Pic2Word Mapeo de imágenes a palabras para la recuperación de imágenes compuestas sin entrenamiento previo.
Pic2Word Mapeo de imágenes a palabras para la recuperación de imágenes compuestas sin entrenamiento previo.
Publicado por Kuniaki Saito, Investigador Estudiantil, Investigación de Google, Equipo de IA en la Nube, y Kihyuk Sohn, Científico Investigador, Investigación de Google
La recuperación de imágenes juega un papel crucial en los motores de búsqueda. Por lo general, los usuarios confían en imágenes o texto como consulta para recuperar una imagen objetivo deseada. Sin embargo, la recuperación basada en texto tiene sus limitaciones, ya que describir la imagen objetivo con precisión utilizando palabras puede ser un desafío. Por ejemplo, al buscar un artículo de moda, los usuarios pueden querer un artículo cuyo atributo específico, como el color de un logotipo o el logotipo en sí, sea diferente de lo que encuentran en un sitio web. Sin embargo, buscar el artículo en un motor de búsqueda existente no es trivial, ya que describir con precisión el artículo de moda mediante texto puede ser desafiante. Para abordar este hecho, la recuperación de imágenes compuestas (CIR, por sus siglas en inglés) recupera imágenes basadas en una consulta que combina tanto una imagen como una muestra de texto que proporciona instrucciones sobre cómo modificar la imagen para que se ajuste al objetivo de recuperación previsto. Por lo tanto, CIR permite la recuperación precisa de la imagen objetivo mediante la combinación de imagen y texto.
Sin embargo, los métodos de CIR requieren grandes cantidades de datos etiquetados, es decir, tripletes de 1) imagen de consulta, 2) descripción y 3) imagen objetivo. La recopilación de estos datos etiquetados es costosa y los modelos entrenados con estos datos a menudo están adaptados a casos de uso específicos, lo que limita su capacidad para generalizar a diferentes conjuntos de datos.
Para abordar estos desafíos, en “Pic2Word: Mapeo de imágenes a palabras para la recuperación de imágenes compuestas sin etiquetas”, proponemos una tarea llamada recuperación de imágenes compuestas sin etiquetas (ZS-CIR, por sus siglas en inglés). En ZS-CIR, nuestro objetivo es construir un único modelo de CIR que realice una variedad de tareas de CIR, como composición de objetos, edición de atributos o conversión de dominio, sin requerir datos etiquetados de tripletes. En cambio, proponemos entrenar un modelo de recuperación utilizando pares de imágenes y subtítulos a gran escala y imágenes sin etiquetar, que son considerablemente más fáciles de recopilar que los conjuntos de datos de CIR supervisados a gran escala. Para fomentar la reproducibilidad y avanzar en este espacio, también lanzamos el código.
- La IA combate la plaga de los desechos espaciales
- Fiber Óptica Pantalones Inteligentes Ofrecen una Forma de Bajo Costo para Monitorear Movimientos
- Cómo hacer gráficos, diagramas y diagramas con ChatGPT
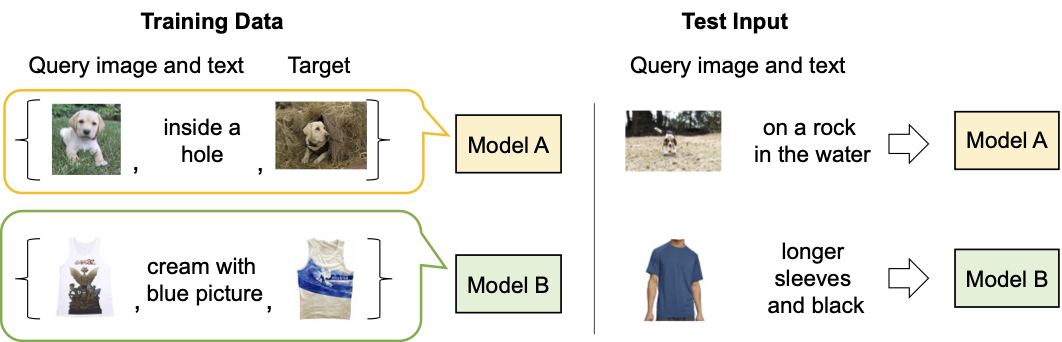 |
| Descripción del modelo de recuperación de imágenes compuestas existente. |
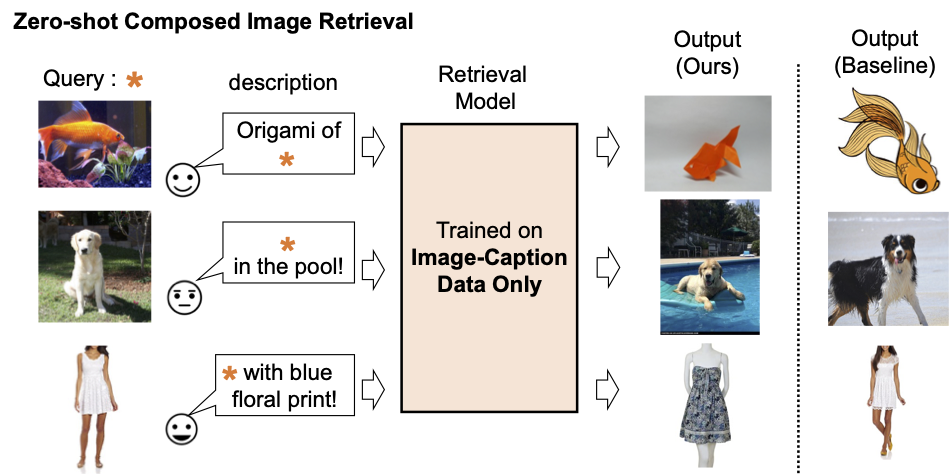 |
| Entrenamos un modelo de recuperación de imágenes compuestas utilizando solo datos de imágenes y subtítulos. Nuestro modelo recupera imágenes alineadas con la composición de la imagen de consulta y el texto. |
Descripción general del método
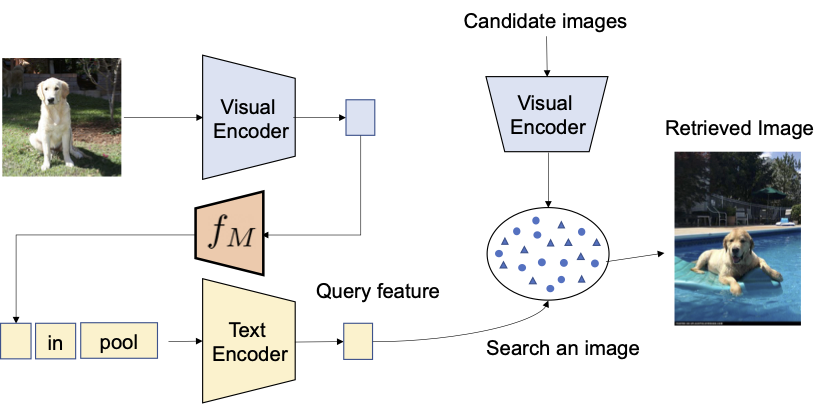
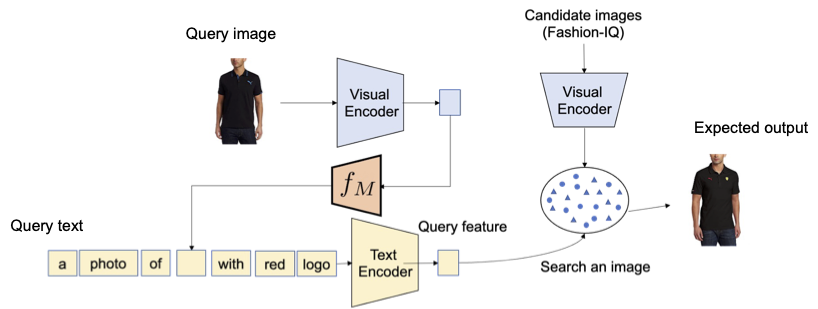
Proponemos aprovechar las capacidades lingüísticas del codificador de lenguaje en el modelo pre-entrenado de lenguaje-imagen contrastivo (CLIP, por sus siglas en inglés), que sobresale en la generación de incrustaciones de lenguaje semánticamente significativas para una amplia gama de conceptos y atributos textuales. Con ese fin, utilizamos un submódulo de mapeo ligero en CLIP que está diseñado para mapear una imagen de entrada (por ejemplo, una foto de un gato) desde el espacio de incrustación de imágenes a un token de palabra (por ejemplo, “gato”) en el espacio de entrada textual. Se optimiza toda la red con la pérdida contrastiva de visión-lenguaje para garantizar que los espacios de incrustación visual y de texto estén lo más cerca posible dado un par de una imagen y su descripción textual. Luego, la imagen de consulta se puede tratar como si fuera una palabra. Esto permite la composición flexible y sin problemas de las características de la imagen de consulta y las descripciones de texto mediante el codificador de lenguaje. Llamamos a nuestro método Pic2Word y proporcionamos una descripción general de su proceso de entrenamiento en la figura siguiente. Queremos que el token mapeado s represente la imagen de entrada en forma de token de palabra. Luego, entrenamos la red de mapeo para reconstruir la incrustación de la imagen en la incrustación de lenguaje, p. Específicamente, optimizamos la pérdida contrastiva propuesta en CLIP calculada entre la incrustación visual v y la incrustación textual p.
 |
| Entrenamiento de la red de mapeo ( f M ) utilizando solo imágenes sin etiquetar. Optimizamos solo la red de mapeo con un codificador visual y de texto congelado. |
Dado el mapeo de red entrenado, podemos considerar una imagen como un token de palabra y combinarlo con la descripción de texto para componer de manera flexible la consulta conjunta de imagen-texto como se muestra en la figura a continuación.
 |
| Con la red de mapeo entrenada, consideramos la imagen como un token de palabra y la combinamos con la descripción de texto para componer de manera flexible la consulta conjunta de imagen-texto. |
Evaluación
Realizamos una variedad de experimentos para evaluar el rendimiento de Pic2Word en una variedad de tareas de CIR.
Conversión de dominio
Primero evaluamos la capacidad de composicionalidad del método propuesto en la conversión de dominio: dada una imagen y el nuevo dominio de imagen deseado (por ejemplo, escultura, origami, dibujos animados, juguetes), la salida del sistema debe ser una imagen con el mismo contenido pero en el nuevo dominio o estilo de imagen deseado. Como se ilustra a continuación, evaluamos la capacidad de componer la información de categoría y la descripción del dominio dadas como imagen y texto, respectivamente. Evaluamos la conversión de imágenes reales a cuatro dominios utilizando ImageNet y ImageNet-R.
Para comparar con enfoques que no requieren datos de entrenamiento supervisado, seleccionamos tres enfoques: (i) solo imagen realiza la recuperación solo con la incrustación visual, (ii) solo texto utiliza solo la incrustación de texto y (iii) imagen + texto promedia la incrustación visual y de texto para componer la consulta. La comparación con (iii) muestra la importancia de componer imagen y texto utilizando un codificador de lenguaje. También comparamos con Combiner, que entrena el modelo de CIR en Fashion-IQ o CIRR.
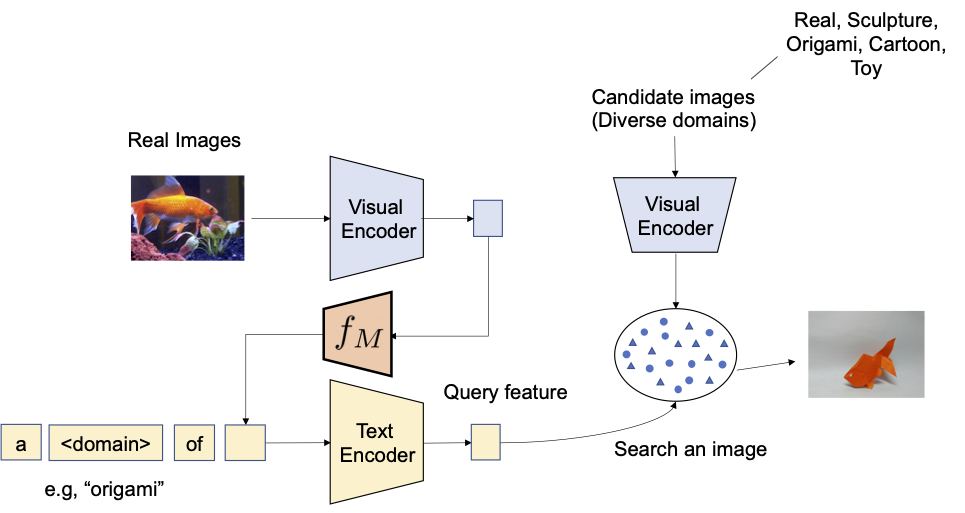 |
| Nuestro objetivo es convertir el dominio de la imagen de consulta en el descrito con texto, por ejemplo, origami. |
Como se muestra en la figura a continuación, nuestro enfoque propuesto supera a las líneas de base por un amplio margen.
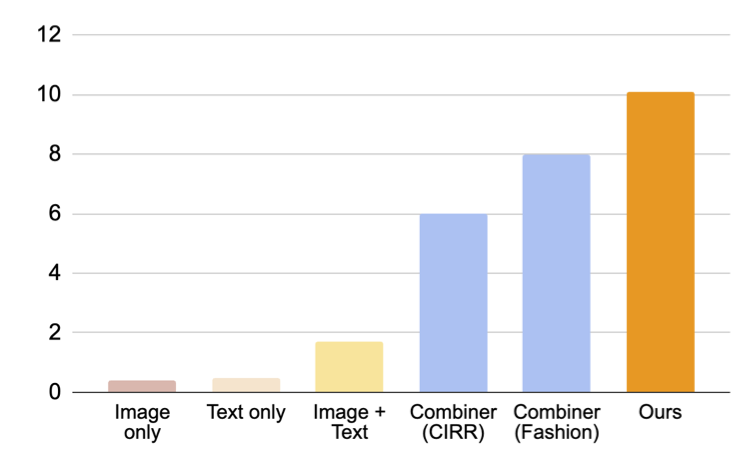 |
| Resultados (recall @10, es decir, el porcentaje de instancias relevantes en las primeras 10 imágenes recuperadas) en la recuperación de imágenes compuestas para la conversión de dominio. |
Composición de atributos de moda
A continuación, evaluamos la composición de atributos de moda, como el color de la tela, el logotipo y la longitud de la manga, utilizando el conjunto de datos Fashion-IQ. La figura a continuación ilustra la salida deseada dada la consulta.
 |
| Visión general de CIR para atributos de moda. |
En la figura siguiente, presentamos una comparación con las líneas de base, incluidas las líneas de base supervisadas que utilizaron tripletas para entrenar el modelo CIR: (i) CB utiliza la misma arquitectura que nuestro enfoque, (ii) CIRPLANT, ALTEMIS, MAAF utilizan una columna vertebral más pequeña, como ResNet50. La comparación con estos enfoques nos dará una comprensión de qué tan bien funciona nuestro enfoque de cero disparo en esta tarea.
Aunque CB supera a nuestro enfoque, nuestro método funciona mejor que las líneas de base supervisadas con columnas vertebrales más pequeñas. Este resultado sugiere que al utilizar un modelo CLIP robusto, podemos entrenar un modelo CIR altamente efectivo sin requerir tripletas anotadas.
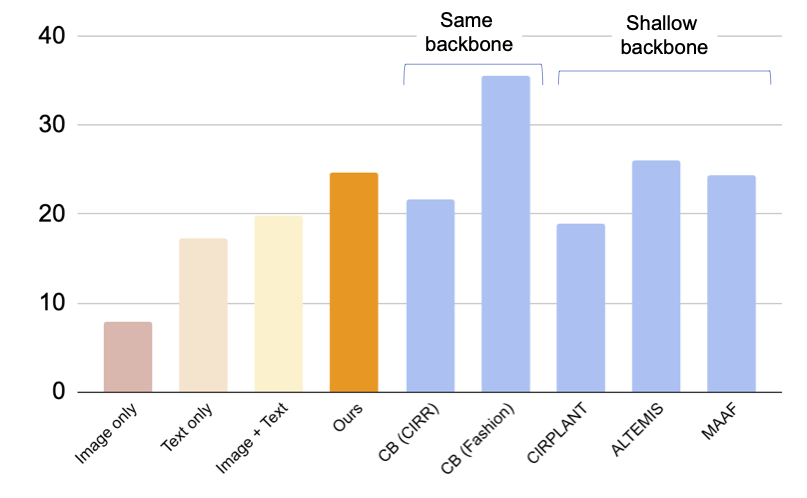 |
| Resultados (recall @10, es decir, el porcentaje de instancias relevantes en las primeras 10 imágenes recuperadas) en la recuperación de imágenes compuestas para el conjunto de datos Fashion-IQ (mayor es mejor). Las barras azul claro entrenan el modelo utilizando tripletas. Tenga en cuenta que nuestro enfoque tiene un rendimiento similar a estas líneas de base supervisadas con columnas vertebrales poco profundas (más pequeñas). |
Resultados cualitativos
Mostramos varios ejemplos en la figura siguiente. En comparación con un método de línea de base que no requiere datos de entrenamiento supervisados (promedio de características de texto + imagen), nuestro enfoque hace un mejor trabajo al recuperar correctamente la imagen objetivo.
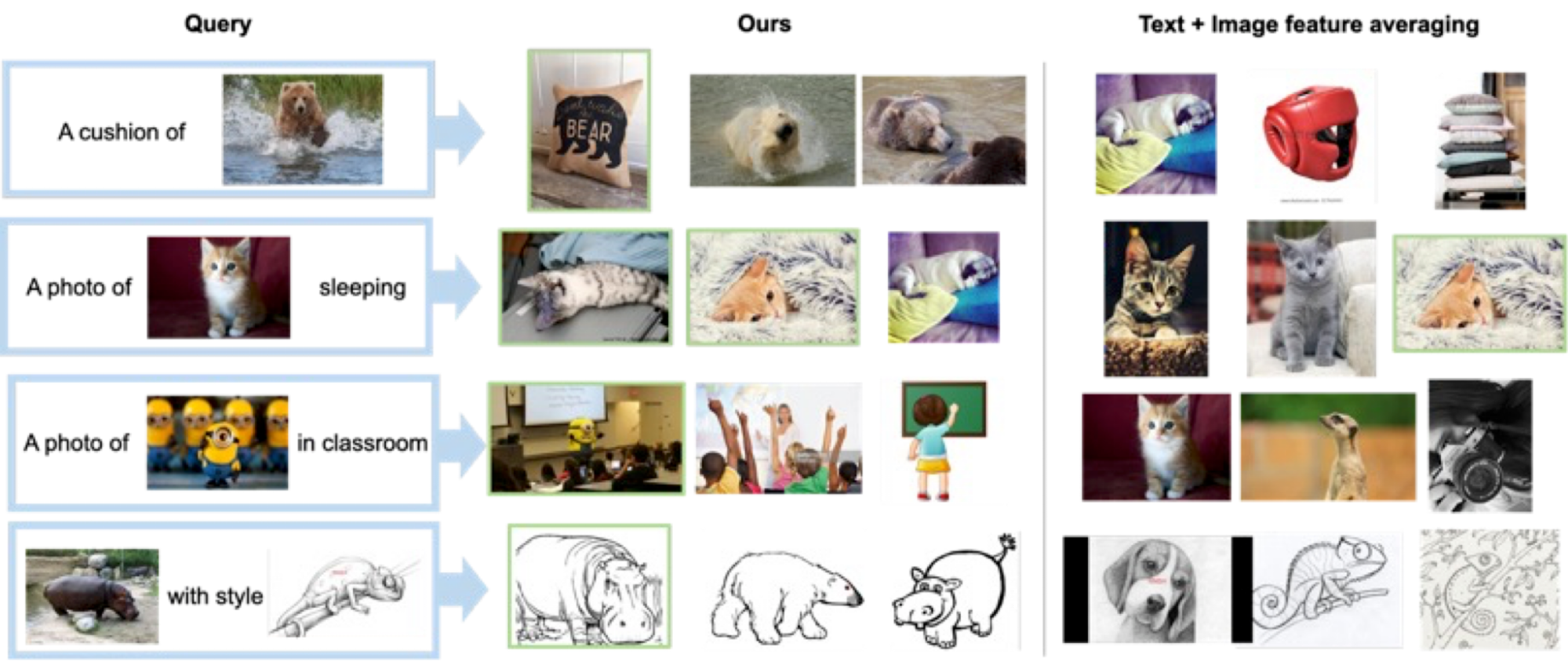 |
| Resultados cualitativos en diversas imágenes de consulta y descripciones de texto. |
Conclusión y trabajo futuro
En este artículo, presentamos Pic2Word, un método para mapear imágenes a palabras para ZS-CIR. Proponemos convertir la imagen en un token de palabra para lograr un modelo CIR utilizando solo un conjunto de datos de imágenes y leyendas. A través de una variedad de experimentos, verificamos la efectividad del modelo entrenado en diversas tareas de CIR, lo que indica que el entrenamiento en un conjunto de datos de imágenes y leyendas puede construir un modelo CIR potente. Una dirección futura de investigación potencial es utilizar datos de leyendas para entrenar la red de mapeo, aunque en el trabajo actual solo usamos datos de imágenes.
Agradecimientos
Esta investigación fue realizada por Kuniaki Saito, Kihyuk Sohn, Xiang Zhang, Chun-Liang Li, Chen-Yu Lee, Kate Saenko y Tomas Pfister. También agradecemos a Zizhao Zhang y Sergey Ioffe por sus valiosos comentarios.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Dominando la Interpretabilidad del Modelo Un Análisis Integral de los Gráficos de Dependencia Parcial
- People Analytics es lo nuevo y grande, y aquí te explicamos por qué debes conocerlo.
- Esta Investigación de IA Explica los Rasgos de Personalidad Sintéticos en los Modelos de Lenguaje de Gran Escala (LLMs)
- Aprendiendo Transformers Code First Parte 1 – La Configuración
- El diablo está en los detalles Conviértete en un campeón de Power BI pensando fuera de lo convencional.
- Evita estos 3 costosos errores y salva tus pruebas A/B.
- Intenciones de Código de IA






