en Astérix y Obelix. Idefix está corriendo en el suelo.<end_of_utterance>",
"\nUsuario:",
"https://static.wikia.nocookie.net/asterix/images/2/25/R22b.gif/revision/latest?cb=20110815073052",
"¿Y quién es ese?<end_of_utterance>",
"\nAsistente:",
],
]
# --modo por lotes
inputs = processor(prompts, add_end_of_utterance_token=False, return_tensors="pt").to(device)
# --modo de una sola muestra
# inputs = processor(prompts[0], return_tensors="pt").to(device)
# Argumentos de generación
exit_condition = processor.tokenizer("<end_of_utterance>", add_special_tokens=False).input_ids
bad_words_ids = processor.tokenizer(["<image>", "<fake_token_around_image>"], add_special_tokens=False).input_ids
generated_ids = model.generate(**inputs, eos_token_id=exit_condition, bad_words_ids=bad_words_ids, max_length=100)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
for i, t in enumerate(generated_text):
print(f"{i}:\n{t}\n")We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 40+ Herramientas de IA para la Creación y Edición de Videos en 2023
- El Futuro del Descubrimiento Musical Búsqueda vs. Generación
- Revisión de SaneBox Organiza tus correos electrónicos y aumenta la productividad
- Together AI presenta Llama-2-7B-32K-Instruct un avance en el procesamiento del lenguaje con contexto extendido
- La Desesperada Búsqueda del Premio Más Indispensable del Auge de la Inteligencia Artificial
- ChatGPT Propuestas para Hacer que Seas Más Creativo
- 10 Mejores Herramientas de Automatización de Flujo de Trabajo





