Mejorando modelos de lenguaje mediante la recuperación de billones de tokens.
'Optimizando modelos de lenguaje a través de la recuperación de un gran número de tokens.'
En los últimos años, se han logrado avances significativos en la mejora del rendimiento en la modelización de lenguaje autoregresiva al aumentar el número de parámetros en los modelos Transformer. Esto ha llevado a un aumento tremendo en el costo energético del entrenamiento y ha resultado en la generación de “Modelos de Lenguaje Grandes” (LLMs) densos con más de 100 mil millones de parámetros. Al mismo tiempo, se han recopilado grandes conjuntos de datos que contienen billones de palabras para facilitar el entrenamiento de estos LLMs.
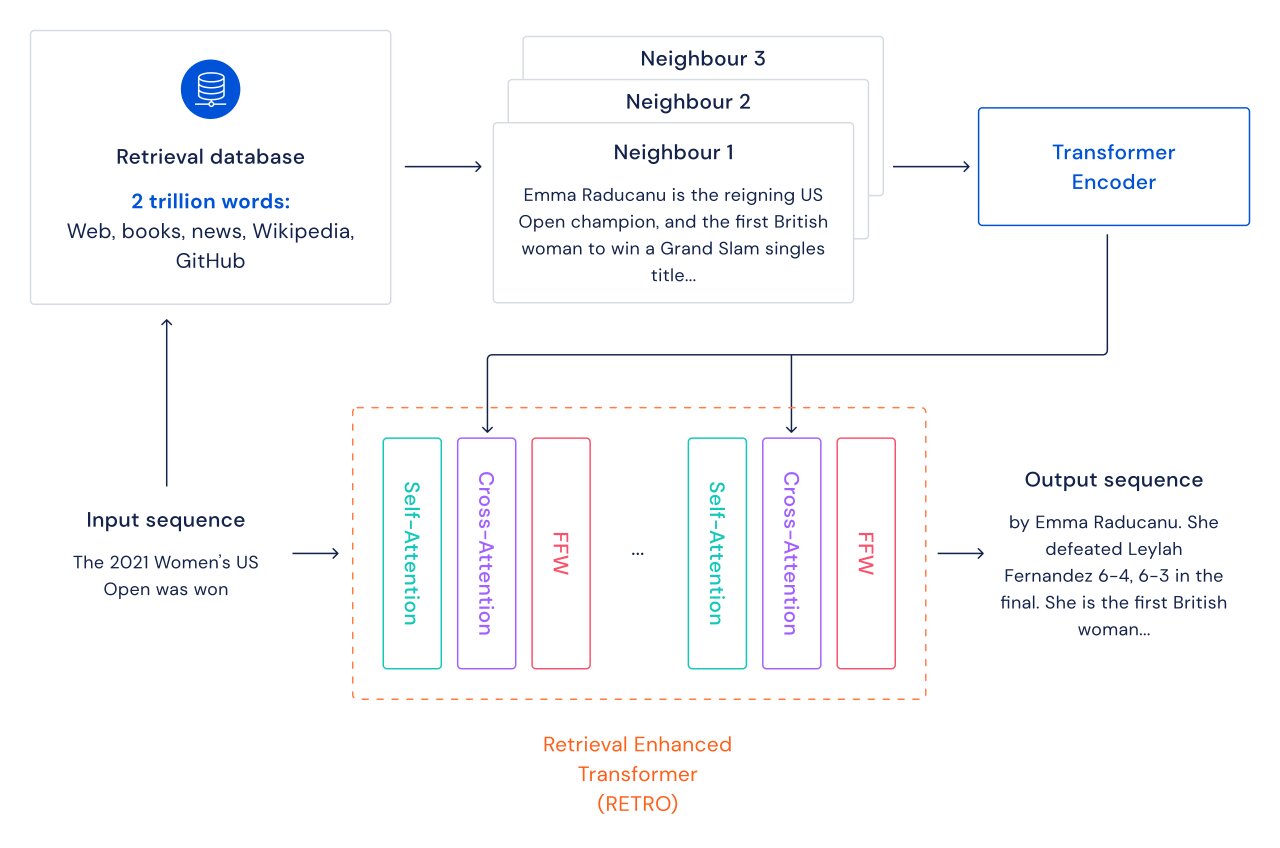
Exploramos un camino alternativo para mejorar los modelos de lenguaje: agregamos recuperación de información a los transformers a través de una base de datos de fragmentos de texto que incluye páginas web, libros, noticias y código. Llamamos a nuestro método RETRO, por “Retrieval Enhanced TRansfOrmers”.
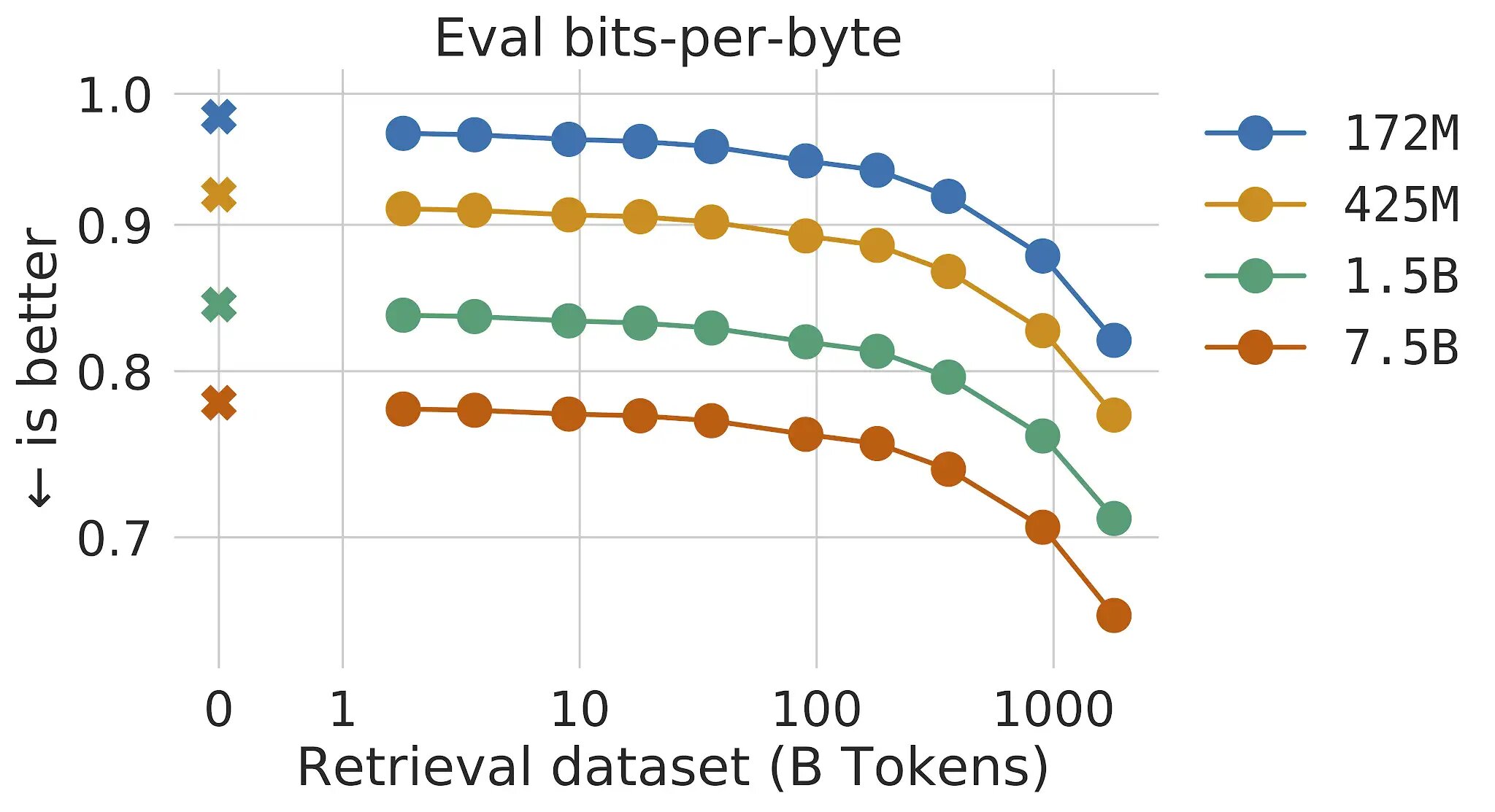
En los modelos de lenguaje transformer tradicionales, los beneficios del tamaño del modelo y del tamaño de los datos están vinculados: siempre y cuando el conjunto de datos sea lo suficientemente grande, el rendimiento de la modelización de lenguaje está limitado por el tamaño del modelo. Sin embargo, con RETRO, el modelo no está limitado a los datos vistos durante el entrenamiento, sino que tiene acceso a todo el conjunto de datos de entrenamiento a través del mecanismo de recuperación. Esto resulta en mejoras significativas en el rendimiento en comparación con un Transformer estándar con el mismo número de parámetros. Mostramos que la modelización de lenguaje mejora continuamente a medida que aumentamos el tamaño de la base de datos de recuperación, al menos hasta 2 billones de tokens, equivalentes a 175 vidas completas de lectura continua.
Para cada fragmento de texto (aproximadamente un párrafo de un documento), se realiza una búsqueda de vecinos más cercanos que devuelve secuencias similares encontradas en la base de datos de entrenamiento y su continuación. Estas secuencias ayudan a predecir la continuación del texto de entrada. La arquitectura RETRO combina la autoatención regular a nivel de documento con la atención cruzada a nivel de fragmento recuperado. Esto resulta en continuaciones más precisas y basadas en hechos. Además, RETRO aumenta la interpretabilidad de las predicciones del modelo y proporciona una vía para intervenciones directas a través de la base de datos de recuperación para mejorar la seguridad de la continuación del texto. En nuestros experimentos en Pile, un benchmark estándar de modelización de lenguaje, un modelo RETRO con 7.5 mil millones de parámetros supera al Jurassic-1 con 175 mil millones de parámetros en 10 de los 16 conjuntos de datos y supera al Gopher con 280 mil millones de parámetros en 9 de los 16 conjuntos de datos.
- Modelado del lenguaje a gran escala Gopher, consideraciones éticas y recuperación
- La normatividad espuria mejora el aprendizaje del comportamiento de cumplimiento y aplicación en agentes artificiales.
- Modelos de Lenguaje de Red Teaming con Modelos de Lenguaje
A continuación, mostramos dos ejemplos de nuestro modelo base con 7B de parámetros y de nuestro modelo RETRO con 7.5B de parámetros que destacan cómo las muestras de RETRO son más basadas en hechos y se mantienen más en el tema que la muestra base.


We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- El primer paso de MuZero de la investigación al mundo real.
- Acelerando la ciencia de la fusión a través del control de plasma aprendido
- Prediciendo el pasado con Ithaca
- GopherCite Enseñando a los modelos de lenguaje a respaldar respuestas con citas verificadas
- Un análisis empírico del entrenamiento de modelos de lenguaje grandes óptimos en cómputo
- La última investigación de DeepMind en ICLR 2022
- Comenzando con JAX






