Evolucionando un Plan de Pruebas para una Canalización de Datos
'Plan de pruebas evolutivo para canalización de datos'
Los peligros del desarrollo dirigido por pruebas exhaustivas de múltiples orígenes y múltiples destinos
El primer contacto con la idea del Desarrollo Dirigido por Pruebas deja a muchos ingenieros de datos principiantes en estado de shock por lo que TDD promete. Desarrollo más rápido, código más limpio, avance en la carrera y dominación mundial, por nombrar algunos. Sin embargo, la realidad es bastante diferente. Los intentos iniciales de aplicar TDD a la ingeniería de datos desmotivan a muchos ingenieros de datos. Extraer el valor de TDD requiere mucho esfuerzo. Se requiere un profundo conocimiento de técnicas de pruebas que no están en el conjunto de herramientas de principiante de DE. El proceso de aprender “qué” probar es difícil. Aprender los compromisos inherentes a la aplicación de TDD a los flujos de datos es aún más difícil.
En este artículo analizamos cómo evolucionar un plan de pruebas de un pipeline de datos para evitar sentir todo el dolor que proviene de pruebas sobre-especificadas.
Problema
¿Cuáles son los peligros del desarrollo dirigido por pruebas? A pesar de todos sus beneficios, TDD puede ser peligroso para un nuevo ingeniero de datos. El impulso inicial de probar todo es fuerte y puede llevar a elecciones de diseño subóptimas. Demasiado de algo bueno, como dicen.
La necesidad de probar cada parte del pipeline de datos es una dirección tentadora para personas con mentalidad de ingeniería. Pero para preservar la cordura, es necesario ejercer cierta moderación. De lo contrario, terminarás con una jungla de pruebas rodeada de un mar de errores. Y las bolas de barro nunca están muy lejos.
- Cómo llamar a Hugging Face AI desde una base de datos Oracle usando JavaScript
- Agentes Orientados a Documentos Un Viaje con Bases de Datos Vectoriales, LLMs, Langchain, FastAPI y Docker
- Potencia tu Python Asyncio con Aiomultiprocess Una guía completa
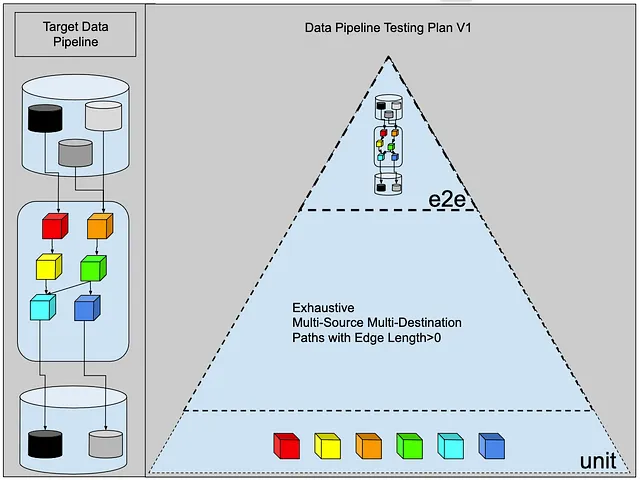
Por ejemplo, digamos que tenemos el siguiente pipeline de datos:

Tenemos tres fuentes de datos, seis transformaciones y dos destinos de datos.
¿Qué produciría un ingeniero de datos inexperto como un plan de pruebas? Todos hemos estado ahí.
Solución #1: Rutas exhaustivas de múltiples orígenes y múltiples destinos con longitud de borde > 0
Usando el clásico marco de pruebas de 3 partes, podemos asumir con seguridad que nuestro ingeniero de datos comenzará con esto:
- Pruebas unitarias ✅ : Claro, toma cada transformación, genera algunos datos de entrada de muestra para cada transformación, ejecuta los datos de muestra a través de cada paso del pipeline, captura los resultados y usa la salida para validar la lógica de transformación.
- Prueba de extremo a extremo (E2E) ✅ : De todos modos, necesitaremos ejecutar el pipeline en datos de producción completos, así que ejecutemos todo el pipeline en una muestra de los datos de producción, capturamos los resultados y usamos esa salida para validar el pipeline de extremo a extremo.
- Pruebas de integración ❓❓❓: ¿Pero qué hacer aquí? La primera inclinación es construir una prueba para cada una de las combinaciones de etapas de transformación.
Después de hacer algunos cálculos rápidos, nuestro ingeniero de datos empieza a comprender el hecho de que la combinación de los 6 pasos de transformación crece rápidamente. Debe haber una mejor manera.
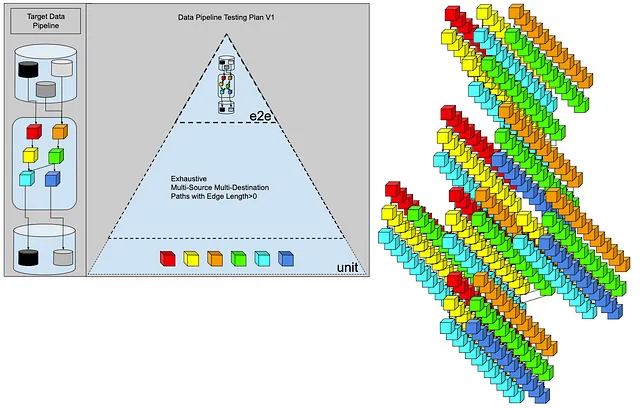
Probar cada combinación con bordes de longitud variable no cumplirá con la fecha límite que prometimos al cliente. Deberíamos haber presupuestado más tiempo.
Solución #2:
“OK OK, pero no puede ser tan malo.”
Sí, considerando que las pruebas de integración no tocarán fuentes y sinks reales, entonces que así sea, unamos estas 6 transformaciones. Obtenemos las combinaciones de gráficos a continuación. Obtenemos aproximadamente 10 pruebas de integración.
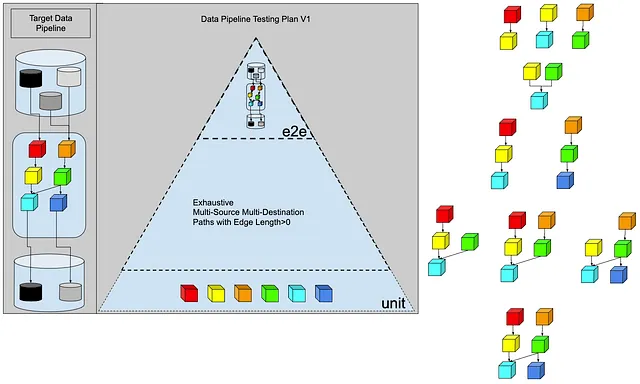
Pero recuerda que esto es ingeniería de datos, lo que significa que los datos de entrada están fuera de nuestro control y cambian con el tiempo. Por lo tanto, necesitamos agregar pruebas centradas en los datos. (Seguramente sabes mejor, pero sigamos este argumento).

Solución #3:
“Pero ¿no podemos resumir esto de alguna manera? Debe haber un conjunto central de escenarios de datos que necesitamos apoyar absolutamente. ¿Como una lista de prioridades de validación de datos?”
Claro, pero incluso si retrasamos las comprobaciones de validación de datos, aún obtenemos esta imagen:

“¿Realmente necesitamos tantas pruebas? ¿No se trata de probar lo que ven los usuarios? ¿No podemos sacrificar la experiencia del desarrollador para entregar un buen producto, a tiempo, que resuelva el problema de los clientes?”
Claro, sí, el siguiente paso lógico es ejecutar solo las pruebas de extremo a extremo y seguir adelante con nuestras vidas. Sin embargo, hay un paso intermedio que resuelve ambos problemas de “demasiadas pruebas de integración” y “pruebas sólidas de validación de datos”. Probablemente ya lo hayas utilizado antes pero no tenías un nombre para ello: “Aserciones en línea”. Este es un truco bastante útil de la tradición de programación defensiva.
Solución #4:
La idea principal de estas “Aserciones en línea” es que construyas, cuando sea posible, toda la canalización como un monolito que incluya aserciones sobre las interfaces de código Y las interfaces de datos entre los componentes de tu monolito.
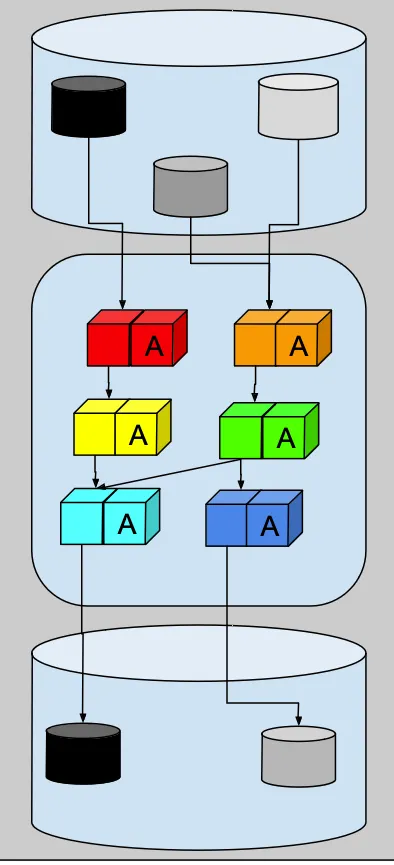
Eso es todo, lo colocas en el ciclo de desarrollo de rojo, verde, refactorizar, y sigues aumentando esa lista de aserciones a medida que ocurren cosas aleatorias.
Estamos un poco acelerados aquí, pero ten en cuenta que estamos utilizando fuentes de datos de producción y destinos de producción. Si estás en un aprieto, adelante. Si tienes tiempo, al menos crea destinos de prueba dedicados y recuerda poner límites en la cantidad de filas que obtienes de las fuentes de datos de entrada.
Esto puede parecer obvio para ti, pero todos estamos aprendiendo cómo construir canalizaciones de datos que resuelvan el problema de los clientes 🙂
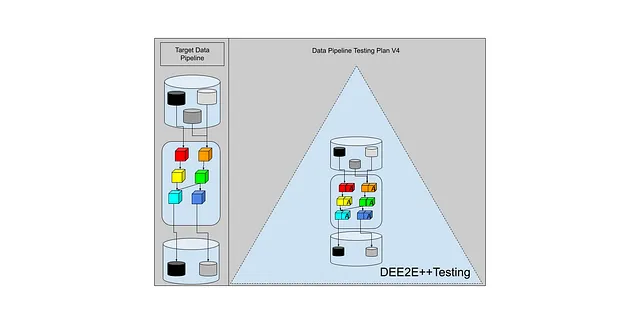
¿Cómo se vería eso en la venerada Pirámide de Pruebas?
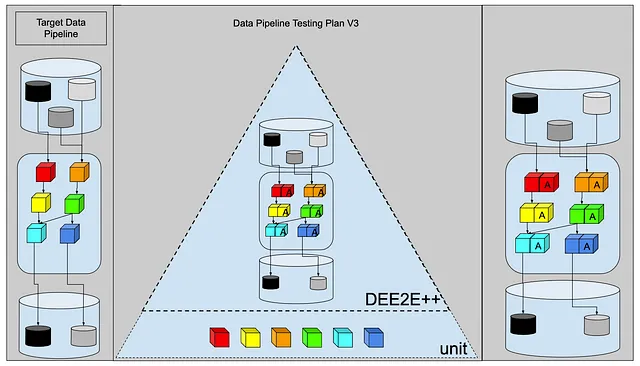
Llamémosle Pruebas DEE2E++. Pruebas de Ingeniería de Datos de Extremo a Extremo ++.
Parece haber dos variantes de las Pruebas DEE2E++:
- Capas Anti-Corrupción Ubicuas (U-ACL)
- Capa Anti-Corrupción Principalmente de Advertencias (MW-ACL)
En el lado Ubicuo, se ve así:
Cada transformación recibe una capa anti-corrupción de entrada que la protege de cambios aguas arriba, y una capa anti-corrupción de salida que protege a los consumidores aguas abajo de los cambios internos de la transformación actual. Si algo cambia en el esquema o contenido de los datos aguas arriba, entonces la ACL de entrada detendrá el procesamiento e informará el error al usuario. Luego, si cambiamos algo en el esquema o contenido de la transformación actual, la ACL de salida también capturará los errores y detendrá el procesamiento.
Este es bastante trabajo para un ingeniero de datos principiante. Agregar reglas de validación obligatorias en cada transformación empujará al ingeniero de datos a hacer trabajo por lotes. En lugar de dividir el pipeline en múltiples pasos, dirán a sí mismos: “Si tengo que agregar estas ACLs para cada transformación, eso será el doble del número de transformaciones. Más vale que agregue solo dos. Una en la parte superior del pipeline y otra en la parte inferior. Me ocuparé de los detalles de las transformaciones por mi cuenta”. Ese es un enfoque inicial válido donde el foco está en 1) la lógica de ingestión de nivel superior y 2) las salidas de datos visibles para el cliente. El problema con esta estrategia es que perdemos los beneficios de las pruebas en cuanto a la localización de errores. Si hay un error en la transformación 4 de 6, las pruebas de ACL solo mostrarán que la salida final es inválida, no que la transformación 4 es la culpable.
Además, a medida que evolucionan las fuentes de datos, lo que estamos hablando aquí son 90% advertencias y 10% errores bloqueantes. Solo porque apareció una nueva columna en los datos de entrada no significa que todo el pipeline deba fallar. Y solo porque la media de distribución de alguna columna haya cambiado un poco no significa que todos los datos sean inválidos. Es posible que los clientes aún estén interesados en los datos más actualizados disponibles para tomar decisiones comerciales y hacer conciliaciones más adelante si es necesario.
Para eso, necesitas la “Capa Anti-Corrupción Mayormente de Advertencias”.
Notifica al desarrollador que algo está mal, pero no detiene el procesamiento. Cumple el mismo papel que las ACL de entrada y salida, pero para cada transformación. Además, es mucho más tolerante al cambio. Este tipo de ACL emite advertencias y métricas, y el desarrollador puede priorizar las advertencias más tarde. Si algo está completamente fuera de control, el desarrollador puede rellenar los datos después de corregir la transformación de datos.
Obviamente, puede variar. Si la salida del pipeline de datos actual tiene pocos usuarios humanos establecidos, entonces comunicarse con los consumidores ayudará al nuevo desarrollador a aprender sobre el dominio. Por otro lado, si este pipeline tiene una multitud de pipelines de datos automatizados establecidos que consumen la salida, entonces este método DEE2E++ de pruebas puede no ser suficiente. Sin embargo, es probable que los nuevos desarrolladores de datos que están comenzando no sean asignados desde el primer día a pipelines de datos críticos para el negocio que afecten a cientos de consumidores de datos. Entonces, en lugar de obligar a los nuevos desarrolladores de datos a verse aplastados por técnicas de prueba extranjeras y por dominios críticos para la misión, el método DEE2E++ puede ser un buen punto de partida para los nuevos desarrolladores de datos.
Aquí está el diagrama DEE2E++ nuevamente.
“Espera, espera, espera, ¿estás diciendo que cada componente solo va a tener una Capa Anti-Corrupción Mayormente de Advertencias?”
No “Solo-Advertencias”, “Mayormente-Advertencias”. Algunas de las afirmaciones ciertamente detendrán el procesamiento y fallarán el trabajo. Pero sí, esa es la idea. Si haces la estrategia de “Capa Anti-Corrupción Ubicua”, entonces necesitarás más tiempo. A medida que el dominio se aclare, puedes agregar ACLs más estrictas alrededor de piezas críticas del pipeline de datos. Esta comprensión del dominio ayudará a clasificar las transformaciones en términos de complejidad. A medida que identifiques las más complejas que necesitan cuidado adicional, puedes pasar de las “MW-ACLs” a las “U-ACLs” para proteger la lógica de negocio altamente crítica, por ejemplo.
“Quiero decir, sí, pero entonces, ¿por qué molestarse con las pruebas unitarias? ¿No están cubiertas en las pruebas en línea?”
Claro, está bien, eliminémoslas.
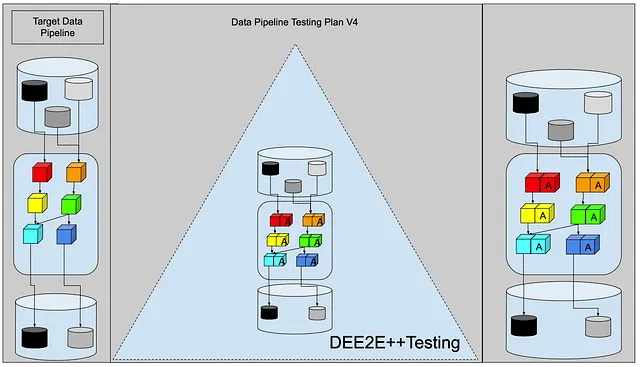
¿De acuerdo? Supongo que todos podemos volver al trabajo ahora.
Conclusión
En resumen, los principios comunes del desarrollo basado en pruebas pueden ser bastante abrumadores para un nuevo ingeniero de datos. Es importante recordar que TDD es una herramienta de diseño, no una ley. Úsala sabiamente y te servirá bien. Pero úsala demasiado y te encontrarás en un mundo de problemas.
En este artículo examinamos lo que puede suceder con las pruebas demasiado especificadas. Primero, tomamos una tubería de datos aparentemente simple y vimos qué sucede cuando caemos en la trampa de los “Caminos exhaustivos de múltiples fuentes y múltiples destinos”. Luego observamos cómo las pruebas de integración son solo la punta del iceberg en comparación con las pruebas centradas en los datos. Finalmente, descubrimos que un buen punto de partida para los ingenieros de datos principiantes es centrarse en las pruebas de extremo a extremo con “Capas de antifalsificación principalmente advertencias” como pruebas en línea. Esta estrategia de pruebas DEE2E++ tiene dos beneficios. En primer lugar, el ingeniero de datos novato no renunciará a las pruebas desde el primer día. En segundo lugar, les da a los desarrolladores margen de maniobra para aprender sobre el dominio e iterar el diseño de su tubería de datos utilizando sus conocimientos básicos existentes de ingeniería de datos. En lugar de perderse de inmediato en el micronivel de TDD, pueden entregar software funcional a las partes interesadas y luego basarse en la protección que proporciona la prueba DEE2E++ para agregar pruebas más detalladas a medida que evolucionen los requisitos.
Así que ahí lo tienes. Los peligros del desarrollo basado en pruebas. Espero que los evites todos y que tus tuberías de datos siempre estén en buen estado.
¿Quieres aprender más sobre técnicas de pruebas de tuberías de datos modernas?
Revisa mi último libro sobre el tema. Este libro ofrece una guía visual de las técnicas más populares para probar tuberías de datos modernas.
Enlace del libro 2023:
Enlace del libro: Técnicas de Pruebas de Tuberías de Datos Modernas en leanpub.
¡Nos vemos!
Aviso legal: Las opiniones expresadas en esta publicación son mías y no necesariamente reflejan las opiniones de mis empleadores actuales o anteriores.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Cómo convertí una base de datos relacional regular en una base de datos vectorial para almacenar incrustaciones
- Investigadores de la Universidad de Pekín presentan ChatLaw un modelo de lenguaje legal de código abierto de gran tamaño con bases de conocimientos externas integradas.
- 5 Idiomas mejor pagados para aprender este año
- Investigadores de Stanford presentan HyenaDNA un modelo genómico de base de largo alcance con longitudes de contexto de hasta 1 millón de tokens a una resolución de nucleótido único.
- Aprendizaje Automático Hecho Intuitivo
- Guía para principiantes para construir tus propios modelos de lenguaje grandes desde cero.
- Simplifica la creación y mantenimiento de DAG en Airflow con Hamilton en 8 minutos






