Solucionando cuellos de botella en la tubería de entrada de datos con PyTorch Profiler y TensorBoard
Optimizing data input bottlenecks with PyTorch Profiler and TensorBoard
Análisis y optimización del rendimiento del modelo PyTorch – Parte 4
Este es el cuarto artículo de nuestra serie sobre el análisis y la optimización del rendimiento de las cargas de trabajo basadas en GPU en PyTorch. En este artículo, nos centraremos en la pipa de entrada de datos de entrenamiento. En una aplicación de entrenamiento típica, las CPUs del host cargan, preprocesan y unen los datos antes de alimentarlos a la GPU para el entrenamiento. Los cuellos de botella en la pipa de entrada ocurren cuando el host no puede mantenerse al ritmo de la velocidad de la GPU. Esto hace que la GPU, el recurso más costoso en la configuración de entrenamiento, permanezca inactiva durante períodos de tiempo mientras espera la entrada de datos del host sobrecargado. En publicaciones anteriores (por ejemplo, aquí) hemos discutido los cuellos de botella en la pipa de entrada en detalle y revisado diferentes formas de abordarlos, como:
- Elegir una instancia de entrenamiento con una relación de cálculo de CPU a GPU más adecuada para su carga de trabajo (por ejemplo, consulte nuestra publicación anterior sobre consejos para elegir el mejor tipo de instancia para su carga de trabajo de aprendizaje automático),
- Mejorar el equilibrio de la carga de trabajo entre la CPU y la GPU moviendo parte de la actividad de preprocesamiento de la CPU a la GPU, y
- Transferir parte del cálculo de la CPU a dispositivos auxiliares de CPU (por ejemplo, ver aquí).
Por supuesto, el primer paso para abordar un cuello de botella de rendimiento en la pipa de entrada de datos es identificarlo y comprenderlo. En este artículo, demostraremos cómo se puede hacer esto utilizando PyTorch Profiler y su complemento asociado de TensorBoard.
Al igual que en nuestros artículos anteriores, definiremos un modelo PyTorch de juguete y luego perfilaremos su rendimiento de manera iterativa, identificaremos los cuellos de botella e intentaremos solucionarlos. Ejecutaremos nuestros experimentos en una instancia g5.2xlarge de Amazon EC2 (que contiene una GPU NVIDIA A10G y 8 vCPUs) y utilizando la imagen Docker oficial de AWS PyTorch 2.0. Tenga en cuenta que algunos de los comportamientos que describimos pueden variar entre las versiones de PyTorch.
Muchas gracias a Yitzhak Levi por sus contribuciones a este artículo.
- Versión de ChatGPT para Grandes Empresas a ser lanzada por OpenAI
- Tutorial Avanzado Cómo Dominar Matplotlib como un Verdadero Jefe
- Revolucionando la productividad del correo electrónico Cómo la IA de SaneBox transforma tu experiencia en la bandeja de entrada
Modelo de juguete
En los siguientes bloques, presentamos el ejemplo de juguete que utilizaremos para nuestra demostración. Comenzamos definiendo un modelo simple de clasificación de imágenes. La entrada del modelo es un lote de imágenes YUV de 256×256 y la salida son sus correspondientes lotes de predicciones de clase semántica.
from math import log2import torchimport torch.nn as nnimport torch.nn.functional as Fimg_size = 256num_classes = 10hidden_size = 30# modelo de clasificación de CNN de jugueteclass Net(nn.Module): def __init__(self, img_size=img_size, num_classes=num_classes): super().__init__() self.conv_in = nn.Conv2d(3, hidden_size, 3, padding='same') num_hidden = int(log2(img_size)) hidden = [] for i in range(num_hidden): hidden.append(nn.Conv2d(hidden_size, hidden_size, 3, padding='same')) hidden.append(nn.ReLU()) hidden.append(nn.MaxPool2d(2)) self.hidden = nn.Sequential(*hidden) self.conv_out = nn.Conv2d(hidden_size, num_classes, 3, padding='same') def forward(self, x): x = F.relu(self.conv_in(x)) x = self.hidden(x) x = self.conv_out(x) x = torch.flatten(x, 1) return xEl bloque de código a continuación contiene la definición de nuestro conjunto de datos. Nuestro conjunto de datos contiene diez mil rutas de archivos de imágenes jpeg y sus etiquetas semánticas asociadas (generadas aleatoriamente). Para simplificar nuestra demostración, supondremos que todas las rutas de archivos jpeg apuntan a la misma imagen, la imagen de los “cuellos de botella” coloridos en la parte superior de este artículo.
import numpy as npfrom PIL import Imagefrom torchvision.datasets.vision import VisionDatasetinput_img_size = [533, 800]class FakeDataset(VisionDataset): def __init__(self, transform): super().__init__(root=None, transform=transform) size = 10000 self.img_files = [f'0.jpg' for i in range(size)] self.targets = np.random.randint(low=0,high=num_classes, size=(size),dtype=np.uint8).tolist() def __getitem__(self, index): img_file, target = self.img_files[index], self.targets[index] with torch.profiler.record_function('PIL open'): img = Image.open(img_file) if self.transform is not None: img = self.transform(img) return img, target def __len__(self): return len(self.img_files)Tenga en cuenta que hemos envuelto el lector de archivos con un administrador de contexto torch.profiler.record_function.
Nuestra tubería de datos de entrada incluye las siguientes transformaciones en la imagen:
- PILToTensor convierte la imagen PIL en un tensor PyTorch.
- RandomCrop devuelve un recorte de 256×256 en una posición aleatoria de la imagen.
- RandomMask es una transformación personalizada que crea una máscara booleana aleatoria de 256×256 y la aplica a la imagen. La transformación incluye una operación de dilatación de cuatro vecinos en la máscara.
- ConvertColor es una transformación personalizada que convierte el formato de la imagen de RGB a YUV.
- Scale es una transformación personalizada que escala los píxeles al rango [0,1].
class RandomMask(torch.nn.Module): def __init__(self, ratio=0.25): super().__init__() self.ratio=ratio def dilate_mask(self, mask): # realiza la dilatación de cuatro vecinos en la máscara with torch.profiler.record_function('dilatación'): from scipy.signal import convolve2d dilated = convolve2d(mask, [[0, 1, 0], [1, 1, 1], [0, 1, 0]], mode='same').astype(bool) return dilated def forward(self, img): with torch.profiler.record_function('aleatorio'): mask = np.random.uniform(size=(img_size, img_size)) < self.ratio dilated_mask = torch.unsqueeze(torch.tensor(self.dilate_mask(mask)),0) dilated_mask = dilated_mask.expand(3,-1,-1) img[dilated_mask] = 0. return img def __repr__(self): return f"{self.__class__.__name__}(ratio={self.ratio})"class ConvertColor(torch.nn.Module): def __init__(self): super().__init__() self.A=torch.tensor( [[0.299, 0.587, 0.114], [-0.16874, -0.33126, 0.5], [0.5, -0.41869, -0.08131]] ) self.b=torch.tensor([0.,128.,128.]) def forward(self, img): img = img.to(dtype=torch.get_default_dtype()) img = torch.matmul(self.A,img.view([3,-1])).view(img.shape) img = img + self.b[:,None,None] return img def __repr__(self): return f"{self.__class__.__name__}()"class Scale(object): def __call__(self, img): return img.to(dtype=torch.get_default_dtype()).div(255) def __repr__(self): return f"{self.__class__.__name__}()"Encadenamos las transformaciones usando la clase Compose, que hemos modificado ligeramente para incluir un administrador de contexto torch.profiler.record_function alrededor de cada una de las invocaciones de transformación.
import torchvision.transforms as Tclass CustomCompose(T.Compose): def __call__(self, img): for t in self.transforms: with torch.profiler.record_function(t.__class__.__name__): img = t(img) return imgtransform = CustomCompose( [T.PILToTensor(), T.RandomCrop(img_size), RandomMask(), ConvertColor(), Scale()])En el bloque de código a continuación definimos el conjunto de datos y el cargador de datos. Configuramos DataLoader para utilizar una función de combinación personalizada en la que envolvemos la función de combinación predeterminada con un administrador de contexto torch.profiler.record_function.
train_set = FakeDataset(transform=transform)def custom_collate(batch): from torch.utils.data._utils.collate import default_collate with torch.profiler.record_function('combinar'): batch = default_collate(batch) image, label = batch return image, labeltrain_loader = torch.utils.data.DataLoader(train_set, batch_size=256, collate_fn=custom_collate, num_workers=4, pin_memory=True)Por último, definimos el modelo, la función de pérdida, el optimizador y el bucle de entrenamiento, que envolvemos con un administrador de contexto de perfilador.
from statistics import mean, variancefrom time import timedevice = torch.device("cuda:0")model = Net().cuda(device)criterion = nn.CrossEntropyLoss().cuda(device)optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)model.train()t0 = time()times = []with torch.profiler.profile( schedule=torch.profiler.schedule(wait=10, warmup=2, active=10, repeat=1), on_trace_ready=torch.profiler.tensorboard_trace_handler('/tmp/prof'), record_shapes=True, profile_memory=True, with_stack=True) as prof: for step, data in enumerate(train_loader): with torch.profiler.record_function('copiar de h2d'): inputs, labels = data[0].to(device=device, non_blocking=True), \ data[1].to(device=device, non_blocking=True) if step >= 40: break outputs = model(inputs) loss = criterion(outputs, labels) optimizer.zero_grad(set_to_none=True) loss.backward() optimizer.step() prof.step() times.append(time()-t0) t0 = time()print(f'tiempo promedio: {mean(times[1:])}, varianza: {variance(times[1:])}')En las siguientes secciones utilizaremos PyTorch Profiler y su complemento asociado de TensorBoard para evaluar el rendimiento de nuestro modelo. Nos enfocaremos en la Vista de Rastro del informe del perfilador. Por favor, consulte la primera publicación de nuestra serie para ver una demostración de cómo utilizar las otras secciones del informe.
Resultados de Rendimiento Iniciales
El tiempo promedio por paso reportado por el script que definimos es de 1.3 segundos y la utilización promedio de la GPU es muy baja, un 18.21%. En la imagen a continuación capturamos los resultados de rendimiento tal como se muestran en la Vista de Rastro del complemento de TensorBoard:
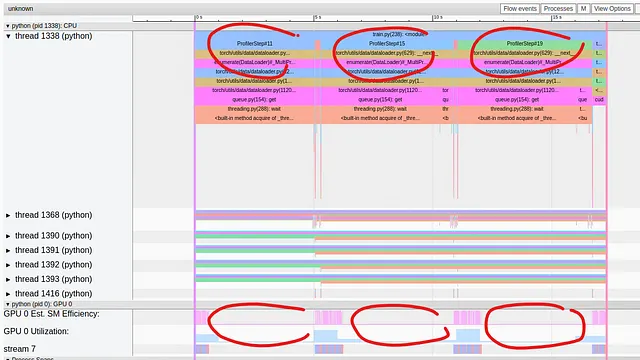
Podemos ver que cada cuarto paso de entrenamiento incluye un largo periodo de carga de datos (~5.5 segundos) durante el cual la GPU está completamente inactiva. La razón por la que esto ocurre cada cuarto paso está directamente relacionada con el número de trabajadores DataLoader que elegimos, que es cuatro. Cada cuarto paso encontramos que todos los trabajadores están ocupados produciendo las muestras para el siguiente lote mientras la GPU espera. Esto es una clara indicación de un cuello de botella en el pipeline de entrada de datos. La pregunta es ¿cómo lo analizamos? Complicando las cosas está el hecho de que los muchos marcadores de record_function que insertamos en el código no se encuentran en el rastro del perfil.
El uso de múltiples trabajadores en el DataLoader es crítico para optimizar el rendimiento. Desafortunadamente, también hace que el proceso de perfilado sea más difícil. Aunque existen perfiles que admiten análisis multiproceso (por ejemplo, revisa VizTracer), el enfoque que tomaremos en esta publicación es ejecutar, analizar y optimizar nuestro modelo en modo de un solo proceso (es decir, con cero trabajadores DataLoader) y luego aplicar las optimizaciones al modo de múltiples trabajadores. Admitimos que optimizar la velocidad de una función independiente no garantiza que múltiples (paralelas) invocaciones de la misma función también se beneficien. Sin embargo, como veremos en esta publicación, esta estrategia nos permitirá identificar y abordar algunos problemas fundamentales que no pudimos identificar de otra manera, y, al menos en relación con los problemas discutidos aquí, encontraremos una fuerte correlación entre los impactos de rendimiento en los dos modos. Pero justo antes de aplicar esta estrategia, ajustemos nuestra elección del número de trabajadores.
Optimización 1: Ajustar la estrategia de multiprocesamiento
Determinar el número óptimo de hilos o procesos en una aplicación multiproceso/multihilo, como la nuestra, puede ser complicado. Por un lado, si elegimos un número demasiado bajo, es posible que subutilicemos los recursos de la CPU. Por otro lado, si vamos demasiado alto, corremos el riesgo de thrashing, una situación no deseada en la que el sistema operativo pasa la mayor parte de su tiempo administrando los múltiples hilos/procesos en lugar de ejecutar nuestro código. En el caso de una carga de trabajo de entrenamiento de PyTorch, se recomienda probar diferentes opciones para la configuración num_workers de DataLoader. Un buen punto de partida es establecer el número en función del número de CPUs en el host (por ejemplo, num_workers:=num_cpus/num_gpus). En nuestro caso, el Amazon EC2 g5.2xlarge tiene ocho vCPUs y, de hecho, aumentar el número de trabajadores DataLoader a ocho resulta en un tiempo promedio por paso ligeramente mejor de 1.17 segundos (un aumento del 11%).
Es importante tener en cuenta otras configuraciones menos obvias que podrían afectar el número de hilos o procesos utilizados por el pipeline de entrada de datos. Por ejemplo, opencv-python, una biblioteca comúnmente utilizada para el preprocesamiento de imágenes en cargas de trabajo de visión por computadora, incluye la función cv2.setNumThreads(int) para controlar el número de hilos.
En la imagen a continuación capturamos una parte de la Vista de Rastro al ejecutar el script con num_workers configurado en cero.

Ejecutar el script de esta manera nos permite ver las etiquetas de record_function que establecimos e identificar la transformación RandomMask, o más específicamente nuestra función de dilatación, como la operación más lenta en la recuperación de cada muestra individual.
Optimización 2: Optimizar la función de dilatación
Nuestra implementación actual de la función de dilatación utiliza una convolución 2D, típicamente implementada utilizando multiplicación de matrices y no se sabe que se ejecuta especialmente rápido en la CPU. Una opción sería ejecutar la dilatación en la GPU (como se describe en esta publicación). Sin embargo, los gastos generados por la transacción entre el host y el dispositivo probablemente superarían las posibles ganancias de rendimiento de este tipo de solución, sin mencionar que preferimos no aumentar la carga en la GPU.
En el bloque de código a continuación, proponemos una alternativa más amigable para la CPU de implementación de la función de dilatación que utiliza operaciones booleanas en lugar de una convolución:
def dilate_mask(self, mask): # realizar dilatación de 4 vecinos en la máscara with torch.profiler.record_function('dilatación'): padded = np.pad(mask, [(1,1),(1,1)]) dilated = padded[0:-2,1:-1] | padded[1:-1,1:-1] | padded[2:,1:-1] | padded[1:-1,0:-2]| padded[1:-1,2:] return dilatedDespués de esta modificación, nuestro tiempo de paso disminuye a 0.78 segundos, lo que representa una mejora adicional del 50%. La vista de traza de un solo proceso actualizada se muestra a continuación:

Podemos ver que la operación de dilatación se ha reducido significativamente y que la operación que consume más tiempo ahora es la transformación PILToTensor.
Una mirada más cercana a la función PILToTensor (ver aquí) revela tres operaciones subyacentes:
- Cargar la imagen PIL: debido a la propiedad de carga diferida de Image.open, la imagen se carga aquí.
- La imagen PIL se convierte en una matriz numpy.
- La matriz numpy se convierte en un tensor PyTorch.
Aunque la carga de la imagen lleva la mayor parte del tiempo, observamos el extremo desperdicio de aplicar las operaciones subsiguientes a la imagen de tamaño completo solo para recortarla inmediatamente después. Esto nos lleva a nuestra próxima optimización.
Optimización 3: Reordenar las transformaciones
Afortunadamente, la transformación RandomCrop se puede aplicar directamente a la imagen PIL, lo que nos permite aplicar la reducción de tamaño de la imagen como la primera operación en nuestra tubería:
transform = CustomCompose( [T.RandomCrop(img_size), T.PILToTensor(), RandomMask(), ConvertColor(), Scale()])Después de esta optimización, nuestro tiempo de paso disminuye a 0.72 segundos, una optimización adicional del 8%. La vista de traza capturada a continuación muestra que la transformación RandomCrop es ahora la operación dominante:

En realidad, como antes, en realidad es la carga de la imagen PIL (diferida) lo que causa el cuello de botella, no el recorte aleatorio.
Idealmente, podríamos optimizar esto aún más limitando la operación de lectura solo al recorte en el que estamos interesados. Desafortunadamente, hasta el momento de escribir esto, torchvision no admite esta opción. En una publicación futura mostraremos cómo podemos superar esta limitación implementando nuestro propio operador personalizado decode_and_crop de PyTorch.
Optimización 4: Aplicar transformaciones en lotes
En nuestra implementación actual, cada una de las transformaciones de imagen se aplica individualmente a cada imagen. Sin embargo, algunas transformaciones pueden ejecutarse de manera más óptima cuando se aplican a todo el lote de imágenes a la vez. En el bloque de código a continuación, modificamos nuestra tubería para que las transformaciones ColorTransformation y Scale se apliquen en lotes de imágenes dentro de nuestra función personalizada collate:
def batch_transform(img): img = img.to(dtype=torch.get_default_dtype()) A = torch.tensor( [[0.299, 0.587, 0.114], [-0.16874, -0.33126, 0.5], [0.5, -0.41869, -0.08131]] ) b = torch.tensor([0., 128., 128.]) A = torch.broadcast_to(A, ([img.shape[0],3,3])) t_img = torch.bmm(A,img.view(img.shape[0],3,-1)) t_img = t_img + b[None,:, None] return t_img.view(img.shape)/255def custom_collate(batch): from torch.utils.data._utils.collate import default_collate with torch.profiler.record_function('collate'): batch = default_collate(batch) image, label = batch with torch.profiler.record_function('batch_transform'): image = batch_transform(image) return image, labelEl resultado de este cambio es en realidad un ligero aumento en el tiempo del paso, a 0,75 segundos. Aunque no es útil en el caso de nuestro modelo de juguete, la capacidad de aplicar ciertas operaciones como transformaciones por lotes en lugar de transformaciones por muestra lleva el potencial de optimizar ciertas cargas de trabajo.
Resultados
Las optimizaciones sucesivas que hemos aplicado en esta publicación resultaron en una mejora del 80% en el rendimiento del tiempo de ejecución. Sin embargo, aunque menos grave, todavía hay un cuello de botella en la canalización de entrada y la GPU sigue siendo muy subutilizada (~30%). Por favor, vuelva a visitar nuestras publicaciones anteriores (por ejemplo, aquí) para obtener métodos adicionales para abordar este tipo de problemas.
Resumen
En esta publicación nos hemos centrado en los problemas de rendimiento en la canalización de entrada de datos de entrenamiento. Al igual que en nuestras publicaciones anteriores de esta serie, hemos elegido el Profiler de PyTorch y su complemento asociado de TensorBoard como nuestras herramientas de elección y hemos demostrado su uso para acelerar la velocidad de entrenamiento. En particular, mostramos cómo ejecutar el DataLoader sin trabajadores aumenta nuestra capacidad para identificar, analizar y optimizar los cuellos de botella en la canalización de entrada de datos.
Al igual que en nuestras publicaciones anteriores, enfatizamos que el camino hacia una optimización exitosa variará enormemente según los detalles del proyecto de entrenamiento, incluida la arquitectura del modelo y el entorno de entrenamiento. En la práctica, alcanzar sus objetivos puede ser más difícil que en el ejemplo que presentamos aquí. Algunas de las técnicas que describimos pueden tener poco impacto en su rendimiento o incluso empeorarlo. También destacamos que las optimizaciones precisas que elegimos y el orden en que decidimos aplicarlas fueron algo arbitrarios. Se le anima en gran medida a desarrollar sus propias herramientas y técnicas para alcanzar sus objetivos de optimización basados en los detalles específicos de su proyecto.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Conoce a Nous-Hermes-Llama2-70b Un modelo de lenguaje de última generación ajustado finamente en más de 300,000 instrucciones.
- Cadenas de Markov de Tiempo Discreto – Identificando Trayectorias Ganadoras de Clientes en una Campaña de Devolución de Dinero
- Seis recursos útiles para ingenieros
- 5 Razones para considerar un Bootcamp de Ciencia de Datos antes de la educación superior
- Arquitectura de Datos y Teorema CAP ¿Dónde chocan?
- A pesar de los temores de trampas, las escuelas revocan las prohibiciones de ChatGPT
- Top Herramientas de IA Low/No Code (Septiembre 2023)






