PatchTST Un avance en la predicción de series temporales.
'PatchTST un avance en predicción de series temporales.'
Desde la teoría hasta la práctica, entendiendo el algoritmo PatchTST y aplicándolo en Python junto a N-BEATS y N-HiTS
Los modelos basados en transformadores se han aplicado con éxito en muchos campos como el procesamiento del lenguaje natural (piense en los modelos BERT o GPT) y la visión por computadora, por nombrar algunos.
Sin embargo, cuando se trata de series temporales, los resultados más avanzados se han logrado principalmente con modelos MLP (perceptrón multicapa) como N-BEATS y N-HiTS. Incluso un artículo reciente muestra que los modelos de pronóstico basados en transformadores complejos son superados por modelos lineales simples en muchos conjuntos de datos de referencia (consulte Zheng et al., 2022).
Sin embargo, se ha propuesto un nuevo modelo basado en transformadores que logra resultados de vanguardia para tareas de pronóstico a largo plazo: PatchTST.
PatchTST significa transformador de series temporales por parches, y fue propuesto por primera vez en marzo de 2023 por Nie, Nguyen et al. en su artículo: A Time Series is Worth 64 Words: Long-Term Forecasting with Transformers. Su método propuesto logró resultados de vanguardia en comparación con otros modelos basados en transformadores.
- Ciencia de Datos Retro Probando las Primeras Versiones de YOLO
- Cómo acceder a futuras versiones de Python como la 3.12 antes que las masas.
- Para aprender realmente un nuevo tema, tómate tu tiempo.
En este artículo, primero exploramos el funcionamiento interno de PatchTST, utilizando la intuición y sin ecuaciones. Luego, aplicamos el modelo en un proyecto de pronóstico y comparamos su rendimiento con modelos MLP, como N-BEATS y N-HiTS, y evaluamos su rendimiento.
Por supuesto, para más detalles sobre PatchTST, asegúrese de consultar el artículo original.
Aprenda las últimas técnicas de análisis de series temporales con mi hoja de trucos gratuita de series temporales en Python. ¡Obtenga la implementación de técnicas estadísticas y de aprendizaje profundo, todo en Python y TensorFlow!
¡Comencemos!
Explorando PatchTST
Como se mencionó, PatchTST significa transformador de series temporales por parches.
Como sugiere el nombre, utiliza parches y la arquitectura de transformadores. También incluye la independencia del canal para tratar series temporales multivariadas. La arquitectura general se muestra a continuación.
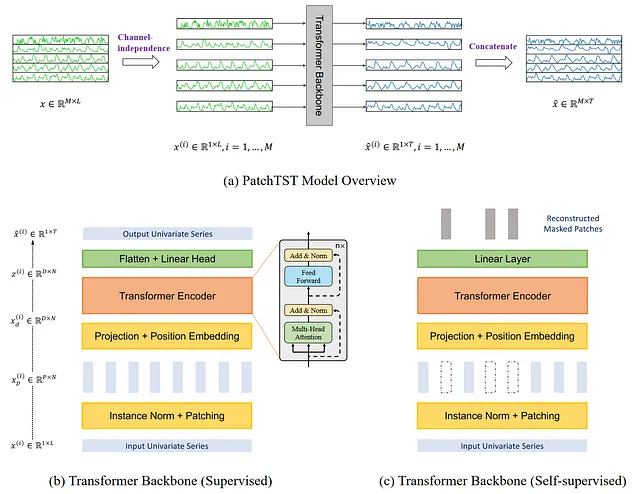
Hay mucha información para recopilar de la figura anterior. Aquí, los elementos clave son que PatchTST utiliza la independencia del canal para pronosticar series temporales multivariadas. Luego, en su núcleo de transformador, el modelo utiliza parches, que se ilustran mediante los pequeños rectángulos verticales. Además, el modelo viene en dos versiones: supervisado y auto-supervisado.
Exploraremos con más detalle la arquitectura y el funcionamiento interno de PatchTST.
Independencia del canal
Aquí, una serie temporal multivariada se considera como una señal multicanal. Cada serie temporal es básicamente un canal que contiene una señal.
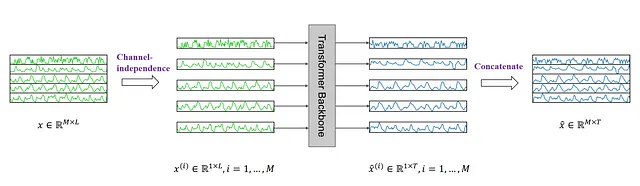
En la figura de arriba, vemos cómo una serie temporal multivariante se separa en series individuales, y cada una se alimenta al esqueleto de Transformer como un token de entrada. Luego, se hacen predicciones para cada serie y los resultados se concatenan para las predicciones finales.
Patching
La mayoría del trabajo en modelos de pronóstico basados en Transformers se centró en construir nuevos mecanismos para simplificar el mecanismo de atención original. Sin embargo, todavía dependían de la atención punto a punto, que no es ideal cuando se trata de series de tiempo.
En el pronóstico de series de tiempo, queremos extraer relaciones entre los pasos de tiempo pasados y los pasos de tiempo futuros para hacer predicciones. Con la atención punto a punto, intentamos recuperar información de un solo paso de tiempo, sin mirar lo que rodea ese punto. En otras palabras, aislamos un paso de tiempo y no miramos los puntos anteriores o posteriores.
Esto es como tratar de entender el significado de una palabra sin mirar las palabras que la rodean en una oración.
Por lo tanto, PatchTST utiliza el patching para extraer información semántica local en series de tiempo.
Cómo funciona el patching
Cada serie de entrada se divide en parches, que son simplemente series más cortas que provienen de la original.

Aquí, el parche puede ser superpuesto o no superpuesto. El número de parches depende de la longitud del parche P y el paso S. Aquí, el paso es como en una convolución, simplemente es cuántos pasos de tiempo separan el comienzo de los parches consecutivos.
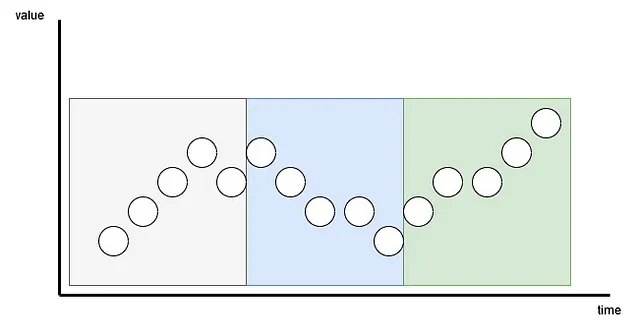
En la figura de arriba, podemos visualizar el resultado del patching. Aquí, tenemos una longitud de secuencia (L) de 15 pasos de tiempo, con una longitud de parche (P) de 5 y un paso (S) de 5. El resultado es que la serie se separa en 3 parches.
Ventajas del patching
Con el patching, el modelo puede extraer significado semántico local al mirar grupos de pasos de tiempo, en lugar de mirar un solo paso de tiempo.
También tiene la ventaja añadida de reducir en gran medida el número de tokens que se alimentan al codificador Transformer. Aquí, cada parche se convierte en un token de entrada para ser introducido en el Transformer. De esta manera, podemos reducir el número de tokens de L a aproximadamente L/S.
De esta manera, reducimos en gran medida la complejidad de espacio y tiempo del modelo. Esto a su vez significa que podemos alimentar al modelo una secuencia de entrada más larga para extraer relaciones temporales significativas.
Por lo tanto, con el patching, el modelo es más rápido, ligero y puede tratar una secuencia de entrada más larga, lo que significa que potencialmente puede aprender más sobre la serie y hacer mejores pronósticos.
Codificador Transformer
Una vez que se parchea la serie, se alimenta al codificador Transformer. Esta es la arquitectura clásica del transformer. Nada fue modificado.
Luego, la salida se alimenta a una capa lineal y se hacen las predicciones.
Mejorando PatchTST con aprendizaje de representación
Los autores del artículo sugirieron otra mejora al modelo mediante el uso de aprendizaje de representación.
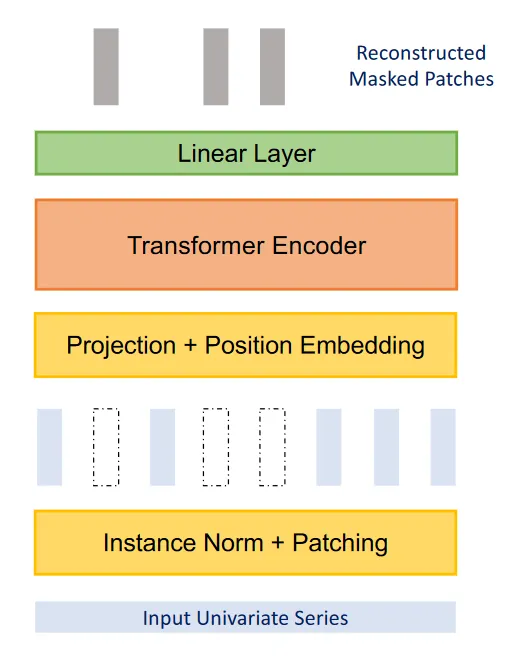
A partir de la figura anterior, podemos ver que PatchTST puede utilizar el aprendizaje de representación auto-supervisado para capturar representaciones abstractas de los datos. Esto puede llevar a posibles mejoras en el rendimiento de pronóstico.
Aquí, el proceso es bastante simple, ya que se enmascaran parches aleatorios, lo que significa que se establecerán en 0. Esto se muestra, en la figura anterior, mediante los rectángulos verticales en blanco. Luego, el modelo se entrena para recrear los parches originales, que es lo que se muestra en la parte superior de la figura, como los rectángulos verticales grises.
Ahora que tenemos una buena comprensión de cómo funciona PatchTST, probémoslo contra otros modelos y veamos cómo funciona.
Pronóstico con PatchTST
En el artículo, PatchTST se compara con otros modelos basados en Transformer. Sin embargo, se han publicado modelos recientes basados en MLP, como N-BEATS y N-HiTS, que también han demostrado un rendimiento de última generación en tareas de pronóstico a largo plazo.
El código fuente completo de esta sección está disponible en GitHub.
Aquí, apliquemos PatchTST, junto con N-BEATS y N-HiTS y evaluemos su rendimiento frente a estos dos modelos basados en MLP.
Para este ejercicio, utilizamos el conjunto de datos Exchange, que es un conjunto de datos de referencia común para el pronóstico a largo plazo en la investigación. El conjunto de datos contiene las tasas de cambio diarias de ocho países en relación al dólar estadounidense, desde 1990 hasta 2016. El conjunto de datos está disponible a través de la Licencia MIT.
Configuración inicial
Comencemos importando las bibliotecas necesarias. Aquí, trabajaremos con neuralforecast, ya que tienen una implementación lista para usar de PatchTST. Para el conjunto de datos, utilizamos la biblioteca datasetsforecast, que incluye todos los conjuntos de datos populares para la evaluación de algoritmos de pronóstico.
import torchimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom neuralforecast.core import NeuralForecastfrom neuralforecast.models import NHITS, NBEATS, PatchTSTfrom neuralforecast.losses.pytorch import MAEfrom neuralforecast.losses.numpy import mae, msefrom datasetsforecast.long_horizon import LongHorizonSi tiene CUDA instalado, entonces neuralforecast automáticamente aprovechará su GPU para entrenar los modelos. En mi caso, no lo tengo instalado, por lo que no estoy haciendo una sintonización de hiperparámetros extensiva, ni entrenando en conjuntos de datos muy grandes.
Una vez hecho esto, descarguemos el conjunto de datos Exchange.
Y_df, X_df, S_df = LongHorizon.load(directory="./data", group="Exchange")Aquí, vemos que obtenemos tres DataFrames. El primero contiene las tasas de cambio diarias para cada país. El segundo contiene series de tiempo exógenas. El tercero contiene variables exógenas estáticas (como el día, mes, año, hora o cualquier información futura que conozcamos).
Para este ejercicio, solo trabajamos con Y_df.
Luego, asegurémonos de que las fechas tengan el tipo correcto.
Y_df['ds'] = pd.to_datetime(Y_df['ds'])Y_df.head()
En la figura de arriba, vemos que tenemos tres columnas. La primera columna es un identificador único y es necesario tener una columna de id al trabajar con neuralforecast. Luego, la columna ds tiene la fecha, y la columna y tiene la tasa de cambio.
Y_df['unique_id'].value_counts()
A partir de la imagen anterior, podemos ver que cada id único corresponde a un país, y que tenemos 7588 observaciones por país.
Ahora, definimos los tamaños de nuestros conjuntos de validación y prueba. Aquí, elegí 760 pasos de tiempo para la validación, y 1517 para el conjunto de prueba, como se especifica en la biblioteca datasets.
val_size = 760test_size = 1517print(n_time, val_size, test_size)Luego, grafiquemos una de las series, para ver con qué estamos trabajando. Aquí, decidí graficar la serie para el primer país (unique_id = 0), pero siéntase libre de graficar otra serie.
u_id = '0'x_plot = pd.to_datetime(Y_df[Y_df.unique_id==u_id].ds)y_plot = Y_df[Y_df.unique_id==u_id].y.valuesx_plotx_val = x_plot[n_time - val_size - test_size]x_test = x_plot[n_time - test_size]fig, ax = plt.subplots(figsize=(12,8))ax.plot(x_plot, y_plot)ax.set_xlabel('Fecha')ax.set_ylabel('Tasa de cambio')ax.axvline(x_val, color='black', linestyle='--')ax.axvline(x_test, color='black', linestyle='--')plt.text(x_val, -2, 'Validación', fontsize=12)plt.text(x_test,-2, 'Prueba', fontsize=12)plt.tight_layout()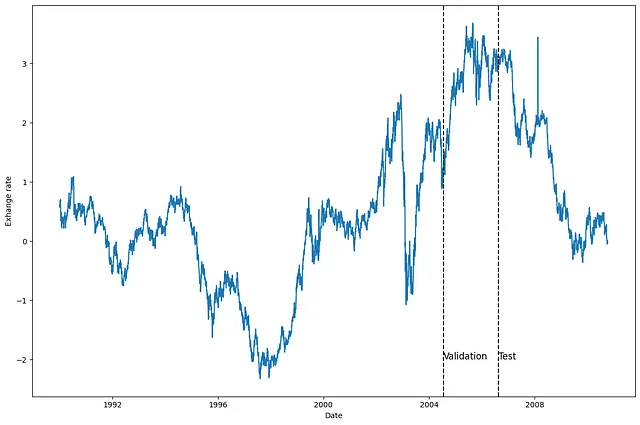
A partir de la figura anterior, vemos que tenemos datos bastante ruidosos sin una clara estacionalidad.
Modelado
Habiendo explorado los datos, comencemos el modelado con neuralforecast.
Primero, necesitamos establecer el horizonte. En este caso, uso 96 pasos de tiempo, ya que este horizonte también se utiliza en el documento de PatchTST.
Luego, para tener una evaluación justa de cada modelo, decidí establecer el tamaño de entrada al doble del horizonte (así que 192 pasos de tiempo), y establecer el número máximo de épocas en 50. Todos los demás hiperparámetros se mantienen en sus valores predeterminados.
horizon = 96models = [NHITS(h=horizon, input_size=2*horizon, max_steps=50), NBEATS(h=horizon, input_size=2*horizon, max_steps=50), PatchTST(h=horizon, input_size=2*horizon, max_steps=50)]Luego, inicializamos el objeto NeuralForecast, especificando los modelos que queremos usar y la frecuencia de la predicción, que en este caso es diaria.
nf = NeuralForecast(models=models, freq='D')Ahora estamos listos para hacer predicciones.
Pronóstico
Para generar predicciones, usamos el método cross_validation para aprovechar los conjuntos de validación y prueba. Devolverá un DataFrame con predicciones de todos los modelos y el valor verdadero asociado.
preds_df = nf.cross_validation(df=Y_df, val_size=val_size, test_size=test_size, n_windows=None)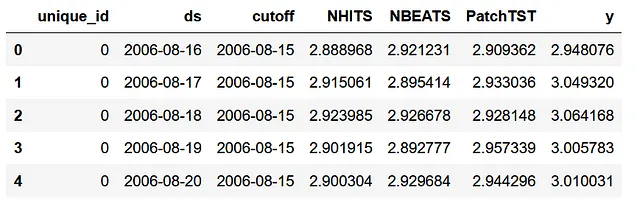
Como se puede observar, para cada id, tenemos las predicciones de cada modelo, así como el valor verdadero en la columna y.
Ahora, para evaluar los modelos, tenemos que remodelar las matrices de valores reales y predichos para tener la forma (número de series, número de ventanas, horizonte de pronóstico).
y_true = preds_df['y'].valuesy_pred_nhits = preds_df['NHITS'].valuesy_pred_nbeats = preds_df['NBEATS'].valuesy_pred_patchtst = preds_df['PatchTST'].valuesn_series = len(Y_df['unique_id'].unique())y_true = y_true.reshape(n_series, -1, horizon)y_pred_nhits = y_pred_nhits.reshape(n_series, -1, horizon)y_pred_nbeats = y_pred_nbeats.reshape(n_series, -1, horizon)y_pred_patchtst = y_pred_patchtst.reshape(n_series, -1, horizon)Una vez hecho esto, podemos opcionalmente graficar las predicciones de nuestros modelos. Aquí, graficamos las predicciones en la primera ventana de la primera serie.
fig, ax = plt.subplots(figsize=(12,8))ax.plot(y_true[0, 0, :], label='Verdadero')ax.plot(y_pred_nhits[0, 0, :], label='N-HiTS', ls='--')ax.plot(y_pred_nbeats[0, 0, :], label='N-BEATS', ls=':')ax.plot(y_pred_patchtst[0, 0, :], label='PatchTST', ls='-.')ax.set_ylabel('Tasa de cambio')ax.set_xlabel('Horizonte de pronóstico')ax.legend(loc='best')plt.tight_layout()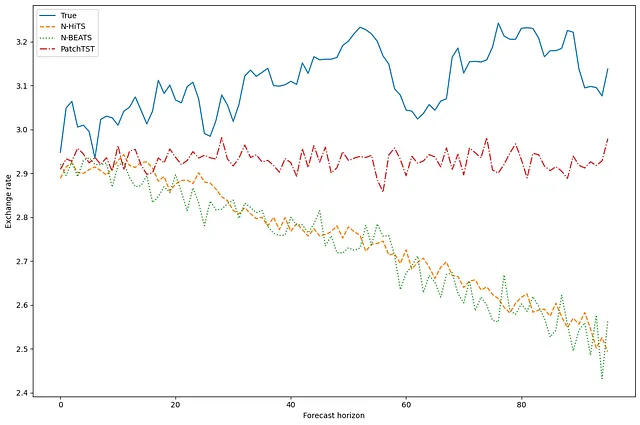
Esta figura es un poco decepcionante, ya que N-BEATS y N-HiTS parecen tener predicciones que están muy alejadas de los valores reales. Sin embargo, PatchTST, aunque también está alejado, parece ser el más cercano a los valores reales.
Por supuesto, debemos tomar esto con precaución, porque solo estamos visualizando la predicción para una serie, en una ventana de predicción.
Evaluación
Entonces, evaluemos el rendimiento de cada modelo. Para replicar la metodología del artículo, utilizamos tanto el MAE como el MSE como métricas de rendimiento.
data = {'N-HiTS': [mae(y_pred_nhits, y_true), mse(y_pred_nhits, y_true)], 'N-BEATS': [mae(y_pred_nbeats, y_true), mse(y_pred_nbeats, y_true)], 'PatchTST': [mae(y_pred_patchtst, y_true), mse(y_pred_patchtst, y_true)]}metrics_df = pd.DataFrame(data=data)metrics_df.index = ['mae', 'mse']metrics_df.style.highlight_min(color='lightgreen', axis=1)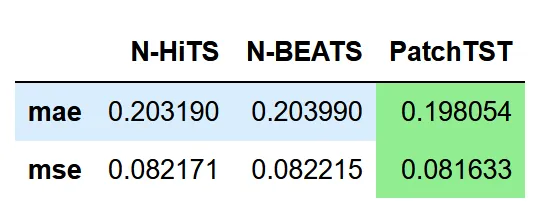
En la tabla anterior, vemos que PatchTST es el modelo campeón ya que logra el MAE y MSE más bajos.
Por supuesto, este no fue el experimento más exhaustivo, ya que solo usamos un conjunto de datos y un horizonte de pronóstico. Aún así, es interesante ver que un modelo basado en Transformer puede competir con modelos MLP de última generación.
Conclusión
PatchTST es un modelo basado en Transformer que utiliza el parcheo para extraer el significado semántico local en datos de series temporales. Esto permite que el modelo sea más rápido de entrenar y tenga una ventana de entrada más larga.
Ha logrado un rendimiento de vanguardia en comparación con otros modelos basados en Transformer. En nuestro pequeño ejercicio, vimos que también logró un mejor rendimiento que N-BEATS y N-HiTS.
Si bien esto no significa que sea mejor que N-HiTS o N-BEATS, sigue siendo una opción interesante cuando se pronostica a largo plazo.
¡Gracias por leer! Espero que lo hayas disfrutado y que hayas aprendido algo nuevo!
¡Salud 🍻!
Referencias
Una serie de tiempo vale 64 palabras: Pronóstico a largo plazo con Transformers por Nie Y., Nguyen N. et al.
Neuralforecast por Olivares K., Challu C., Garza F., Canseco M., Dubrawski A.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Utilizando Gráficos de Superficie 3D de Plotly para Visualizar Superficies Geológicas.
- ¿Se aprueba la visa H1B en función de los análisis de datos?
- ¿Cómo luce la descripción de trabajo de un analista de datos?
- El Aprendizaje Automático Desbloquea Información Sobre Detección de Estrés.
- LangChain Mejorando el rendimiento con la capacidad de memoria
- De Python a Julia Manipulación de Datos Básica y Análisis Exploratorio de Datos (EDA)
- Creando increíbles visualizaciones de árbol de decisiones con dtreeviz.






