Potenciando los tubos RAG en Haystack Presentando DiversityRanker y LostInTheMiddleRanker
Potenciando tubos RAG en Haystack con DiversityRanker y LostInTheMiddleRanker
Cómo los últimos rankers optimizan la utilización de la ventana de contexto de LLM en los pipelines de generación aumentada de recuperación (RAG)
Las mejoras recientes en Procesamiento de Lenguaje Natural (NLP) e Interrogación de Preguntas de Larga Forma (LFQA) habrían sonado, hace apenas unos años, como algo propio de la ciencia ficción. ¿Quién podría haber pensado que actualmente tendríamos sistemas capaces de responder preguntas complejas con la precisión de un experto, todo mientras sintetizan estas respuestas sobre la marcha a partir de una vasta cantidad de fuentes? LFQA es un tipo de generación aumentada de recuperación (RAG) que ha avanzado significativamente recientemente, utilizando las mejores capacidades de recuperación y generación de Modelos de Lenguaje Grandes (LLMs).
Pero, ¿qué pasaría si pudiéramos refinar aún más esta configuración? ¿Qué tal si pudiéramos optimizar cómo RAG selecciona y utiliza la información para mejorar su rendimiento? Este artículo presenta dos componentes innovadores que tienen como objetivo mejorar RAG con ejemplos concretos extraídos de LFQA, basados en las últimas investigaciones y nuestra experiencia: DiversityRanker y LostInTheMiddleRanker.
Considera la ventana de contexto de LLM como una comida gourmet, donde cada párrafo es un ingrediente único y sabroso. Así como una obra maestra culinaria requiere ingredientes diversos y de alta calidad, LFQA, que responde a preguntas, demanda una ventana de contexto llena de párrafos de alta calidad, variados, relevantes y no repetitivos.
En el intrincado mundo de LFQA y RAG, aprovechar al máximo la ventana de contexto de LLM es fundamental. Cualquier espacio desperdiciado o contenido repetitivo limita la profundidad y amplitud de las respuestas que podemos extraer y generar. Es un acto de equilibrio delicado organizar adecuadamente el contenido de la ventana de contexto. Este artículo presenta nuevos enfoques para dominar este acto de equilibrio, que mejorarán la capacidad de RAG para proporcionar respuestas precisas y completas.
- Despliega miles de conjuntos de modelos con puntos finales multinivel de Amazon SageMaker en GPU para minimizar tus costos de alojamiento
- Decodificando la Sinfonía del Sonido Procesamiento de Señales de Audio para la Ingeniería Musical
- Este boletín de inteligencia artificial es todo lo que necesitas #59
Exploremos estos avances emocionantes y cómo mejoran LFQA y RAG.
Antecedentes
Haystack es un marco de código abierto que proporciona soluciones integrales para desarrolladores prácticos de NLP. Admite una amplia gama de casos de uso, desde preguntas y respuestas hasta búsqueda semántica de documentos y agentes de LLM. Su diseño modular permite la integración de modelos de NLP de última generación, almacenes de documentos y varios otros componentes requeridos en el conjunto de herramientas de NLP actual.
Uno de los conceptos clave en Haystack es la idea de un pipeline. Un pipeline representa una secuencia de pasos de procesamiento que ejecuta un componente específico. Estos componentes pueden realizar varios tipos de procesamiento de texto, lo que permite a los usuarios crear sistemas potentes y personalizables definiendo cómo fluye los datos a través del pipeline y el orden de los nodos que realizan sus pasos de procesamiento.
El pipeline juega un papel crucial en la respuesta a preguntas de larga forma basada en la web. Comienza con un componente WebRetriever, que busca y recupera documentos relevantes para la consulta de la web, eliminando automáticamente el contenido HTML en texto sin formato. Pero una vez que obtenemos documentos relevantes para la consulta, ¿cómo los aprovechamos al máximo? ¿Cómo llenamos la ventana de contexto de LLM para maximizar la calidad de las respuestas? ¿Y qué sucede si estos documentos, aunque altamente relevantes, son repetitivos y numerosos, a veces desbordando la ventana de contexto de LLM?
Aquí es donde entran en juego los componentes que presentaremos hoy: DiversityRanker y LostInTheMiddleRanker. Su objetivo es abordar estos desafíos y mejorar las respuestas generadas por los pipelines de LFQA/RAG.
DiversityRanker mejora la diversidad de los párrafos seleccionados para la ventana de contexto. LostInTheMiddleRanker, generalmente posicionado después de DiversityRanker en el pipeline, ayuda a mitigar la degradación del rendimiento de LLM observada cuando los modelos deben acceder a información relevante en el medio de una ventana de contexto larga. Las siguientes secciones profundizarán en estos dos componentes y demostrarán su efectividad en un caso de uso práctico.
DiversityRanker
DiversityRanker es un componente novedoso diseñado para mejorar la diversidad de los párrafos seleccionados para la ventana de contexto en el pipeline de RAG. Opera bajo el principio de que un conjunto diverso de documentos puede aumentar la capacidad de LLM para generar respuestas con mayor amplitud y profundidad.
El DiversityRanker utiliza sentence transformers para calcular la similitud entre documentos. La biblioteca sentence transformers ofrece potentes modelos de embedding para crear representaciones significativas de frases, párrafos e incluso documentos completos. Estas representaciones, o embeddings, capturan el contenido semántico del texto, permitiéndonos medir qué tan similares son dos piezas de texto.
DiversityRanker procesa los documentos utilizando el siguiente algoritmo:
1. Comienza calculando los embeddings para cada documento y la consulta utilizando un modelo de sentence-transformer.
2. Luego selecciona el documento semánticamente más cercano a la consulta como el primer documento seleccionado.
3. Para cada documento restante, calcula la similitud promedio con los documentos ya seleccionados.
4. Luego selecciona el documento que, en promedio, es menos similar a los documentos ya seleccionados.
5. Este proceso de selección continúa hasta que todos los documentos sean seleccionados, resultando en una lista de documentos ordenados desde el documento que contribuye más a la diversidad general hasta el documento que contribuye menos.
Una nota técnica a tener en cuenta: el DiversityRanker utiliza un enfoque local y voraz para seleccionar el siguiente documento en orden, lo cual podría no encontrar el orden general más óptimo para los documentos. DiversityRanker se enfoca más en la diversidad que en la relevancia, por lo que debe colocarse en el pipeline después de otro componente como TopPSampler u otro ranker de similitud que se enfoque más en la relevancia. Al usarlo después de un componente que selecciona los documentos más relevantes, nos aseguramos de seleccionar documentos diversos de un conjunto de documentos ya relevantes.
LostInTheMiddleRanker
LostInTheMiddleRanker optimiza la disposición de los documentos seleccionados en la ventana de contexto de LLM. Este componente es una forma de solucionar un problema identificado en investigaciones recientes [1] que sugiere que los LLM tienen dificultades para enfocarse en pasajes relevantes en el centro de un largo contexto. LostInTheMiddleRanker alterna la ubicación de los mejores documentos al principio y al final de la ventana de contexto, facilitando que el mecanismo de atención de LLM los acceda y los utilice. Para comprender cómo LostInTheMiddleRanker ordena los documentos dados, imagina un ejemplo simple donde los documentos consisten en un solo dígito del 1 al 10 en orden ascendente. LostInTheMiddleRanker ordenará estos diez documentos en el siguiente orden: [1 3 5 7 9 10 8 6 4 2].
Aunque los autores de esta investigación se centraron en una tarea de pregunta-respuesta, extrayendo los fragmentos relevantes de la respuesta del texto, especulamos que el mecanismo de atención de LLM también tendrá más facilidad para enfocarse en los párrafos al principio y al final de la ventana de contexto al generar respuestas.
LostInTheMiddleRanker se posiciona mejor como el último ranker en el pipeline de RAG, ya que los documentos dados ya están seleccionados en base a la similitud (relevancia) y ordenados por diversidad.
Usando los nuevos rankers en pipelines
En esta sección, veremos el caso de uso práctico del pipeline LFQA/RAG, enfocándonos en cómo integrar el DiversityRanker y LostInTheMiddleRanker. También discutiremos cómo estos componentes interactúan entre sí y con los otros componentes en el pipeline.
El primer componente en el pipeline es un WebRetriever que recupera documentos relevantes a la consulta desde la web utilizando una API de motor de búsqueda programática (SerperDev, Google, Bing, etc.). Los documentos recuperados son primero despojados de etiquetas HTML, convertidos a texto sin formato y opcionalmente preprocesados en párrafos más cortos. Luego, se pasan a un componente TopPSampler, que selecciona los párrafos más relevantes en función de su similitud con la consulta.
Después de que TopPSampler selecciona el conjunto de párrafos relevantes, se pasan al DiversityRanker. DiversityRanker, a su vez, ordena los párrafos en función de su diversidad, reduciendo la repetitividad de los documentos ordenados por TopPSampler.
Los documentos seleccionados luego son pasados al LostInTheMiddleRanker. Como mencionamos anteriormente, LostInTheMiddleRanker coloca los párrafos más relevantes al principio y al final de la ventana de contexto, mientras empuja los documentos con peor clasificación al medio.
Finalmente, los párrafos fusionados se pasan a un PromptNode, que condiciona a un LLM para responder la pregunta basándose en estos párrafos seleccionados.
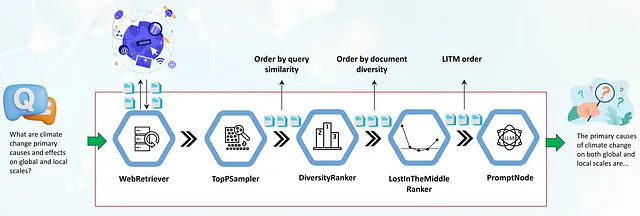
Los nuevos clasificadores ya se han fusionado en la rama principal de Haystack y estarán disponibles en la próxima versión 1.20 programada para finales de agosto de 2023. Hemos incluido una nueva demostración del pipeline LFQA/RAG en la carpeta de ejemplos del proyecto.
La demostración muestra cómo se pueden integrar fácilmente DiversityRanker y LostInTheMiddleRanker en un pipeline RAG para mejorar la calidad de las respuestas generadas.
Estudio de caso
Para demostrar la efectividad de los pipelines LFQA/RAG que incluyen los dos nuevos clasificadores, utilizaremos una pequeña muestra de media docena de preguntas que requieren respuestas detalladas. Las preguntas incluyen: “¿Cuáles son las principales razones de las animosidades de larga data entre Rusia y Polonia?”, “¿Cuáles son las causas principales del cambio climático a escala global y local?”, y más. Para responder bien estas preguntas, los LLM requieren una amplia gama de fuentes históricas, políticas, científicas y culturales, lo que los hace ideales para nuestro caso de uso.
Comparar las respuestas generadas por el pipeline RAG con los dos nuevos clasificadores (pipeline optimizado) y un pipeline sin ellos (no optimizado) requeriría una evaluación compleja que involucra el juicio de expertos humanos. Para simplificar la evaluación y evaluar principalmente el efecto de DiversityRanker, calculamos la distancia coseno promedio de pares de los documentos de contexto inyectados en el contexto del LLM en su lugar. Limitamos el tamaño de la ventana de contexto en ambos pipelines a 1024 palabras. Al ejecutar estos scripts de Python de muestra [2], hemos encontrado que el pipeline optimizado tiene un aumento promedio del 20-30% en la distancia coseno de pares [3] para los documentos inyectados en el contexto del LLM. Este aumento en la distancia coseno de pares significa esencialmente que los documentos utilizados son más diversos (y menos repetitivos), lo que le brinda al LLM una gama más amplia y rica de párrafos para utilizar en sus respuestas. Dejaremos la evaluación de LostInTheMiddleRanker y su efecto en las respuestas generadas para uno de nuestros próximos artículos.
Conclusión
Hemos explorado cómo los usuarios de Haystack pueden mejorar sus pipelines RAG utilizando dos clasificadores innovadores: DiversityRanker y LostInTheMiddleRanker.
DiversityRanker asegura que la ventana de contexto del LLM esté llena de documentos diversos y no repetitivos, proporcionando una gama más amplia de párrafos para que el LLM sintetice la respuesta. Al mismo tiempo, LostInTheMiddleRanker optimiza la ubicación de los párrafos más relevantes en la ventana de contexto, facilitando que el modelo acceda y utilice los documentos de mayor apoyo.
Nuestro pequeño estudio de caso confirmó la efectividad de DiversityRanker al calcular la distancia coseno promedio de pares de los documentos inyectados en la ventana de contexto del LLM en el pipeline RAG optimizado (con los dos nuevos clasificadores) y el pipeline no optimizado (sin clasificadores utilizados). Los resultados mostraron que un pipeline RAG optimizado aumentó la distancia coseno promedio en aproximadamente un 20-30%.
Hemos demostrado cómo estos nuevos clasificadores pueden mejorar potencialmente la pregunta-respuesta de formato largo (Long-Form Question-Answering) y otros pipelines RAG. Al continuar invirtiendo y expandiendo estas y otras ideas similares, podemos mejorar aún más las capacidades de los pipelines RAG de Haystack, acercándonos a crear soluciones de procesamiento de lenguaje natural (NLP) que parezcan más magia que realidad.
Referencias:
[1] “Lost in the Middle: How Language Models Use Long Contexts” en https://arxiv.org/abs/2307.03172
[2] Script: https://gist.github.com/vblagoje/430def6cda347c0b65f5f244bc0f2ede
[3] Resultado del script (respuestas): https://gist.github.com/vblagoje/738253f87b7590b1c014e3d598c8300b
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Ajuste fino de Llama 2 con DPO
- La GPU NVIDIA H100 Tensor Core utilizada en la nueva serie de máquinas virtuales de Microsoft Azure ya está disponible de forma general
- DENZA colabora con WPP para construir e implementar configuradores avanzados de automóviles en la nube NVIDIA Omniverse
- Shutterstock lleva la IA generativa a los fondos de escenas en 3D con NVIDIA Picasso
- Charla especial SIGGRAPH El CEO de NVIDIA lleva la IA generativa a la muestra de Los Ángeles
- Optical Vectors Beam Multi-Bits’ ‘Optical Vectors Beam Multi-Bits’ (Rayos Ópticos Multibits)
- La FAA aprueba el sistema de aeronaves no tripuladas más grande de los Estados Unidos.






