Análisis y optimización del rendimiento del modelo PyTorch – Parte 3
Optimización rendimiento modelo PyTorch - Parte 3
Cómo reducir los eventos “Cuda Memcpy Async” y por qué debes tener cuidado con las operaciones de máscara booleana
Esta es la tercera parte de una serie de publicaciones sobre el tema de análisis y optimización de modelos de PyTorch utilizando PyTorch Profiler y TensorBoard. Nuestra intención ha sido resaltar los beneficios del perfilado de rendimiento y la optimización de cargas de trabajo de entrenamiento basadas en GPU y su impacto potencial en la velocidad y el costo del entrenamiento. En particular, deseamos demostrar la accesibilidad de las herramientas de perfilado como PyTorch Profiler y TensorBoard para todos los desarrolladores de ML. No necesitas ser un experto en CUDA para obtener ganancias de rendimiento significativas al aplicar las técnicas que discutimos en nuestras publicaciones.
En nuestra primera publicación demostramos cómo se pueden utilizar las diferentes vistas del complemento TensorBoard de PyTorch Profiler para identificar problemas de rendimiento y revisamos algunas técnicas populares para acelerar el entrenamiento. En la segunda publicación mostramos cómo se puede utilizar la vista Trace del complemento TensorBoard para identificar cuándo se copian tensores desde la CPU a la GPU y viceversa. Este movimiento de datos, que puede causar puntos de sincronización y ralentizar considerablemente la velocidad de entrenamiento, a menudo es involuntario y a veces se puede evitar fácilmente. El tema de esta publicación serán las situaciones en las que encontramos puntos de sincronización entre la GPU y la CPU que no están asociados con copias de tensores. Al igual que en el caso de las copias de tensores, esto puede causar estancamiento en tu paso de entrenamiento y ralentizar considerablemente el tiempo total de entrenamiento. Demostraremos la existencia de tales ocurrencias, cómo se pueden identificar utilizando PyTorch Profiler y el complemento TensorBoard de PyTorch Profiler, y los posibles beneficios de rendimiento de construir tu modelo de una manera que minimice tales eventos de sincronización.
Como en nuestras publicaciones anteriores, definiremos un modelo de PyTorch de juguete y luego perfilaremos su rendimiento, identificaremos cuellos de botella e intentaremos solucionarlos. Ejecutaremos nuestros experimentos en una instancia Amazon EC2 g5.2xlarge (que contiene una GPU NVIDIA A10G y 8 vCPUs) utilizando la imagen Docker oficial de PyTorch 2.0 de AWS. Ten en cuenta que algunos de los comportamientos que describimos pueden variar entre versiones de PyTorch.
Ejemplo de Juguete
En los siguientes bloques presentamos un modelo de PyTorch de juguete que realiza segmentación semántica en una imagen de entrada de 256×256, es decir, toma una imagen RGB de 256×256 y produce un mapa de etiquetas de “píxel por píxel” de una clase de diez categorías semánticas.
- Clasificación de texto con codificadores de Transformer
- Transformada de Fourier para series de tiempo descomposición de tendencia
- Avance en la Intersección de Visión-Lenguaje Presentando el Proyecto Todo-Vista
import torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.optimimport torch.profilerimport torch.utils.datafrom torch import Tensorclass Net(nn.Module): def __init__(self, num_hidden=10, num_classes=10): super().__init__() self.conv_in = nn.Conv2d(3, 10, 3, padding='same') hidden = [] for i in range(num_hidden): hidden.append(nn.Conv2d(10, 10, 3, padding='same')) hidden.append(nn.ReLU()) self.hidden = nn.Sequential(*hidden) self.conv_out = nn.Conv2d(10, num_classes, 3, padding='same') def forward(self, x): x = F.relu(self.conv_in(x)) x = self.hidden(x) x = self.conv_out(x) return xPara entrenar nuestro modelo utilizaremos la pérdida estándar de entropía cruzada con algunas modificaciones:
- Supondremos que las etiquetas objetivo incluyen un valor de ignorar que indica píxeles que queremos excluir del cálculo de pérdida.
- Supondremos que una de las etiquetas semánticas identifica ciertos píxeles como pertenecientes al “fondo” de la imagen. Definimos nuestra función de pérdida para tratar estos como etiquetas a ignorar.
- Actualizaremos los pesos de nuestro modelo solo cuando encontremos lotes con tensores de objetivos que incluyan al menos dos valores únicos.
Aunque hemos elegido estas modificaciones con el propósito de nuestra demostración, estos tipos de operaciones no son infrecuentes y se pueden encontrar en muchos modelos “estándar” de PyTorch. Dado que ya somos “expertos” en el perfilado de rendimiento, ya hemos envuelto cada una de las operaciones en nuestra función de pérdida con un administrador de contexto torch.profiler.record_function (como se describe en nuestra segunda publicación).
class MaskedLoss(nn.Module): def __init__(self, ignore_val=-1, num_classes=10): super().__init__() self.ignore_val = ignore_val self.num_classes = num_classes self.loss = torch.nn.CrossEntropyLoss() def cross_entropy(self, pred: Tensor, target: Tensor) -> Tensor: # crear una máscara booleana de etiquetas válidas with torch.profiler.record_function('crear máscara'): mask = target != self.ignore_val # permutar los logits en preparación para la máscara with torch.profiler.record_function('permutar'): permuted_pred = torch.permute(pred, [0, 2, 3, 1]) # aplicar la máscara booleana a las etiquetas y logits with torch.profiler.record_function('máscara'): masked_target = target[mask] masked_pred = permuted_pred[mask.unsqueeze(-1).expand(-1, -1, -1, self.num_classes)] masked_pred = masked_pred.reshape(-1, self.num_classes) # calcular la pérdida de entropía cruzada with torch.profiler.record_function('calcular pérdida'): loss = self.loss(masked_pred, masked_target) return loss def ignore_background(self, target: Tensor) -> Tensor: # descubrir todos los índices donde la etiqueta objetivo es "fondo" with torch.profiler.record_function('no_cero'): inds = torch.nonzero(target == self.num_classes - 1, as_tuple=True) # restablecer todas las etiquetas "fondo" al índice de ignorar with torch.profiler.record_function('asignación de índice'): target[inds] = self.ignore_val return target def forward(self, pred: Tensor, target: Tensor) -> Tensor: # ignorar las etiquetas de fondo target = self.ignore_background(target) # recuperar una lista de elementos únicos en el objetivo with torch.profiler.record_function('únicos'): unique = torch.unique(target) # verificar si el número de elementos únicos supera el umbral with torch.profiler.record_function('numel'): ignore_loss = torch.numel(unique) < 2 # calcular la pérdida de entropía cruzada loss = self.cross_entropy(pred, target) # poner a cero la pérdida en caso de que el número de elementos únicos # esté por debajo del umbral if ignore_loss: loss = 0. * loss return lossNuestra función de pérdida parece bastante inocente, ¿verdad? ¡Incorrecto! Como veremos a continuación, la función de pérdida incluye una serie de operaciones que desencadenan eventos de sincronización entre el host y el dispositivo, lo que ralentiza considerablemente la velocidad de entrenamiento, ninguno de los cuales implica copiar tensores dentro o fuera de la GPU. Como en nuestra publicación anterior, te desafiamos a identificar tres oportunidades de optimización de rendimiento antes de seguir leyendo.
Para fines de nuestra demostración, utilizamos imágenes generadas aleatoriamente y mapas de etiquetas por píxel, como se define a continuación.
from torch.utils.data import Dataset# Un conjunto de datos con imágenes y mapas de etiquetas aleatoriasclass FakeDataset(Dataset): def __init__(self, num_classes=10): super().__init__() self.num_classes = num_classes self.img_size = [256, 256] def __len__(self): return 1000000 def __getitem__(self, index): rand_image = torch.randn([3]+self.img_size, dtype=torch.float32) rand_label = torch.randint(low=-1, high=self.num_classes, size=self.img_size) return rand_image, rand_labeltrain_set = FakeDataset()train_loader = torch.utils.data.DataLoader(train_set, batch_size=256, shuffle=True, num_workers=8, pin_memory=True)Por último, definimos nuestro paso de entrenamiento con el Perfilador de PyTorch configurado según nuestro deseo:
device = torch.device("cuda:0")model = Net().cuda(device)criterion = MaskedLoss().cuda(device)optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)model.train()# bucle de entrenamiento envuelto con el objeto de perfiladorwith torch.profiler.profile( schedule=torch.profiler.schedule(wait=1, warmup=4, active=3, repeat=1), on_trace_ready=torch.profiler.tensorboard_trace_handler('/tmp/prof'), record_shapes=True, profile_memory=True, with_stack=True) as prof: for step, data in enumerate(train_loader): inputs = data[0].to(device=device, non_blocking=True) labels = data[1].to(device=device, non_blocking=True) if step >= (1 + 4 + 3) * 1: break outputs = model(inputs) loss = criterion(outputs, labels) optimizer.zero_grad(set_to_none=True) loss.backward() optimizer.step() prof.step()Si ejecutara este script de entrenamiento de manera ingenua, probablemente vería una alta utilización de la GPU (~90%) y no sabría que hay algo mal. Solo a través del perfilado podemos identificar los cuellos de botella de rendimiento subyacentes y las posibles oportunidades para acelerar el entrenamiento. Entonces, sin más preámbulos, veamos cómo se desempeña nuestro modelo.
Resultados de rendimiento iniciales
En esta publicación nos centraremos en la Vista de trazas del complemento TensorBoard del Perfilador de PyTorch. Consulte nuestras publicaciones anteriores para obtener consejos sobre cómo utilizar algunas de las otras vistas admitidas por el complemento.
En la imagen a continuación mostramos la Vista de trazas de un solo paso de entrenamiento de nuestro modelo de juguete.
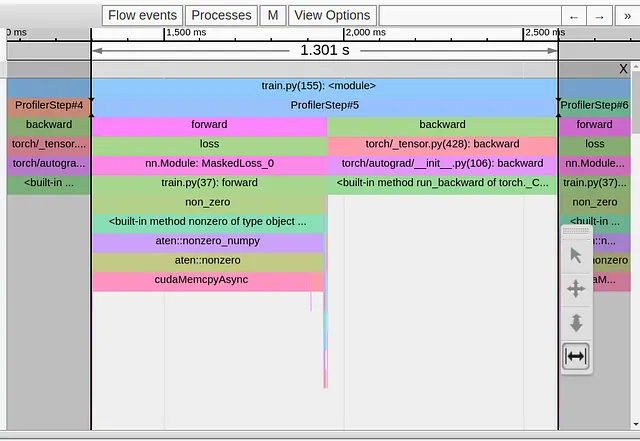
Podemos ver claramente que nuestro paso de entrenamiento de 1.3 segundos está completamente dominado por el operador torch.nonzero en la primera línea de nuestra función de pérdida. Todas las demás operaciones aparecen agrupadas a ambos lados del enorme evento cudaMemcpyAsyn. ¿Qué está pasando??!! ¿Por qué una operación aparentemente inocente causa una molestia tan grande?
Tal vez no deberíamos sorprendernos, ya que la documentación de torch.nonzero incluye la siguiente nota: “Cuando input está en CUDA, torch.nonzero() provoca una sincronización entre el host y el dispositivo”. La necesidad de sincronización surge del hecho de que, a diferencia de otras operaciones comunes de PyTorch, el tamaño del tensor que devuelve torch.nonzero no está predefinido. La CPU no sabe cuántos elementos diferentes de cero hay en el tensor de entrada de antemano. Necesita esperar el evento de sincronización desde la GPU para realizar la asignación de memoria de la GPU adecuada y preparar adecuadamente las operaciones posteriores de PyTorch.
Tenga en cuenta que la duración de cudaMempyAsync no indica la complejidad de la operación torch.nonzero, sino que refleja el tiempo que la CPU necesita esperar a que la GPU termine todos los kernels anteriores que la CPU lanzó. Por ejemplo, si hiciéramos una llamada adicional a torch.nonzero inmediatamente después de la primera, nuestro segundo evento cudaMempyAsync aparecería significativamente más corto que el primero, ya que la CPU y la GPU ya están más o menos “sincronizadas”. (Tenga en cuenta que esta explicación proviene de un experto no experto en CUDA, así que haga de ella lo que quiera…)
Optimización #1: Reducir el uso del operador torch.nonzero
Ahora que entendemos la fuente del cuello de botella, el desafío consiste en encontrar una secuencia alternativa de operaciones que realice la misma lógica pero que no desencadene un evento de sincronización entre el host y el dispositivo. En el caso de nuestra función de pérdida, podemos lograr esto fácilmente utilizando el operador torch.where como se muestra en el bloque de código a continuación:
def ignore_background(self, target: Tensor) -> Tensor: with torch.profiler.record_function('update background'): target = torch.where(target==self.num_classes-1, -1*torch.ones_like(target),target) return targetEn la imagen a continuación mostramos la Vista de trazas después de este cambio.
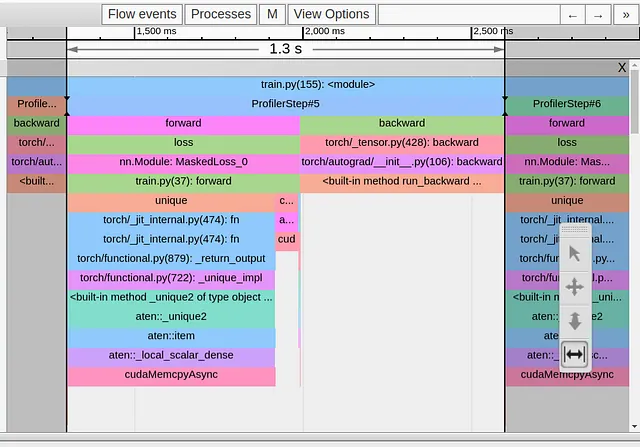
Aunque hemos logrado eliminar el cudaMempyAsync proveniente del operador torch.nonzero, ha sido reemplazado inmediatamente por uno proveniente del operador torch.unique, y nuestro tiempo de paso no ha cambiado. Aquí la documentación de PyTorch es menos amable, pero según nuestra experiencia anterior, podemos asumir que, una vez más, estamos sufriendo un evento de sincronización entre el host y el dispositivo debido al uso de tensores con tamaño indeterminado.
Optimización #2: Reducir el uso del operador torch.unique
No siempre es posible reemplazar el operador torch.unique por una alternativa equivalente. Sin embargo, en nuestro caso, en realidad no necesitamos conocer los valores de las etiquetas únicas, solo necesitamos conocer el número de etiquetas únicas. Esto se puede calcular aplicando la operación torch.sort al tensor objetivo aplanado y contando el número de pasos en la función de paso resultante.
def forward(self, pred: Tensor, target: Tensor) -> Tensor: # ignorar etiquetas de fondo target = self.ignore_background(target) # ordenar la lista de etiquetas with torch.profiler.record_function('sort'): sorted,_ = torch.sort(target.flatten()) # identificar los pasos de la función de paso resultante with torch.profiler.record_function('deriv'): deriv = sorted[1:]-sorted[:-1] # contar el número de pasos with torch.profiler.record_function('count_nonzero'): num_unique = torch.count_nonzero(deriv)+1 # calcular la pérdida de entropía cruzada loss = self.cross_entropy(pred, target) # establecer la pérdida en cero en caso de que el número de elementos únicos # sea inferior al umbral with torch.profiler.record_function('where'): loss = torch.where(num_unique<2, 0.*loss, loss) return lossEn la siguiente imagen capturamos la Vista de Rastreo después de nuestra segunda optimización:
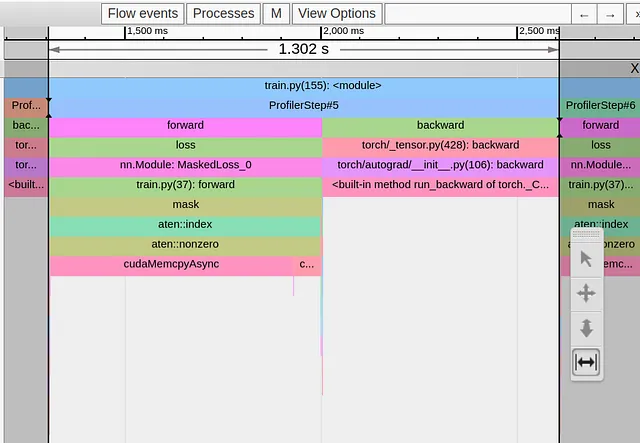
Una vez más, hemos resuelto un cuello de botella solo para enfrentarnos a uno nuevo, en esta ocasión proveniente de la rutina de máscara booleana.
La máscara booleana es una rutina que comúnmente usamos para reducir el número total de operaciones que se requieren en una máquina. En nuestro caso, nuestra intención era reducir la cantidad de cálculos eliminando los píxeles “ignorados” y limitando el cálculo de entropía cruzada a los píxeles de interés. Claramente, esto ha salido mal. Como antes, aplicar una máscara booleana resulta en un tensor de tamaño indeterminado, y el cudaMempyAsync que se desencadena opaca en gran medida cualquier ahorro al excluir los píxeles “ignorados”.
Optimización #3: Tenga cuidado con las operaciones de máscara booleana
En nuestro caso, solucionar este problema es bastante simple ya que PyTorch CrossEntropyLoss tiene una opción incorporada para establecer un ignore_index.
class MaskedLoss(nn.Module): def __init__(self, ignore_val=-1, num_classes=10): super().__init__() self.ignore_val = ignore_val self.num_classes = num_classes self.loss = torch.nn.CrossEntropyLoss(ignore_index=-1) def cross_entropy(self, pred: Tensor, target: Tensor) -> Tensor: with torch.profiler.record_function('calc loss'): loss = self.loss(pred, target) return lossEn la siguiente imagen mostramos la Vista de Rastreo resultante:

¡Vaya! Nuestro tiempo de paso ha disminuido hasta 5.4 milisegundos. Eso es ¡240 veces más rápido que nuestro punto de partida! Simplemente cambiando algunas llamadas de función y sin modificar la lógica de la función de pérdida, pudimos optimizar el rendimiento del paso de entrenamiento de manera drástica.
Nota Importante: En el ejemplo que hemos elegido, los pasos que tomamos para reducir el número de eventos cudaMempyAsync tuvieron un claro impacto en el tiempo de paso de entrenamiento. Sin embargo, puede haber situaciones en las que los mismos tipos de cambios perjudiquen el rendimiento en lugar de mejorarlo. Por ejemplo, en el caso de la máscara booleana, si nuestra máscara es extremadamente dispersa y los tensores originales son extremadamente grandes, los ahorros en cálculos al aplicar la máscara podrían superar el costo de la sincronización entre el host y el dispositivo. Es importante evaluar el impacto de cada optimización caso por caso.
Resumen
En esta publicación nos hemos enfocado en problemas de rendimiento en aplicaciones de entrenamiento causados por eventos de sincronización entre el host y el dispositivo. Vimos varios ejemplos de operadores de PyTorch que desencadenan este tipo de eventos, y todos ellos tienen en común que el tamaño de los tensores que generan depende de la entrada. Es posible que también encuentres eventos de sincronización en otros operadores que no se mencionan en esta publicación. Demostramos cómo se pueden utilizar analizadores de rendimiento como PyTorch Profiler y su complemento asociado de TensorBoard para identificar este tipo de eventos.
En el caso de nuestro ejemplo de juguete, pudimos encontrar alternativas equivalentes a los operadores problemáticos que utilizan tensores de tamaño fijo y evitan la necesidad de eventos de sincronización. Esto condujo a una mejora significativa en el tiempo de entrenamiento. Sin embargo, en la práctica, es posible que te resulte mucho más difícil, incluso imposible, resolver este tipo de cuellos de botella. A veces, superarlos puede requerir rediseñar partes de tu modelo.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- HashGNN Profundizando en el nuevo algoritmo de incrustación de nodos de Neo4j GDS
- Más allá del VIF Análisis de la Colinealidad para Mitigación del Sesgo y Precisión Predictiva
- Ajuste fino de un modelo Llama-2 7B para la generación de código en Python
- Una Guía Completa para MLOps
- Tendencias principales de IA en marketing para observar en 2023
- Mejores Servidores Proxy 2023
- Clave maestra para la separación de fuentes de audio Presentamos AudioSep para separar cualquier cosa que describas






