Optimización del tamaño del archivo de salida en Apache Spark
Optimización tamaño archivo salida Apache Spark
Una Guía Completa sobre la Gestión de Particiones, Repartición y Operaciones de Coalesce
Imagínate al mando de una gran operación de procesamiento de datos en Spark. Una regla general mencionada a menudo en el discurso de optimización de Spark es que, para obtener el mejor rendimiento de E/S y una mayor paralelismo, cada archivo de datos debe tener un tamaño aproximado de 128Mb, que es el tamaño de partición predeterminado al leer un archivo [1].
Imagina tus archivos como embarcaciones navegando en el mar del procesamiento de datos. Si las embarcaciones son demasiado pequeñas, pierden mucho tiempo atracando y volviendo a zarpar, una metáfora para el motor de ejecución que gasta tiempo adicional en abrir archivos, listar directorios, obtener metadatos de objetos, configurar transferencia de datos y leer archivos. Por otro lado, si tus embarcaciones son demasiado grandes y no utilizas los muchos muelles del puerto, tienen que esperar a un único proceso prolongado de carga y descarga, una metáfora para el procesamiento de consultas que espera hasta que un único lector haya terminado de leer el archivo completo, lo que reduce el paralelismo [fig. 1].
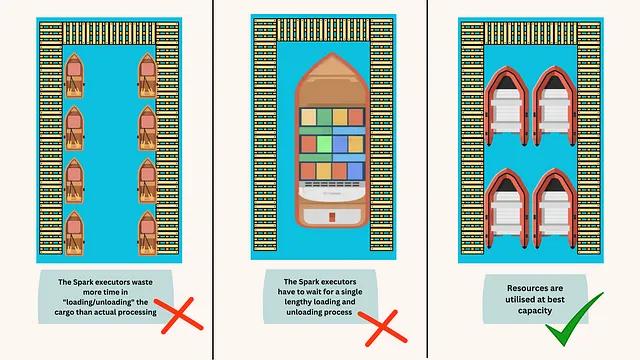
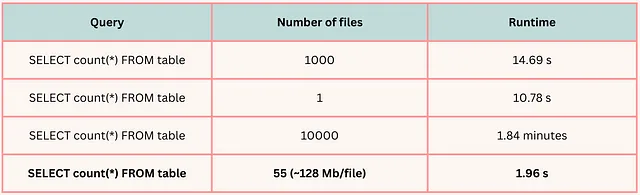
Para ilustrar vívidamente la importancia de la optimización del tamaño de archivo, consulta la siguiente figura. En este ejemplo específico, cada tabla contiene 8 GB de datos.
- GANs (Redes Generativas Adversarias)
- La IA es crucial para la ciberseguridad en el ámbito de la salud
- Clasificación de texto sin entrenamiento previo con Amazon SageMaker JumpStart
Sin embargo, navegar por este delicado equilibrio no es tarea fácil, especialmente al tratar con grandes trabajos por lotes. Puedes sentir que has perdido el control sobre el número de archivos de salida. Esta guía te ayudará a recuperarlo.
La Clave para Entender: Particiones
El número de archivos de salida guardados en el disco es igual al número de particiones en los ejecutores de Spark cuando se realiza la operación de escritura. Sin embargo, determinar el número de particiones antes de realizar la operación de escritura puede ser complicado.
Cuando se lee una tabla, Spark por defecto lee bloques con un tamaño máximo de 128Mb (aunque esto se puede cambiar con sql.files.maxPartitionBytes). Por lo tanto, el número de particiones depende del tamaño de entrada. Sin embargo, en realidad, el número de particiones probablemente será igual al parámetro sql.shuffle.partitions. Este número tiene un valor predeterminado de 200, pero para cargas de trabajo más grandes, rara vez es suficiente. Mira este video para aprender cómo establecer el número ideal de particiones de shuffle.
El número de particiones en los ejecutores de Spark es igual a sql.shuffle.partitions si hay al menos una transformación amplia (wide transformation) en la ETL. Si solo se aplican transformaciones estrechas (narrow transformations), el número de particiones sería igual al número creado al leer el archivo.
Establecer el número de particiones de shuffle nos da un control de alto nivel sobre las particiones totales solo cuando se trata de tablas no particionadas. Una vez que entramos en el territorio de las tablas particionadas, cambiar el parámetro sql.shuffle.partitions no modificará fácilmente el tamaño de cada archivo de datos.
El Volante: Repartición y Coalesce
Existen dos formas principales de administrar el número de particiones en tiempo de ejecución: repartition() y coalesce(). Aquí hay una breve descripción:
Repartición:repartition(partitionCols, n_partitions)es una transformación perezosa (lazy transformation) con dos parámetros: el número de particiones y la(s) columna(s) de particionamiento. Cuando se realiza, Spark redistribuye las particiones en el clúster según la columna de particionamiento. Sin embargo, una vez que se guarda la tabla, se pierde la información sobre la repartición. Por lo tanto, esta útil información no se utilizará al leer el archivo.
df = df.repartition("nombre_columna", n_partitions)Coalesce:coalesce(num_partitions)es también una transformación perezosa, pero solo toma un argumento: el número de particiones. Es importante destacar que la operación coalesce no redistribuye los datos en el clúster, por lo tanto es más rápido querepartition. Además, coalesce solo puede reducir el número de particiones, no funcionará si se intenta aumentar el número de particiones.
df = df.coalesce(num_partitions)La idea principal aquí es que el uso del método coalesce generalmente es más beneficioso. Esto no quiere decir que la redistribución no sea útil; ciertamente lo es, especialmente cuando necesitamos ajustar el número de particiones en un dataframe durante la ejecución.
En mi experiencia con procesos ETL, donde trabajo con múltiples tablas de diferentes tamaños y realizo transformaciones y joins complejos, he encontrado que sql.shuffle.partitions no ofrece el control preciso que necesito. Por ejemplo, usar el mismo número de particiones de redistribución para unir dos tablas pequeñas y dos tablas grandes en el mismo ETL sería ineficiente, lo que resultaría en un exceso de particiones pequeñas para las tablas pequeñas o un número insuficiente de particiones para las tablas grandes. La redistribución también tiene el beneficio adicional de ayudarme a evitar problemas con joins desequilibrados y datos desequilibrados [2].
Dicho esto, la redistribución es menos adecuada antes de escribir la tabla en el disco y, en la mayoría de los casos, se puede reemplazar con coalesce. Coalesce tiene la ventaja sobre la redistribución antes de escribir en el disco por un par de razones:
- Evita una redistribución innecesaria de datos en el clúster.
- Permite el ordenamiento de datos según una heurística lógica. Cuando se utiliza el método de redistribución antes de escribir, los datos se redistribuyen en el clúster, lo que provoca una pérdida en su orden. En cambio, al usar coalesce, se mantiene el orden ya que los datos se agrupan en lugar de redistribuirse.
Veamos por qué el ordenamiento de los datos es crucial.
Orden en el horizonte: Importancia del ordenamiento de datos
Mencionamos anteriormente cómo cuando aplicamos el método repartition, Spark no guarda la información de particionamiento en los metadatos de la tabla. Sin embargo, al tratar con big data, esta es una pieza crucial de información por dos motivos:
- Permite escanear la tabla mucho más rápidamente en el momento de la consulta.
- Permite una mejor compresión, si se trata de un formato compresible (como parquet, CSV, Json, etc). Este es un gran artículo para entender por qué.
La idea principal es ordenar los datos antes de guardarlos. La información se retendrá en los metadatos y se utilizará en el momento de la consulta, lo que hace que la consulta sea mucho más rápida.
Ahora veamos las diferencias entre guardar en una tabla no particionada y una tabla particionada, y por qué guardar en una tabla particionada requiere algunos ajustes adicionales.
Gestión del tamaño de archivo en tablas particionadas
Cuando se trata de tablas no particionadas, gestionar el número de archivos durante la operación de guardar es un proceso directo. Utilizar el método coalesce antes de guardar logrará la tarea, independientemente de si los datos están ordenados o no.
# Ejemplo de uso del método coalesce antes de guardar una tabla no particionadadf.coalesce(10).write.format("parquet").save("/ruta/de/salida")Sin embargo, este método no es efectivo al manejar tablas particionadas, a menos que los datos estén ordenados antes de hacer el coalesce. Para entender por qué sucede esto, debemos adentrarnos en las acciones que tienen lugar dentro de los ejecutores de Spark cuando los datos están ordenados versus cuando no lo están [fig.2].
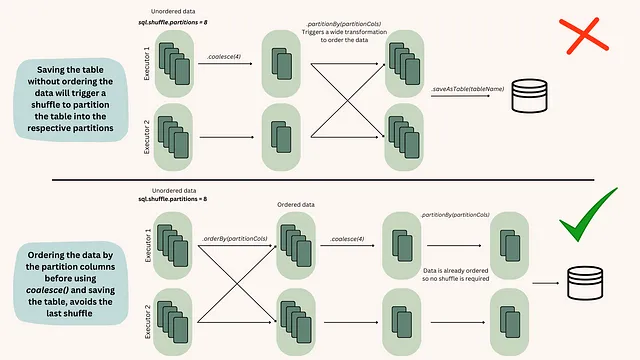
Por lo tanto, el proceso estándar para guardar datos en una tabla particionada debería ser:
# Ejemplo de uso del método coalesce después de ordenar los datos en una tabla particionadadf.orderBy("nombreColumna").coalesce(10).write.format("parquet").save("/ruta/de/salida_particionada")Otros Ayudas Navegacionales
Más allá de repartition y coalesce, es posible que encuentres útil maxnumberofrecords. Es un método práctico para evitar que los archivos se vuelvan demasiado grandes y se puede utilizar junto con los métodos anteriores.
df.write.option("maxRecordsPerFile", 50000).save("ruta_del_archivo")Conclusiones Finales
El dominio del tamaño de los archivos en un trabajo de Spark a menudo implica prueba y error. Es fácil pasar por alto la optimización en una era en la que el espacio de almacenamiento es barato y la potencia de procesamiento está a solo un clic de distancia. Pero a medida que el procesamiento de terabytes y petabytes de datos se convierte en la norma, olvidar estas simples técnicas de optimización puede tener costos significativos en términos monetarios, de tiempo y ambientales.
Espero que este artículo te capacite para realizar ajustes eficientes en tus procesos de ETL. Como un experimentado capitán de mar, que navegues por las aguas de Spark con confianza y claridad.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- ¿Qué tienen en común una medusa, un gato, una serpiente y un astronauta? Matemáticas
- Una introducción gentil a los modelos de lenguaje grandes de código abierto
- 5 Formas Prácticas de Utilizar la IA Que También Puedes Usar
- ¿De quién es la responsabilidad de hacer que la IA generativa sea correcta?
- California acaba de abrir las compuertas para los coches autónomos
- Descifrando los misterios de los modelos de lenguaje grandes un análisis detallado de las funciones de influencia y su escalabilidad
- Google presenta Project IDX un paraíso para desarrolladores basado en navegador impulsado por IA.






