Práctica con Aprendizaje Supervisado Regresión Lineal
Práctica Aprendizaje Supervisado Regresión Lineal

Descripción básica
La regresión lineal es el algoritmo fundamental de aprendizaje automático supervisado para predecir variables objetivo continuas basadas en las características de entrada. Como su nombre lo indica, asume que la relación entre la variable dependiente y la variable independiente es lineal. Por lo tanto, si intentamos trazar la variable dependiente Y contra la variable independiente X, obtendremos una línea recta. La ecuación de esta línea se puede representar por:
- Cómo Identificar Datos Faltantes en Conjuntos de Datos de Series Temporales
- Cómo la Inteligencia Artificial está transformando la Gestión de Servicios de TI
- 10 Puntos Clave en IA Generativa (2024)
Donde,
- Y Salida predicha.
- X = Característica de entrada o matriz de características en regresión lineal múltiple
- b0 = Intersección (donde la línea corta el eje Y).
- b1 = Pendiente o coeficiente que determina la inclinación de la línea.
La idea central en la regresión lineal gira en torno a encontrar la línea de mejor ajuste para nuestros puntos de datos de manera que el error entre los valores reales y los valores predichos sea mínimo. Lo hace estimando los valores de b0 y b1. Luego utilizamos esta línea para hacer predicciones.
Implementación usando Scikit-Learn
Ahora que comprende la teoría detrás de la regresión lineal, para solidificar aún más nuestra comprensión, construyamos un modelo de regresión lineal simple utilizando Scikit-learn, una biblioteca popular de aprendizaje automático en Python. Siga los pasos a continuación para comprender mejor.
1. Importar bibliotecas necesarias
Primero, deberá importar las bibliotecas necesarias.
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
2. Analizando el conjunto de datos
Puede encontrar el conjunto de datos aquí. Contiene archivos CSV separados para entrenamiento y prueba. Veamos y analicemos nuestro conjunto de datos antes de continuar.
# Cargar los conjuntos de datos de entrenamiento y prueba desde archivos CSV
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
# Mostrar las primeras filas del conjunto de datos de entrenamiento para entender su estructura
print(train.head())
Salida: 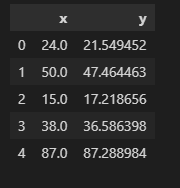
El conjunto de datos contiene 2 variables y queremos predecir y basado en el valor x.
# Ver información sobre los conjuntos de datos de entrenamiento y prueba, como los tipos de datos y los valores faltantes
print(train.info())
print(test.info())
Salida:
RangeIndex: 700 entries, 0 to 699
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 x 700 non-null float64
1 y 699 non-null float64
dtypes: float64(2)
memory usage: 11.1 KB
RangeIndex: 300 entries, 0 to 299
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 x 300 non-null int64
1 y 300 non-null float64
dtypes: float64(1), int64(1)
memory usage: 4.8 KB
La salida anterior muestra que tenemos un valor faltante en el conjunto de datos de entrenamiento que se puede eliminar con el siguiente comando:
train = train.dropna()
También verifique si su conjunto de datos contiene duplicados y elimínelos antes de alimentarlo a su modelo.
duplicates_exist = train.duplicated().any()
print(duplicates_exist)
Salida:
Falso
2. Preprocesamiento del Conjunto de Datos
Ahora, prepare los datos de entrenamiento y prueba y el objetivo con el siguiente código:
# Extraindo las columnas x e y para el conjunto de datos de entrenamiento y prueba
X_train = train['x']
y_train = train['y']
X_test = test['x']
y_test = test['y']
print(X_train.shape)
print(X_test.shape)
Salida:
(699, )
(300, )
Puede ver que tenemos una matriz unidimensional. Si bien técnicamente podría usar matrices unidimensionales con algunos modelos de aprendizaje automático, no es la práctica más común y puede conducir a un comportamiento inesperado. Por lo tanto, vamos a remodelar los datos anteriores a (699,1) y (300,1) para especificar explícitamente que tenemos una etiqueta por punto de datos.
X_train = X_train.values.reshape(-1, 1)
X_test = X_test.values.reshape(-1,1)
Cuando las características están en diferentes escalas, algunas pueden dominar el proceso de aprendizaje del modelo, lo que conduce a resultados incorrectos o subóptimos. Para este propósito, realizamos la estandarización para que nuestras características tengan una media de 0 y una desviación estándar de 1.
Antes:
print(X_train.min(),X_train.max())
Salida:
(0.0, 100.0)
Estandarización:
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
print((X_train.min(),X_train.max())
Salida:
(-1.72857469859145, 1.7275858114641094)
Ahora hemos terminado con los pasos esenciales de preprocesamiento de datos, y nuestros datos están listos para propósitos de entrenamiento.
4. Visualizando el Conjunto de Datos
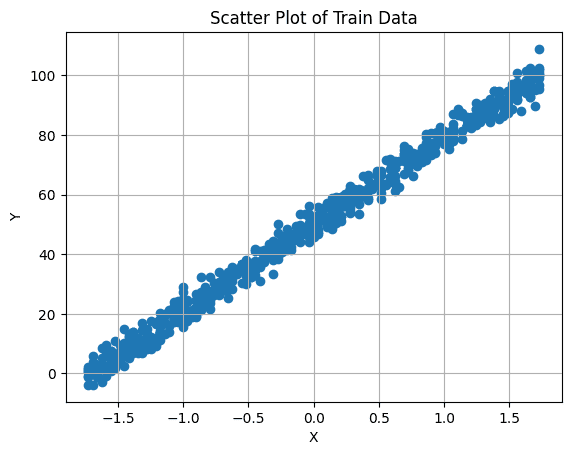
Es importante visualizar primero la relación entre nuestra variable objetivo y la característica. Puede hacer esto haciendo un diagrama de dispersión:
# Crear un diagrama de dispersión
plt.scatter(X_train, y_train)
plt.xlabel('X')
plt.ylabel('Y')
plt.title('Diagrama de Dispersión de los Datos de Entrenamiento')
plt.grid(True) # Habilitar cuadrícula
plt.show()
5. Crear y Entrenar el Modelo
Ahora crearemos una instancia del modelo de Regresión Lineal utilizando Scikit Learn e intentaremos ajustarlo a nuestro conjunto de datos de entrenamiento. Encuentra los coeficientes (pendientes) de la ecuación lineal que mejor se ajusta a tus datos. Esta línea se utiliza luego para hacer las predicciones. El código para este paso es el siguiente:
# Crear un modelo de Regresión Lineal
modelo = LinearRegression()
# Ajustar el modelo a los datos de entrenamiento
modelo.fit(X_train, y_train)
# Utilizar el modelo entrenado para predecir los valores objetivo para los datos de prueba
predicciones = modelo.predict(X_test)
# Calcular el error cuadrático medio (MSE) como métrica de evaluación para evaluar el rendimiento del modelo
mse = mean_squared_error(y_test, predicciones)
print(f'El error cuadrático medio es: {mse:.4f}')
Salida:
El error cuadrático medio es: 9.4329
6. Visualizar la Línea de Regresión
Podemos trazar nuestra línea de regresión utilizando el siguiente comando:
# Trazar la línea de regresión
plt.plot(X_test, predicciones, color='red', linewidth=2, label='Línea de Regresión')
plt.xlabel('X')
plt.ylabel('Y')
plt.title('Modelo de Regresión Lineal')
plt.legend()
plt.grid(True)
plt.show()
Resultado: 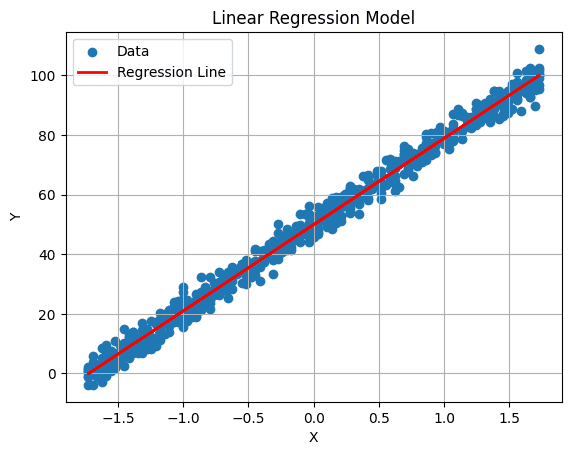
Conclusión
¡Eso es todo! Ahora has implementado con éxito un modelo fundamental de Regresión Lineal utilizando Scikit-learn. Las habilidades que has adquirido aquí se pueden extender para abordar conjuntos de datos complejos con más características. Es un desafío que vale la pena explorar en tu tiempo libre, abriendo puertas al emocionante mundo de la resolución de problemas y la innovación basada en datos. Kanwal Mehreen es una desarrolladora de software aspirante con un gran interés en la ciencia de datos y las aplicaciones de IA en medicina. Kanwal fue seleccionada como la Google Generation Scholar 2022 para la región de APAC. A Kanwal le encanta compartir conocimientos técnicos escribiendo artículos sobre temas de tendencia y está apasionada por mejorar la representación de las mujeres en la industria tecnológica.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Las 10 mejores empresas de ciencia de datos en Estados Unidos
- Top 10 Automatización de IA para Aumentar tu Productividad
- Empezando con Scikit-learn en 5 Pasos
- Introducción a la Reidentificación de Personas
- ¿Qué es un Sistema de Producción en IA? Ejemplos, Funcionamiento y Más
- Investigadores de la Universidad de Pensilvania presentan Kani un marco de inteligencia artificial de código abierto, ligero, flexible y agnóstico al modelo para construir aplicaciones de modelos de lenguaje.
- ¿Puede un Modelo de Lenguaje Revolucionar la Radiología? Conozca Radiology-Llama2 Un Gran Modelo de Lenguaje Especializado en Radiología a través de un Proceso Conocido como Ajuste de Instrucciones.






