Clasificación con el Perceptrón de Rosenblatt
Perceptrón de Rosenblatt' classification.
El “hola mundo” del aprendizaje automático
Recientemente estuve reflexionando sobre cuál podría ser la introducción más básica al aprendizaje automático. Buscaba una tarea simple, como la clasificación binaria, y un algoritmo lo suficientemente simple como para poder construirlo desde cero y explicarlo en un artículo corto. Si el algoritmo tenía cierta historia, mejor aún. No tardé mucho en encontrar al candidato: el perceptrón. El perceptrón nos lleva al comienzo del aprendizaje automático. Fue introducido por Frank Rosenblatt hace más de 60 años. Al igual que una neurona, la regla del perceptrón toma múltiples características de entrada y ajusta pesos que, cuando se multiplican por el vector de características de entrada, permiten tomar una decisión sobre si la neurona emite una señal o no, o en un contexto de clasificación de aprendizaje automático, si la salida es 0 o 1. El perceptrón es probablemente el clasificador binario más simple y no conozco ningún caso práctico de uso de aprendizaje automático que se pueda abordar con él en estos días. Sin embargo, tiene un valor educativo e histórico significativo, ya que allanó el camino hacia las redes neuronales.
El propósito de este artículo es presentar el perceptrón y usarlo en una tarea simple de clasificación binaria. El perceptrón se ha implementado en scikit-learn, pero en lugar de confiar en esto, lo construiremos desde cero. También crearemos un conjunto de visualizaciones para comprender cómo el algoritmo establece su límite de decisión y explorar su convergencia. El perceptrón es un modelo lineal que consta de pesos y un término de sesgo que se ajustan simultáneamente e iterativamente durante el proceso de ajuste. Sin embargo, no tiene una función de pérdida continua como su tal vez sucesor inmediato en la historia del aprendizaje automático, el algoritmo de neurona lineal adaptativa (Adaline), que también es una red neuronal de una sola capa. El ajuste del perceptrón simplemente se basa en detectar muestras clasificadas incorrectamente y los pesos y el sesgo se actualizan inmediatamente tan pronto como ocurra una muestra clasificada incorrectamente y no una vez por época (época siendo un pase completo por el conjunto de entrenamiento). Por lo tanto, el algoritmo ni siquiera necesita un optimizador. Me atrevería a decir que es tan simple y elegante que se vuelve hermoso. Si tienes curiosidad por ver cómo funciona, ¡mantente atento!
Teoría del perceptrón
El perceptrón, al igual que otros modelos lineales, utiliza un conjunto de pesos, uno para cada una de las características, y para generar una predicción calcula el producto escalar de los pesos y los valores de las características y agrega un sesgo
- Temas por Clase Utilizando BERTopic
- Esta investigación de IA presenta Point-Bind un modelo de multimodalidad 3D que alinea nubes de puntos con imágenes 2D, lenguaje, audio y video
- Los programas piloto de IA buscan reducir el consumo de energía y las emisiones en el campus del MIT
El resultado de esta función lineal, que también se conoce como entrada neta, se introduce en una función de activación f(z) que, en el caso del perceptrón, es una función de paso simple, es decir, f(z) toma el valor de 1 si z≥0 y 0 en caso contrario. El papel de la función de activación es mapear la entrada neta a dos valores, a saber, 0 y 1. Básicamente, lo que hemos hecho no es más que definir un hiperplano. Los puntos que están en el mismo lado del hiperplano pertenecen a la misma clase. Los pesos definen el vector vertical al hiperplano, es decir, la orientación del hiperplano, y el sesgo la distancia del hiperplano al origen. Cuando comienza el proceso de ajuste, tenemos un hiperplano orientado al azar a una distancia aleatoria del origen. Cada vez que encontramos una muestra clasificada incorrectamente, movemos ligeramente el hiperplano y cambiamos su orientación y posición para que en la próxima época la muestra esté en el lado correcto del hiperplano. Podemos decidir cuánto mover el hiperplano, es decir, cuál debe ser la tasa de aprendizaje.
Por lo general, necesitamos pasar por todas las muestras varias veces (épocas) hasta que ningún punto esté clasificado incorrectamente, o para ser más precisos, hasta que no se pueda hacer más progreso. En cada época, recorremos todas las muestras i = 1,.., nₛₐₘₚₗₑₛ en el conjunto de entrenamiento y utilizando los pesos y el sesgo actuales examinamos si el modelo clasifica incorrectamente y si lo hace, actualizamos todos los pesos j=1,.., nfₑₐₜᵤᵣₑₛ utilizando una tasa de aprendizaje η:
donde
con sombrero indicando la salida de predicción. También actualizamos el sesgo con
donde
Es fácil ver conceptualmente por qué hacemos estas operaciones. Supongamos que el modelo predice la clase 0, mientras que la correcta es 1. Si xⱼ es positivo, entonces el peso se incrementará para que la entrada neta aumente. Si xⱼ es negativo, entonces el peso se reducirá para que la entrada neta aumente una vez más (independientemente del signo del peso). De manera similar, el sesgo se incrementará, lo que conducirá a mayores aumentos de la entrada neta. Con estos cambios, es más probable predecir la clase correcta para la muestra clasificada incorrectamente en la próxima época. La lógica es similar cuando el modelo predice la clase 1, mientras que la correcta es 0, con la única diferencia de que todos los signos están invertidos.
Si te fijas bien, los pesos y el sesgo pueden actualizarse varias veces dentro de la misma época, una vez por cada muestra clasificada incorrectamente. Cada clasificación errónea reorienta y reposiciona el hiperplano del límite de decisión para que la muestra se prediga correctamente en la próxima época.
Preparación de datos
Utilizaremos un conjunto de datos sintético que comprende dos distribuciones gaussianas. El perceptrón se puede utilizar con características de cualquier dimensión, pero con fines de este artículo, nos limitaremos a dos dimensiones para facilitar la visualización.
que produce la siguiente figura
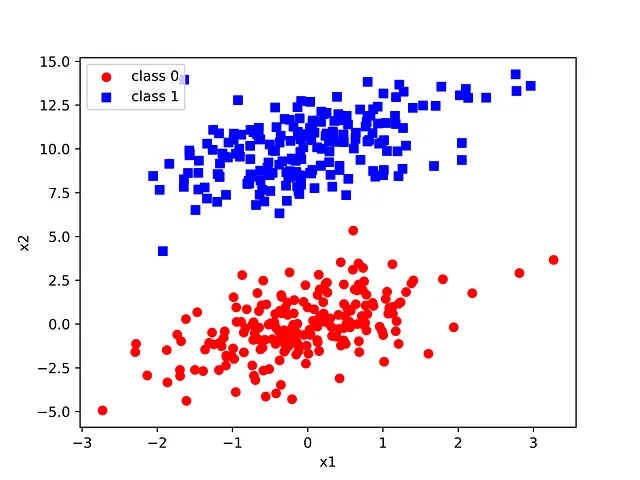
Las dos distribuciones gaussianas están alargadas y separadas a propósito eligiendo medias y covarianzas apropiadas. Volveremos a esto más adelante.
Implementación y uso del perceptrón
A continuación se muestra la implementación del perceptrón. Utilizamos el estilo de scikit-learn para iniciar el modelo, ajustarlo y finalmente realizar una predicción
El método de inicialización establece la tasa de aprendizaje, el número máximo de iteraciones y la semilla del generador de números aleatorios para fines de reproducibilidad. El método de ajuste crea un generador de números aleatorios que luego se utiliza para establecer los pesos en algunos números pequeños muestreados de una distribución uniforme, mientras que el sesgo se inicia en cero. Luego iteramos durante un número máximo de épocas. Para cada época contamos el número de clasificaciones incorrectas para poder monitorear la convergencia y finalizar temprano si es posible. Para cada muestra que se clasifica incorrectamente, actualizamos los pesos y el sesgo como se describe en la sección anterior. Si el número de clasificaciones incorrectas es cero, entonces no se pueden realizar más mejoras y, por lo tanto, no es necesario continuar con la siguiente época. El método de predicción simplemente calcula el producto punto de los pesos y los valores de las características, agrega el sesgo y aplica la función de paso.
Si utilizamos la clase Perceptron anterior con el conjunto de datos sintético
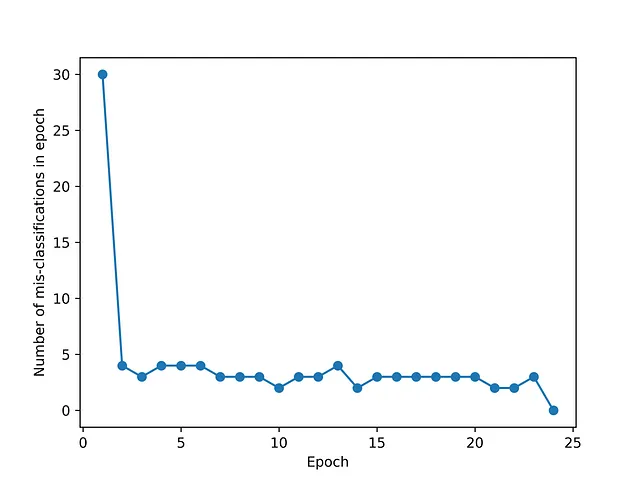
podemos ver que se logró la convergencia en 24 épocas, es decir, no fue necesario agotar el número máximo de épocas especificado
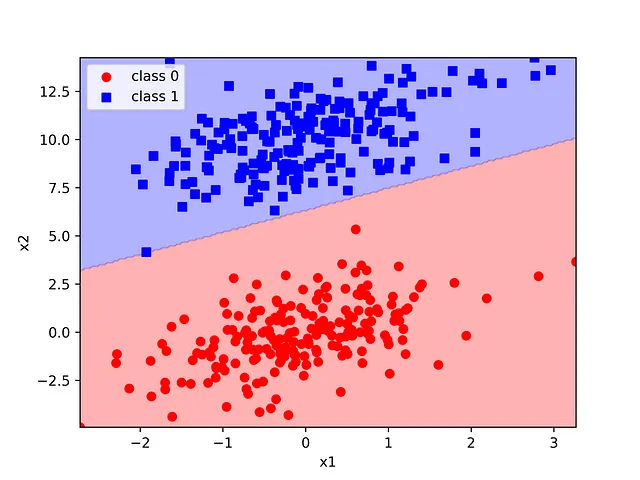
El límite de decisión se puede visualizar fácilmente utilizando la función de utilidad del límite de decisión de scikit-learn. Para usar esta función, generamos una cuadrícula de 200×200 puntos que abarca el rango de valores de características en el conjunto de entrenamiento. Básicamente construimos un gráfico de contorno con la clase predicha y superponemos las muestras como un diagrama de dispersión coloreado utilizando las etiquetas reales. Esta forma de trazar el límite de decisión es bastante genérica y puede ser útil con cualquier clasificador bidimensional.
Las dos distribuciones gaussianas construidas sintéticamente se han separado perfectamente utilizando un modelo que podría ser codificado desde cero en pocas líneas de código. La simplicidad y elegancia de este método lo convierten en un ejemplo introductorio y motivador brillante para el aprendizaje automático.
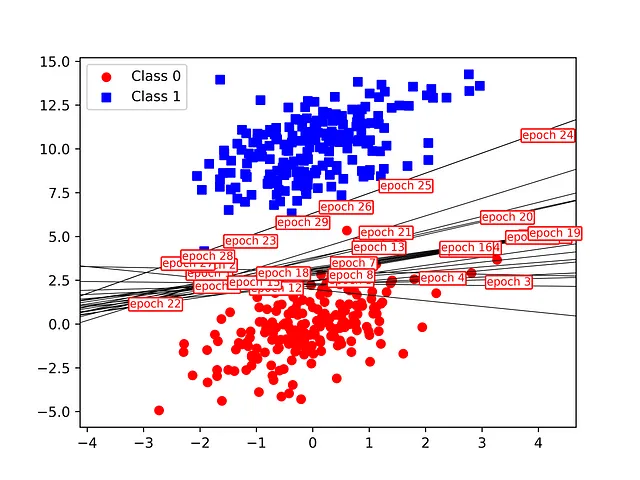
También podemos visualizar la evolución del límite de decisión en las diferentes épocas deteniendo prematuramente el proceso de ajuste del modelo. Esto se puede hacer en la práctica ajustando el modelo utilizando un límite creciente para el número máximo de épocas. Para cada intento, utilizamos los pesos y el sesgo del modelo ajustado (posiblemente no convergido) y trazamos el límite de decisión como una línea. Las líneas están etiquetadas con el número de época. Esto podría haberse implementado de manera más elegante utilizando un inicio rápido, pero el ajuste del modelo es muy rápido y, por lo tanto, no vale la pena la complejidad adicional.
La evolución del límite de decisión para las diversas épocas se muestra en la siguiente figura. Inicialmente, se clasifica incorrectamente un pequeño número de muestras de la clase 0, lo que provoca cambios graduales en la pendiente e intersección de la línea del límite de decisión. Podemos ver que se logró la convergencia en 24 épocas, lo cual es consistente con la figura de convergencia anterior. El ajuste se detiene una vez que el límite de decisión logra una separación perfecta de las clases, independientemente de qué tan cerca esté el límite de las muestras en su vecindad.
Algunas notas de precaución. La convergencia del perceptrón no puede darse por sentada, por lo que es importante establecer un número máximo de iteraciones. De hecho, se puede demostrar matemáticamente que la convergencia está garantizada para clases linealmente separables. Si las clases no son linealmente separables, los pesos y el sesgo seguirán siendo actualizados hasta que se alcance el número máximo de iteraciones. Es por eso que las dos gaussianas se movieron más lejos en el conjunto de datos sintético.
Otra nota importante es que el perceptrón no tiene una solución única. Típicamente, habrá un número infinito de hiperplanos que pueden separar clases linealmente separables y el modelo convergerá aleatoriamente a uno de ellos. Esto también significa que medir la distancia desde el límite de decisión no es determinista y, por lo tanto, no es tan útil. Las máquinas de vectores de soporte abordan esta limitación.
El perceptrón es esencialmente una red neuronal de una sola capa. Comprender cómo funciona es útil antes de pasar a redes neuronales multicapa y al algoritmo de retropropagación que se puede utilizar para problemas no lineales.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Implementar un índice de búsqueda inteligente de documentos con Amazon Textract y Amazon OpenSearch
- Primera parte del cuerpo humano derivada 3D impresa en el espacio
- Mejores prácticas de automatización de pruebas
- Cómo optimizar conjuntos de características con algoritmos genéticos
- Cómo la plataforma de VAST Data está eliminando las barreras a la innovación en IA
- DeepFace para reconocimiento facial avanzado
- El problema de los dos sobres






