Un Enfoque Práctico para la Ingeniería de Características en Aprendizaje Automático
Practical Approach to Feature Engineering in Machine Learning

El aprendizaje de características es un componente vital del aprendizaje automático pero a menudo se habla poco de él, con muchas guías y publicaciones en blogs centradas en las etapas posteriores del ciclo de vida del ML. Este paso de apoyo puede hacer que los modelos de aprendizaje automático sean más precisos y eficientes, convirtiendo los datos sin procesar en algo más tangible y listo para usar. Sin él, construir un modelo completamente optimizado es imposible.
En este artículo, hablaremos sobre cómo funciona el aprendizaje de características en el aprendizaje automático y cómo se puede implementar en pasos simples y prácticos. Además, también discutiremos algunas de las desventajas del ML, brindando una visión general completa de este proceso esencial.
- Construyendo una aplicación web completa en los servicios de AWS
- Listas de Python vs. Arrays de NumPy Un análisis detallado sobre la organización en memoria y los beneficios en rendimiento
- 3 Trucos Poderosos Para Trabajar Con Datos de Fecha y Hora en Python
¿Qué es la Ingeniería de Características?
La ingeniería de características es una técnica importante de aprendizaje automático (ML) que procesa conjuntos de datos y los convierte en un conjunto utilizable de cifras relevantes para tareas específicas.
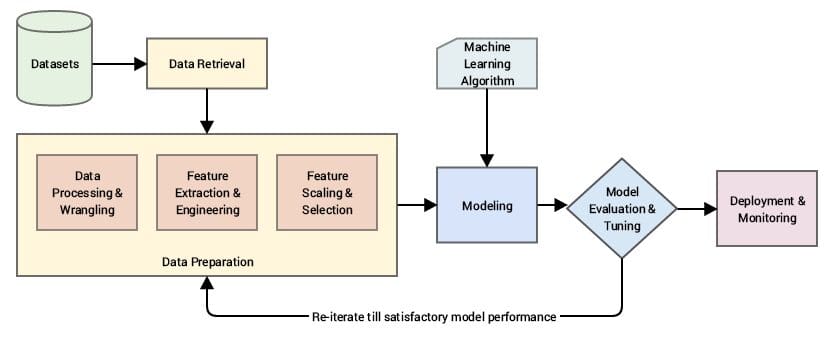
Las características son los elementos de datos que se analizan, apareciendo como columnas dentro de un conjunto de datos. Al corregir, ordenar y normalizar estos elementos de datos, los modelos pueden optimizarse para un mejor rendimiento. El aprendizaje de características modifica estos elementos de datos para hacerlos relevantes, lo que hace que los modelos sean más precisos y con tiempos de respuesta más rápidos gracias a la utilización de menos variables.
El proceso de ingeniería de características se puede descomponer de la siguiente manera:
- Se realiza un análisis para corregir cualquier problema que se encuentre en los datos, como campos incompletos, inconsistencias y otras anomalías.
- Se eliminan las variables que no tienen relevancia para el comportamiento del modelo.
- Se descartan los datos duplicados.
- Se correlacionan y normalizan los registros.
¿Por qué es tan importante la Ingeniería de Características en el Aprendizaje Automático?
Sin la ingeniería de características, no sería posible diseñar modelos predictivos capaces de realizar su función con precisión. El aprendizaje de características también reduce el tiempo y los recursos de computación necesarios, lo que hace que los modelos sean más eficientes.
Las características de los datos dictan cómo funcionará el modelo predictivo, ayudando a entrenar cada modelo para lograr los resultados deseados. Esto significa que incluso los datos que no son completamente aplicables a una función específica pueden modificarse para lograr un resultado adecuado. El aprendizaje de características también reduce significativamente el tiempo que se dedica a realizar análisis de datos más adelante.
Ingeniería de Características: Beneficios y Desventajas
Aunque el aprendizaje de características es esencial, tiene algunas limitaciones, así como los beneficios obvios, que se enumeran a continuación.
Ingeniería de Características: Beneficios
- Los modelos con características ingenierizadas se benefician de un procesamiento de datos más rápido.
- Los modelos se simplifican y, por lo tanto, son más fáciles de mantener.
- Las predicciones y estimaciones son más precisas.
Ingeniería de Características: Desventajas
- La ingeniería de características puede ser un proceso que consume mucho tiempo.
- Se requiere un análisis profundo para construir una lista de características efectiva. Esto incluye una comprensión exhaustiva de los conjuntos de datos, los comportamientos de procesamiento del modelo y el contexto empresarial.
Un Enfoque Práctico para la Ingeniería de Características en el Aprendizaje Automático: Seis Pasos
Ahora que tenemos una mejor comprensión de lo que el aprendizaje de características puede hacer, así como sus desventajas, consideremos un enfoque práctico del proceso en 6 pasos clave.
#1 Preparación de Datos
El primer paso en el proceso de ingeniería de características es convertir los datos sin procesar que se han recopilado de diversas fuentes en un formato utilizable. Los formatos ML utilizables incluyen; .csc; .tfrecords; .json; .xml; y .avro. Para preparar los datos, deben pasar por una serie de procesos como limpieza, fusión, ingestión y carga.
#2 Análisis de Datos
La etapa de análisis, a veces denominada etapa exploratoria, es cuando se extraen ideas y estadísticas descriptivas de los conjuntos de datos, que luego se presentan en visualizaciones para comprender mejor los datos. A esto le sigue la identificación de variables correlacionadas y sus propiedades para que puedan ser limpiadas.
#3 Mejora
Una vez que los datos han sido analizados y depurados, es hora de mejorarlos añadiendo los valores faltantes, normalizando, transformando y escalando. Los datos también pueden ser modificados aún más mediante la adición de valores ficticios que son variables cualitativas/discretas que representan datos categóricos.
#4 Construcción
Las características se pueden construir tanto manualmente como automáticamente utilizando algoritmos (como tSNE o Análisis de Componentes Principales (PCA), por ejemplo). Hay un número casi inagotable de opciones cuando se trata de la construcción de características. Sin embargo, la solución siempre dependerá del problema.
#5 Selección
La selección de características/variables/atributos reduce el número de variables de entrada (columnas de características) al elegir solo aquellas que son más relevantes para la variable que el modelo está construido para predecir. Esto ayuda a ofrecer mejores velocidades de procesamiento y reducir el uso de recursos computacionales.
Las técnicas de selección de características incluyen:
- Filtros para eliminar características irrelevantes.
- Envoltorios para entrenar modelos de aprendizaje automático para usar varias características
- Modelos híbridos que combinan filtros y envoltorios
Por ejemplo, las técnicas basadas en filtros se basan en pruebas estadísticas para determinar si la característica se correlaciona suficientemente con la variable objetivo.
#6 Evaluación y Verificación
El proceso de evaluación determina la precisión del modelo en términos de datos de entrenamiento utilizando las características seleccionadas. Si el nivel de precisión cumple con el estándar requerido, entonces el modelo puede ser verificado. Si no, entonces la etapa de selección de características deberá repetirse.
Casos de Uso de Ingeniería de Características
Veamos ahora tres casos de uso comunes para la ingeniería de características en el aprendizaje automático.
Información Adicional del Mismo Conjunto de Datos
Muchos conjuntos de datos contienen valores arbitrarios, como fecha, edad, etc., que podrían modificarse en diferentes formatos que proporcionan información específica sobre una consulta. Por ejemplo, los detalles de fecha y duración se pueden cruzar para determinar los comportamientos de los usuarios, como la frecuencia con la que visitan un sitio web y cuánto tiempo pasan allí.
Modelos Predictivos
Seleccionar las características correctas puede ayudar a construir modelos predictivos para una variedad de industrias, una industria que puede beneficiarse de dicho modelo es el transporte público, ayudando a determinar cuántos pasajeros pueden utilizar un servicio en un día específico.
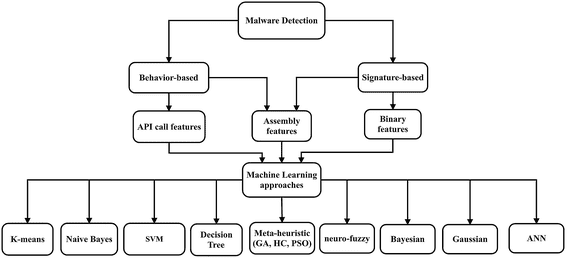
Detección de Malware
La detección manual de malware es extremadamente difícil, y la mayoría de las redes neuronales también tienen problemas en este sentido. Sin embargo, la ingeniería de características puede combinar técnicas manuales y redes neuronales para resaltar comportamientos inusuales.
Ingeniería de Características en el Aprendizaje Automático: Conclusión
La ingeniería de características es una etapa importante al construir modelos de aprendizaje automático, y hacer esta etapa correctamente puede garantizar que los modelos de aprendizaje automático sean más precisos, utilicen menos recursos computacionales y procesen a velocidades más altas.
El proceso de ingeniería de características se puede descomponer en seis etapas, desde la preparación inicial de los datos hasta la verificación, eligiendo solo los elementos de datos más relevantes para una tarea específica. Nahla Davies es una desarrolladora de software y escritora técnica. Antes de dedicarse por completo a la escritura técnica, se desempeñó, entre otras cosas interesantes, como programadora principal en una organización de branding experimental Inc. 5,000 cuyos clientes incluyen a Samsung, Time Warner, Netflix y Sony.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Una nueva investigación de IA presenta GPT4RoI un modelo de visión y lenguaje basado en la sintonización de instrucciones de un Gran Modelo de Lenguaje (LLM) en pares de región-texto.
- Los investigadores de la Universidad de Pennsylvania presentaron un enfoque alternativo de IA para diseñar y programar computadoras de depósito basadas en RNN.
- Red Neuronal Recurrente con Puertas desde Cero en Julia
- 8 Razones por las que no renuncié a mi sueño de ser un científico de datos y por qué tú tampoco deberías hacerlo
- CarperAI presenta OpenELM una biblioteca de código abierto diseñada para permitir la búsqueda evolutiva con modelos de lenguaje tanto en código como en lenguaje natural.
- Productividad impulsada por IA la IA generativa abre una nueva era de eficiencia en todas las industrias
- La evolución automatizada aborda tareas difíciles






