Cómo optimizar consultas SQL para una recuperación de datos más rápida.
Optimización de consultas SQL para una recuperación de datos más rápida.
Hoy hablaremos sobre por qué la optimización de consultas SQL es importante y qué técnicas se pueden utilizar para optimizarla.

SQL (Structured Query Language), como probablemente sabes, te ayuda a recopilar datos de las bases de datos.
Está diseñado específicamente para eso. En otras palabras, trabaja con filas y columnas, permitiéndote manipular datos de las bases de datos mediante consultas SQL.
- ¿Cómo automatizar el análisis de datos con Langchain?
- Implementar una solución de seguimiento de múltiples objetos en un conjunto de datos personalizado con Amazon SageMaker.
¿Qué es una consulta SQL?
Una consulta SQL es un conjunto de instrucciones que le das a la base de datos para recopilar información de ella.
Puedes recopilar y manipular datos de la base de datos utilizando estas consultas.
Al utilizarlas, puedes crear informes, realizar análisis de datos y más.
Debido a la forma y longitud de estas consultas, los tiempos de ejecución pueden ser significativos, especialmente si se trabaja con tablas de datos más grandes.
¿Por qué necesitamos la optimización de consultas SQL?
El propósito de la optimización de consultas SQL es asegurarse de que utilices eficientemente los recursos. En términos simples, reduce el tiempo de ejecución, ahorra costos y mejora el rendimiento. Es una habilidad importante para desarrolladores y analistas de datos. No solo es importante devolver los datos correctos de la base de datos. También es importante saber cómo hacerlo de manera eficiente.
Siempre debes preguntarte: “¿Hay una mejor manera de escribir mi consulta?”
Hablemos más detalladamente sobre las razones para hacerlo.
Efficiencia de recursos: Las consultas SQL mal optimizadas consumirían recursos del sistema excesivos, como la CPU y la memoria. Esto podría llevar a una reducción del rendimiento general del sistema. La optimización de consultas SQL asegura que estos recursos se utilicen eficientemente. Esto, a su vez, conduce a un mejor rendimiento y escalabilidad.
Tiempo de ejecución reducido: Si las consultas se ejecutan lentamente, esto tendrá un impacto negativo en la experiencia del usuario. O en el rendimiento de una aplicación si tienes una aplicación en funcionamiento. La optimización de consultas puede ayudar a reducir el tiempo de ejecución, proporcionando tiempos de respuesta más rápidos y una mejor experiencia de usuario.
Ahorro de costos: Las consultas optimizadas pueden disminuir el hardware y la infraestructura necesarios para admitir el sistema de base de datos. Esto puede llevar a ahorros de costos en hardware, energía y costos de mantenimiento.
Echa un vistazo a ” Mejores prácticas para escribir consultas SQL ” que pueden ayudarte a descubrir cómo se puede mejorar la estructura de tu código, incluso si es correcta.
Técnicas de optimización de consultas SQL
Aquí tienes una descripción general de las técnicas de optimización de consultas SQL que cubriremos en este artículo.
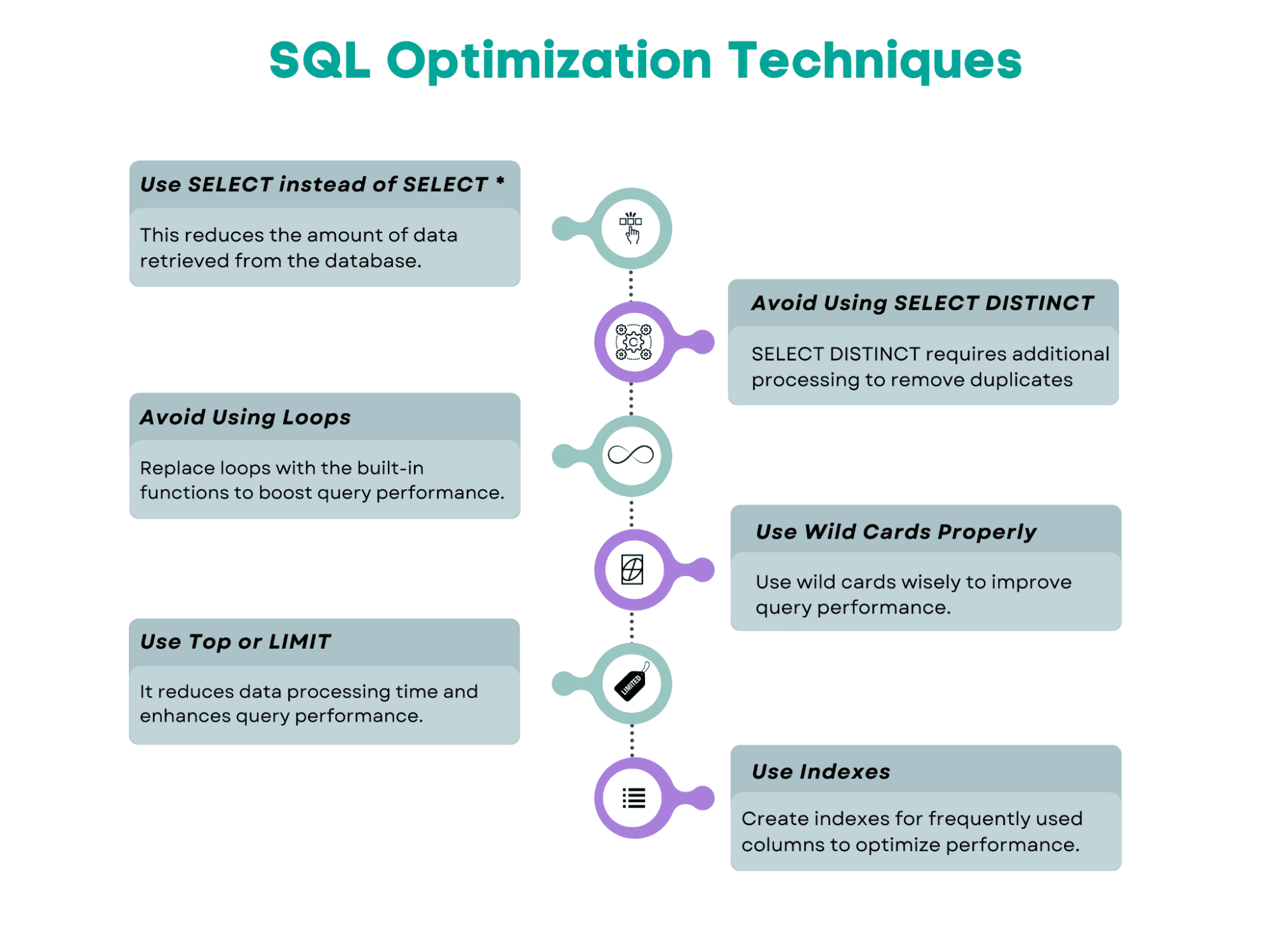
Aquí está el diagrama de flujo que muestra los pasos sugeridos a seguir al optimizar la consulta SQL. Seguiremos el mismo enfoque en nuestros ejemplos. También es importante tener en cuenta que las herramientas de optimización también pueden ayudar a mejorar el rendimiento de las consultas. Entonces, exploremos estas técnicas comenzando con el conocido comando SQL, SELECT. 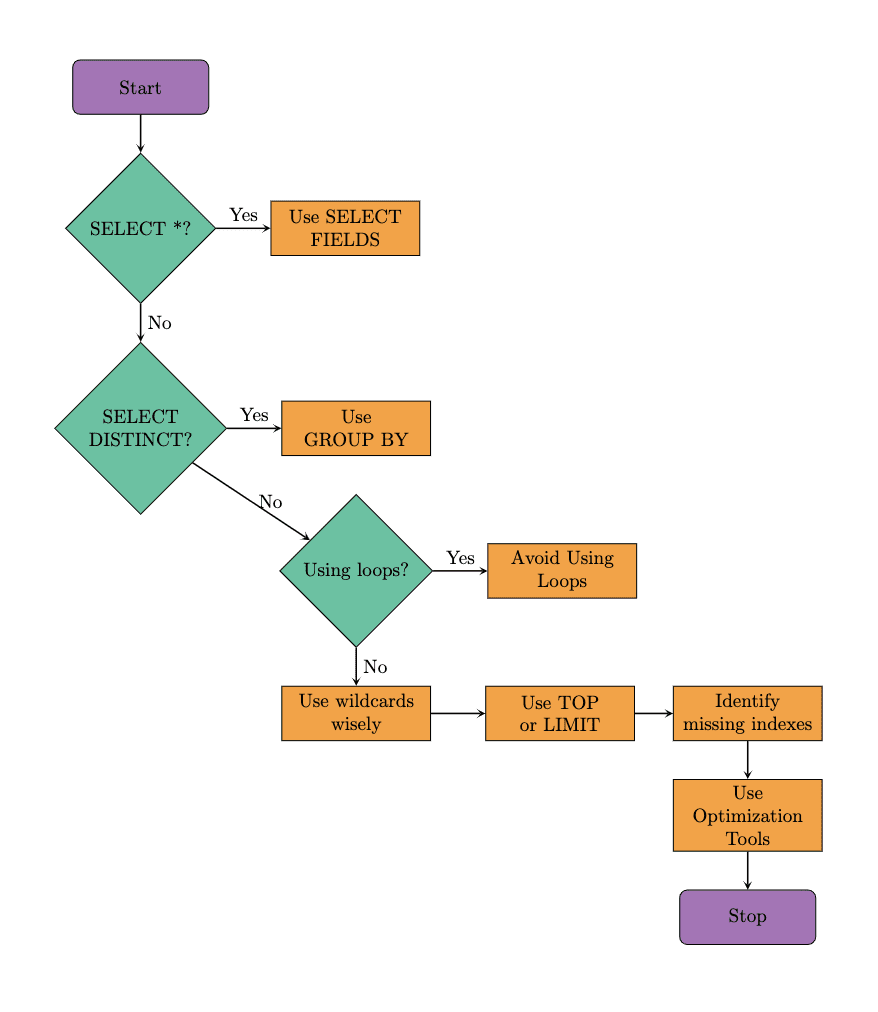
Usa SELECT con campos especificados en lugar de SELECT *
Cuando usas SELECT *, devolverá todas las filas y todas las columnas de la(s) tabla(s). Debes preguntarte si realmente necesitas eso.
En lugar de escanear toda la base de datos, usa los campos específicos después de SELECT.
En el ejemplo, reemplazaremos SELECT * por nombres de columna específicos. Como verás, esto reducirá la cantidad de datos recuperados.
Como resultado, las consultas se ejecutan más rápidamente ya que la base de datos debe obtener y proporcionar las columnas solicitadas, no todas las columnas de la tabla.
Esto minimiza la carga de E / S en la base de datos, lo que es especialmente útil cuando una tabla incluye muchas columnas o muchas filas de datos.
A continuación se muestra el código antes de la optimización.
SELECT * FROM customer;Aquí está el resultado.
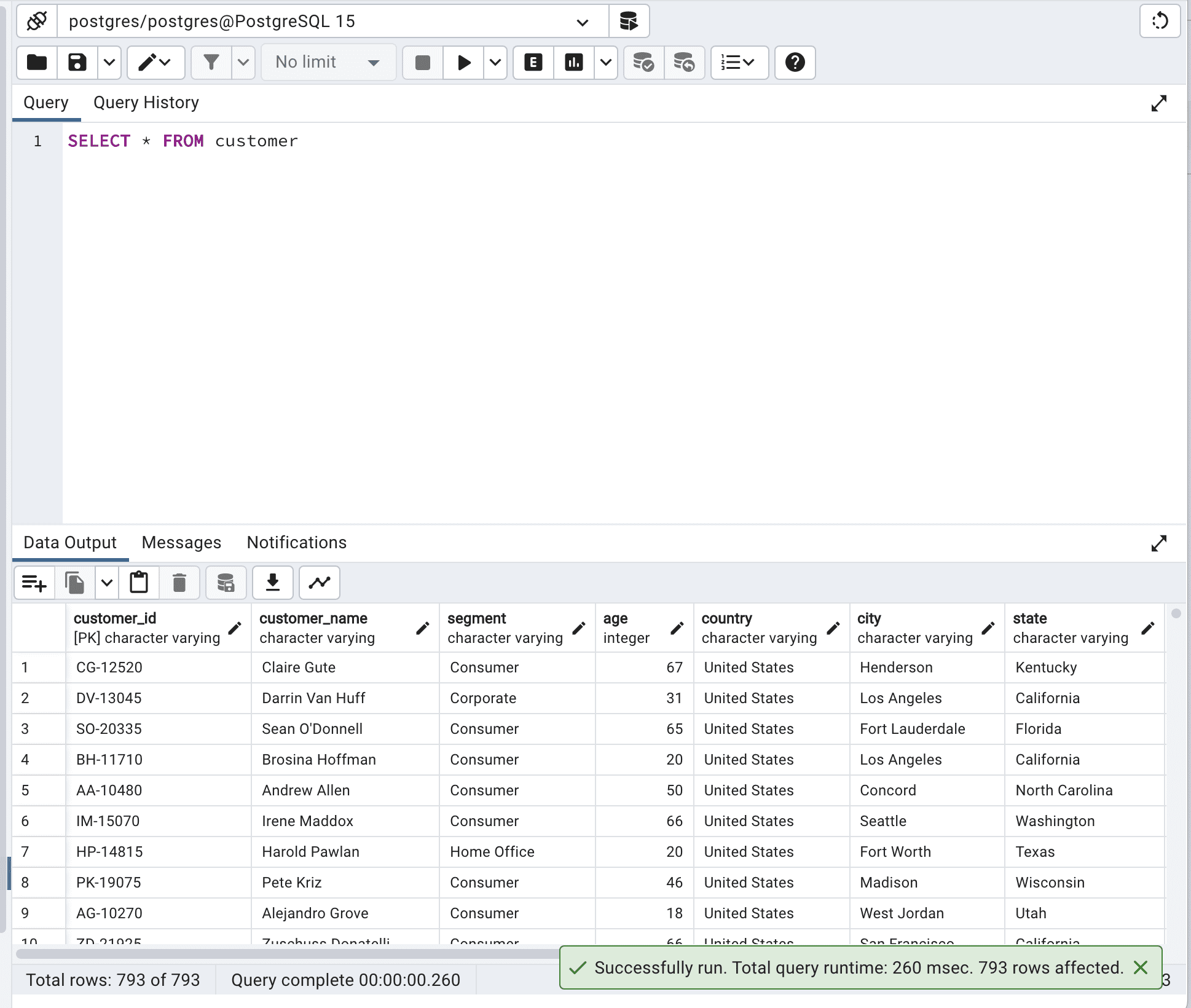
El tiempo total de ejecución de la consulta es de 260 msec. Esto puede mejorarse.
Para mostrarte eso, seleccionaré solo 3 columnas diferentes en lugar de seleccionar todas.
Puede seleccionar la columna que necesita según las necesidades de su proyecto.
Aquí está el código.
SELECT customer_id,
age,
country
FROM customer;Y este es el resultado.
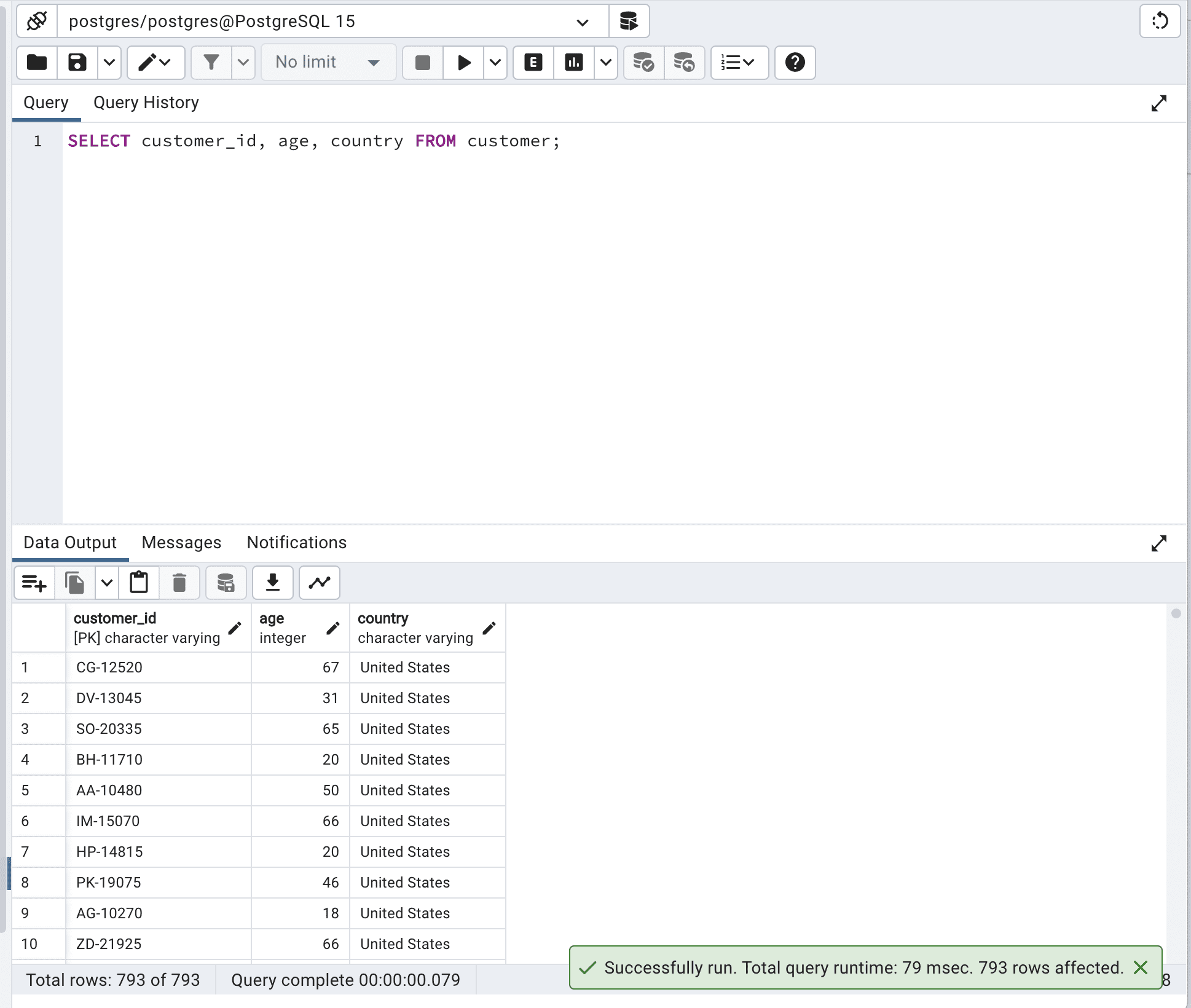
Como puede ver, al definir los campos que queremos seleccionar, no obligamos a la base de datos a escanear todos los datos que tiene, por lo que el tiempo de ejecución se reduce de 260 a 79 milisegundos.
Imagínese cuál sería la diferencia con millones o miles de millones de filas. O cientos de columnas.
Evite usar SELECT DISTINCT
SELECT DISTINCT se utiliza para devolver valores únicos en una columna especificada. Para hacerlo, el motor de base de datos debe escanear toda la tabla y eliminar los valores duplicados. En muchos casos, el uso de un enfoque alternativo como GROUP BY puede conducir a un mejor rendimiento al reducir el número de datos procesados.
Aquí está el código.
SELECT DISTINCT segment
FROM customer;Este es el resultado.
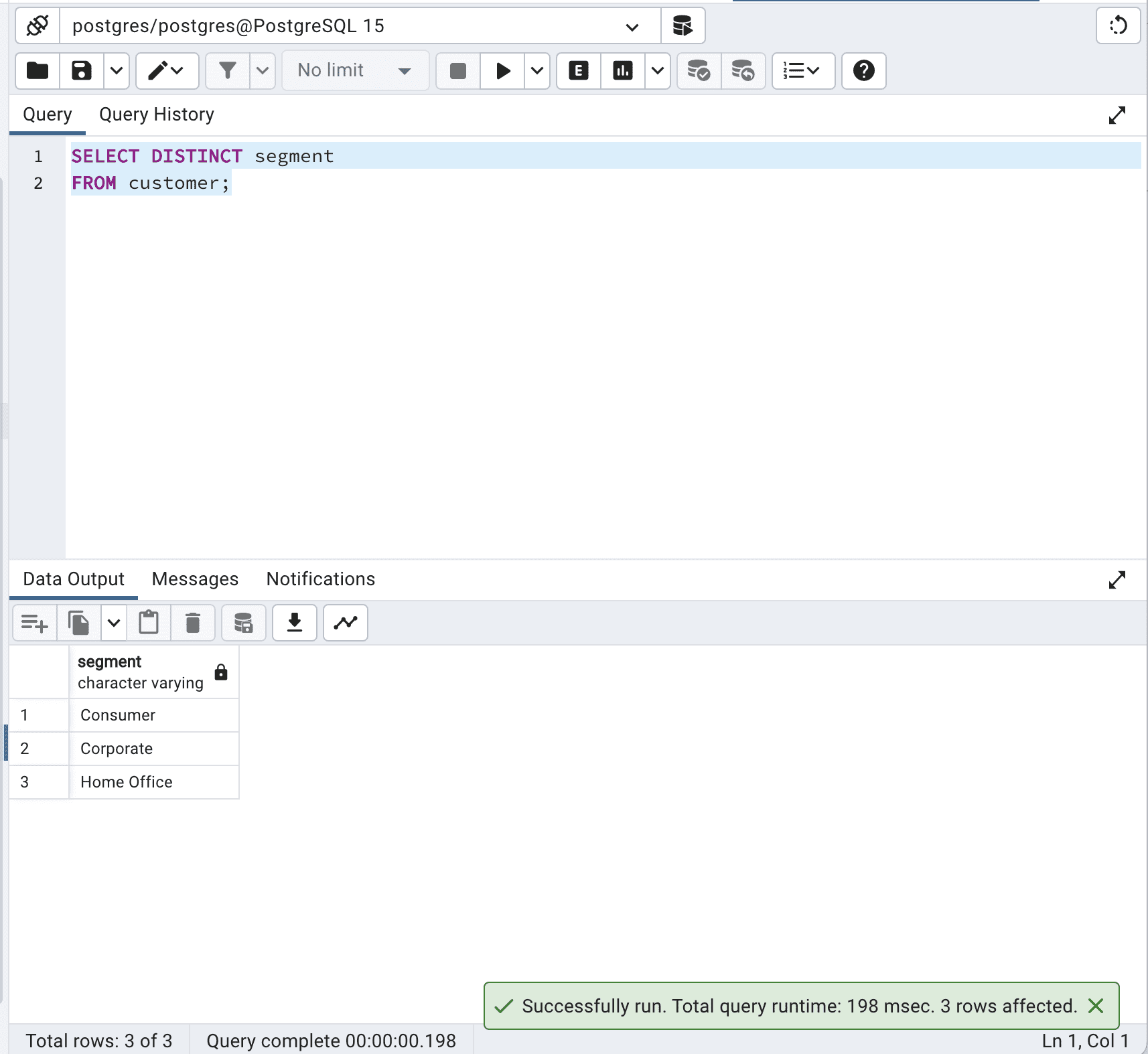
Nuestro código recupera los valores únicos en la columna “segment” de la tabla “customer”. El motor de base de datos debe procesar todos los registros de la tabla, identificar los valores duplicados y devolver solo los valores únicos. Esto puede ser costoso en términos de tiempo y recursos, especialmente para tablas grandes.
En la versión alternativa, la siguiente consulta recupera los valores únicos en la columna “segment” mediante el uso de una cláusula GROUP BY. La cláusula GROUP BY agrupa los registros en función de la(s) columna(s) especificada(s) y devuelve un registro por cada grupo.
Aquí está el código.
SELECT segment
FROM customer
GROUP BY segment;Este es el resultado.
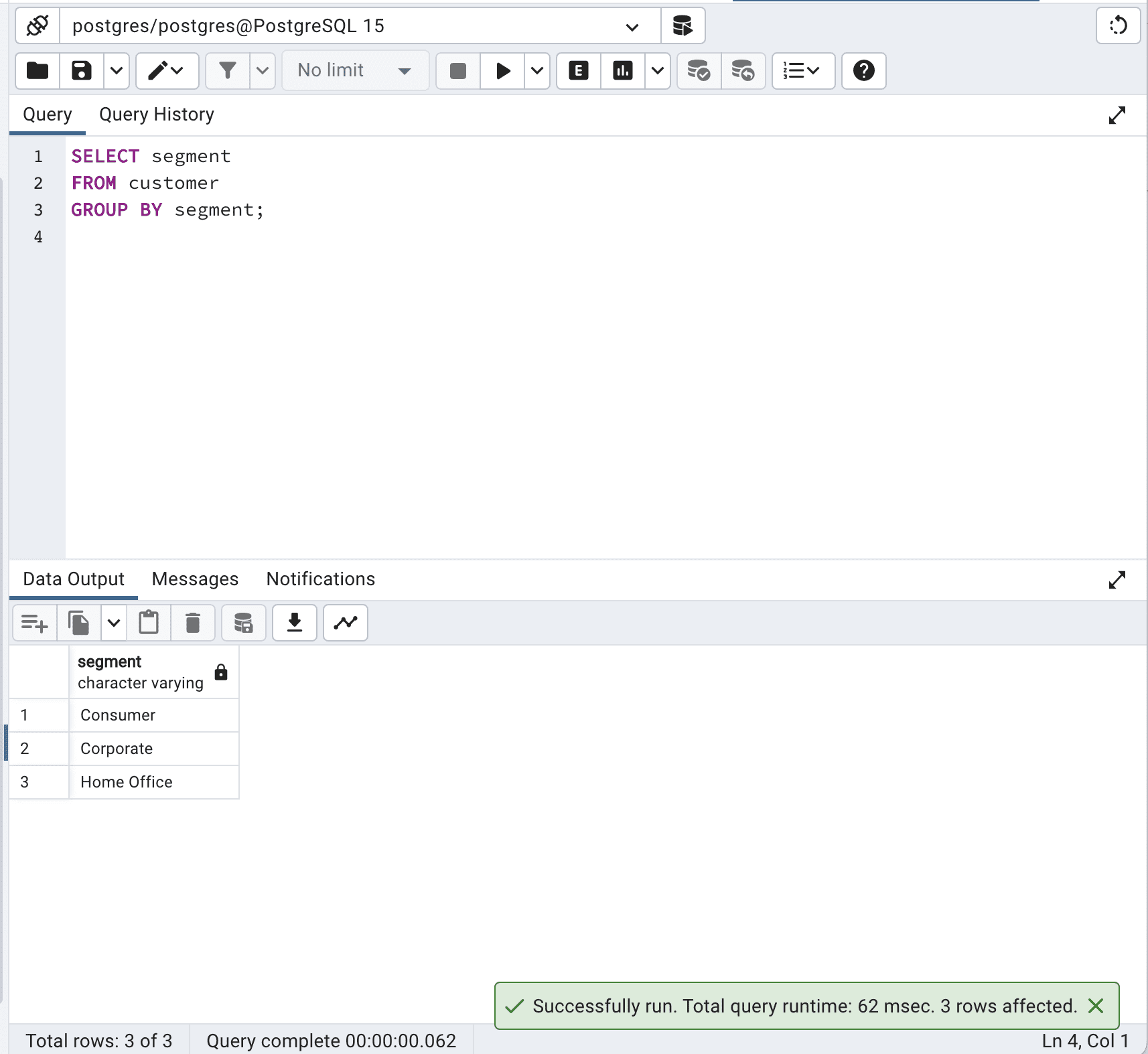
En este caso, la cláusula GROUP BY agrupa eficazmente los registros por la columna “segment”, lo que resulta en el mismo resultado que la consulta SELECT DISTINCT.
Al evitar SELECT DISTINCT y utilizar GROUP BY en su lugar, puede optimizar las consultas SQL y reducir el tiempo total de consulta de 198 a 62 milisegundos, lo que es más de 3 veces más rápido.
Evite usar bucles
Los bucles pueden causar que su consulta sea más lenta ya que obligan a la base de datos a recorrer los registros uno por uno.
Cuando sea posible, utilice operaciones integradas y funciones SQL, que pueden aprovechar las optimizaciones del motor de base de datos y procesar datos de manera más eficiente.
Definamos una función personalizada con un bucle.
CREATE OR REPLACE FUNCTION sum_ages_with_loop() RETURNS TABLE (country_name TEXT, sum_age INTEGER) AS $$
DECLARE
country_record RECORD;
age_sum INTEGER;
BEGIN
FOR country_record IN SELECT DISTINCT country FROM customer WHERE segment = 'Corporate'
LOOP
SELECT SUM(age) INTO age_sum FROM customer WHERE country = country_record.country AND segment = 'Corporate';
country_name := country_record.country;
sum_age := age_sum;
RETURN NEXT;
END LOOP;
END;
$$ LANGUAGE plpgsql;El código anterior utiliza un enfoque basado en bucles para calcular la suma de edades para cada país donde el segmento del cliente es ‘Corporate’.
Primero recupera una lista de países distintos y luego itera a través de cada país utilizando un bucle, calculando la suma de las edades de los clientes en ese país. Este enfoque puede ser lento e ineficiente, ya que procesa los datos fila por fila.
Ahora ejecutemos esta función.
SELECT *
FROM sum_ages_with_loop()Este es el resultado.
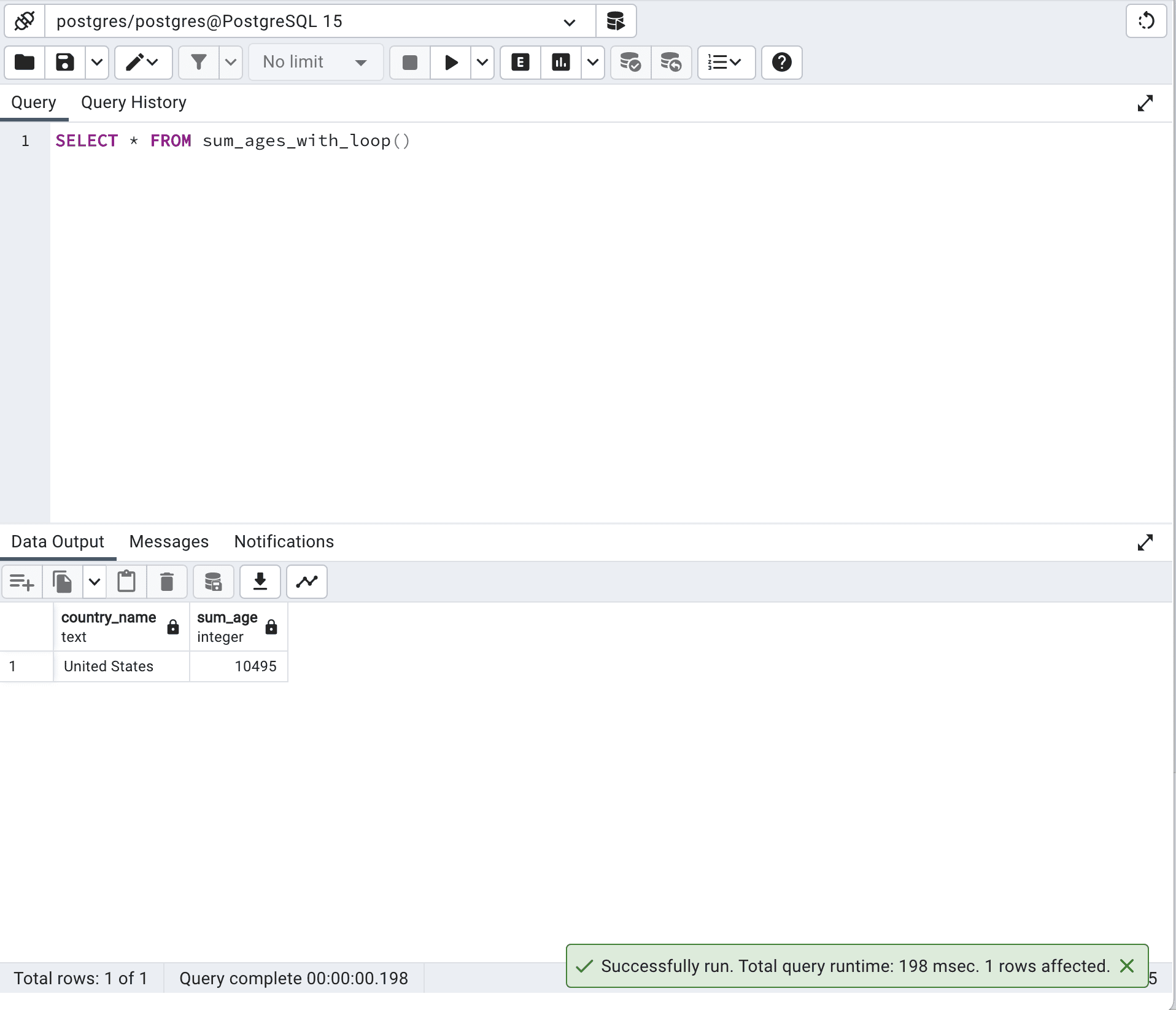
El tiempo de ejecución con este enfoque es de 198 milisegundos.
Veamos ahora nuestro código SQL optimizado.
SELECT country,
SUM(age) AS sum_age
FROM customer
WHERE segment = 'Corporate'
GROUP BY country;Aquí está su resultado.
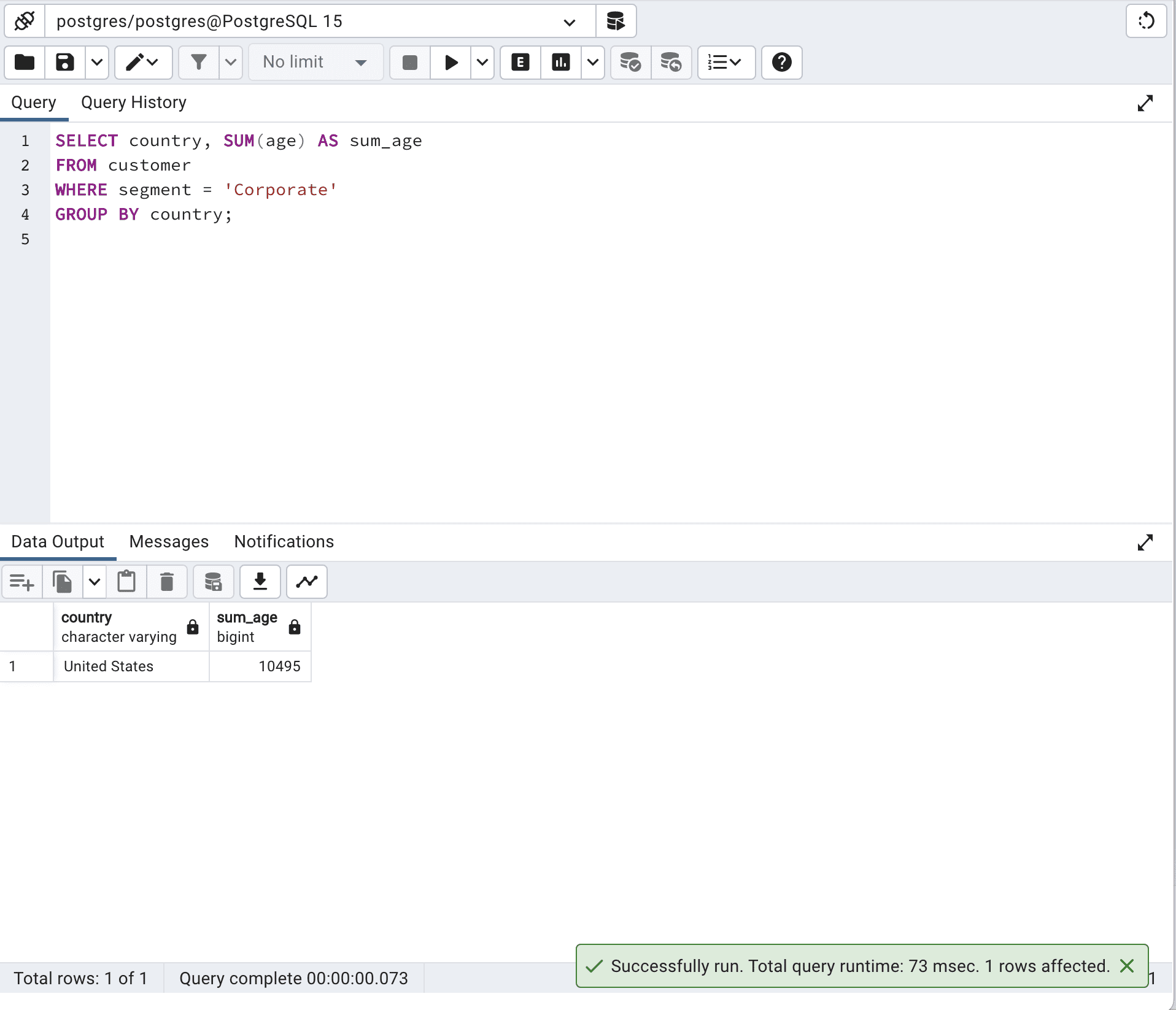
En general, la versión optimizada que utiliza una única consulta SQL funcionará mejor, ya que aprovecha las capacidades de optimización del motor de base de datos.
Para obtener el mismo resultado en nuestro primer código, utilizamos un bucle en una función PL/pgSQL, lo cual suele ser más lento y menos efectivo que hacerlo con una única consulta SQL. ¡Y te obliga a escribir muchas más líneas de código!
Usa los comodines correctamente
El uso adecuado de los comodines es vital para optimizar las consultas SQL, especialmente cuando se trata de buscar cadenas y patrones.
Los comodines son caracteres especiales utilizados en las consultas SQL para buscar patrones específicos.
Los comodines más comunes en SQL son “% ” y “_”, donde “%” representa cualquier secuencia de caracteres y “_” representa un solo carácter.
Usar los comodines sabiamente es importante porque un uso inadecuado puede provocar problemas de rendimiento, especialmente en bases de datos grandes.
Sin embargo, usarlos eficientemente puede mejorar considerablemente el rendimiento de las consultas de coincidencia de cadenas y patrones.
Ahora veamos nuestro ejemplo.
Esta consulta utiliza la función RIGHT() para extraer los últimos tres caracteres de la columna customer_name y luego comprueba si es igual a ‘son’.
SELECT customer_name
FROM customer
WHERE RIGHT(customer_name, 3) = 'son';Aquí está el resultado.
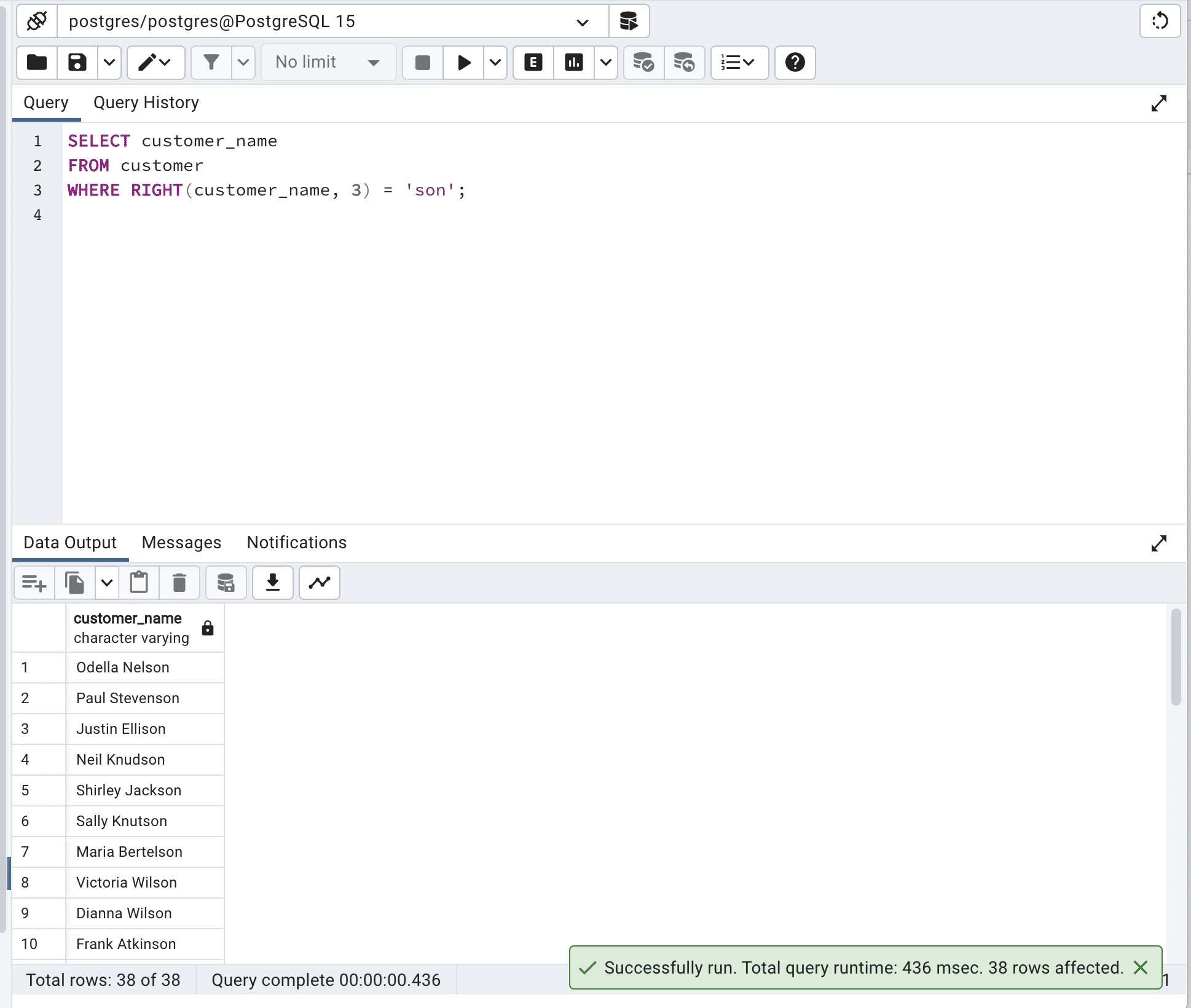
Aunque esta consulta logra el resultado deseado, no es muy eficiente porque se tiene que aplicar la función RIGHT() a cada fila de la tabla.
Optimicemos nuestro código usando comodines.
SELECT customer_name
FROM customer
WHERE customer_name LIKE '%son';Aquí está el resultado.
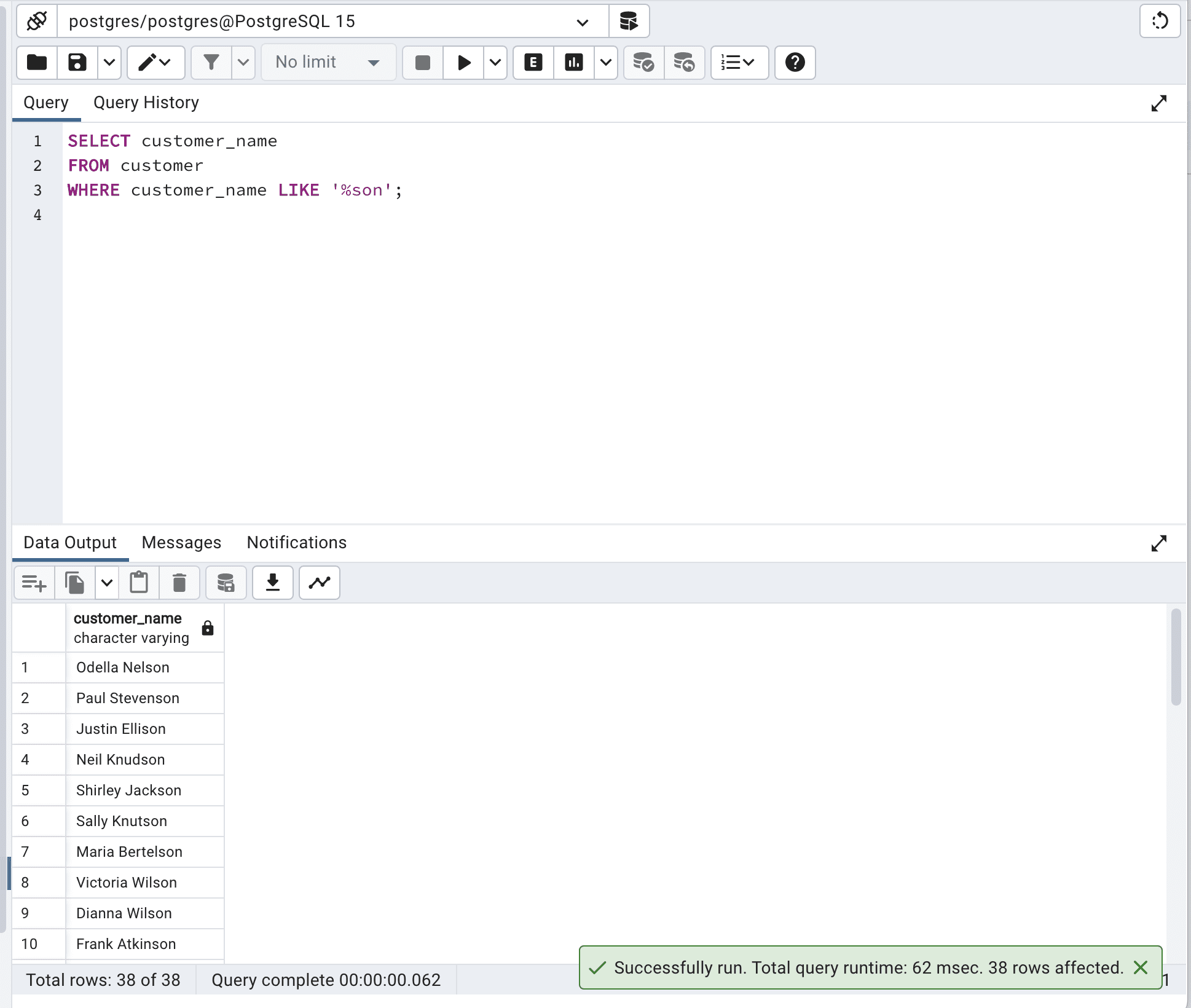
Esta consulta SQL optimizada utiliza el operador LIKE y el comodín “%” para buscar registros donde la columna customer_name termina con ‘son’.
Este enfoque es más eficiente porque aprovecha las capacidades de coincidencia de patrones del motor de base de datos y puede hacer un mejor uso de los índices si están disponibles.
Y como podemos ver, el tiempo total de la consulta se reduce de 436 msec a 62 msec, lo que es casi 7 veces más rápido.
Usa TOP o LIMIT para limitar el número de resultados de muestra
Usar TOP o LIMIT para limitar los resultados de muestra es vital para optimizar las consultas SQL, especialmente cuando se trata de tablas grandes.
Estas cláusulas te permiten recuperar solo un número especificado de registros de una tabla en lugar de todos los registros, lo cual puede ser beneficioso para el rendimiento.
Ahora, recuperemos toda la información de la tabla de clientes.
SELECT *
FROM customerAquí está el resultado.
Cuando se trata de tablas más grandes, esta operación puede aumentar la E/S y la latencia de la red, lo que puede disminuir el rendimiento de tu consulta SQL.
Optimicemos nuestro código limitando la salida a 10.
SELECT *
FROM customer
LIMIT 10;Aquí está el resultado.
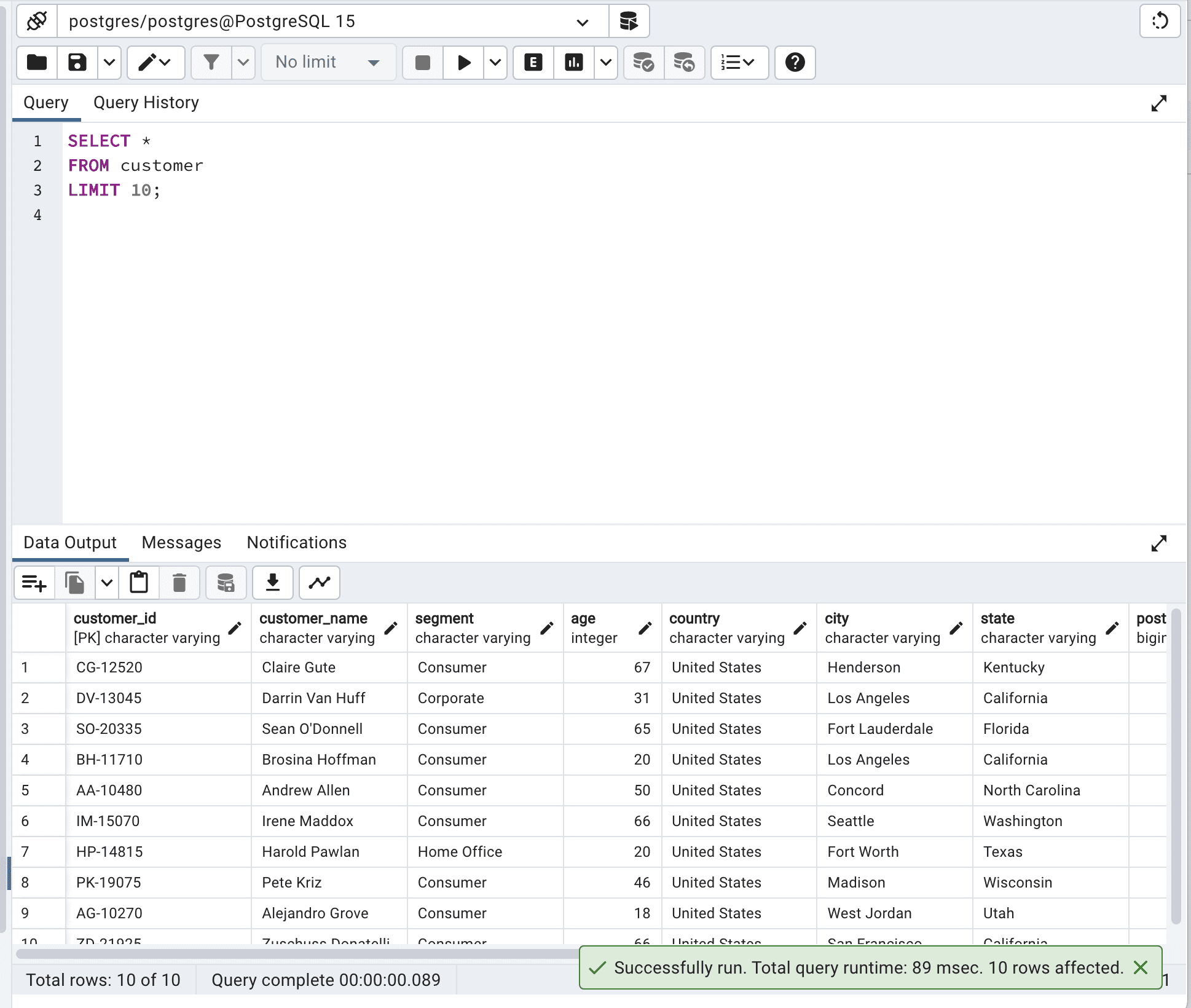
Al limitar la salida, reducirás la latencia de la red y el uso de memoria, y mejorarás el tiempo de respuesta, especialmente con tablas más grandes. En nuestro ejemplo, después de la optimización de la consulta SQL, el tiempo de ejecución total se redujo de 260msec a 89msec.
Por lo tanto, nuestra consulta se vuelve casi 3 veces más rápida.
Usa índices
Esta vez, identificaremos y crearemos índices adecuados para las columnas utilizadas en las cláusulas WHERE, JOIN y ORDER BY para mejorar el rendimiento de la consulta.
Al indexar las columnas de acceso frecuente, la base de datos puede recuperar datos más rápidamente.
Ahora, ejecutemos la siguiente consulta primero.
SELECT customer_id,
customer_name
FROM customer
WHERE segment = 'Corporate';Aquí está la salida. 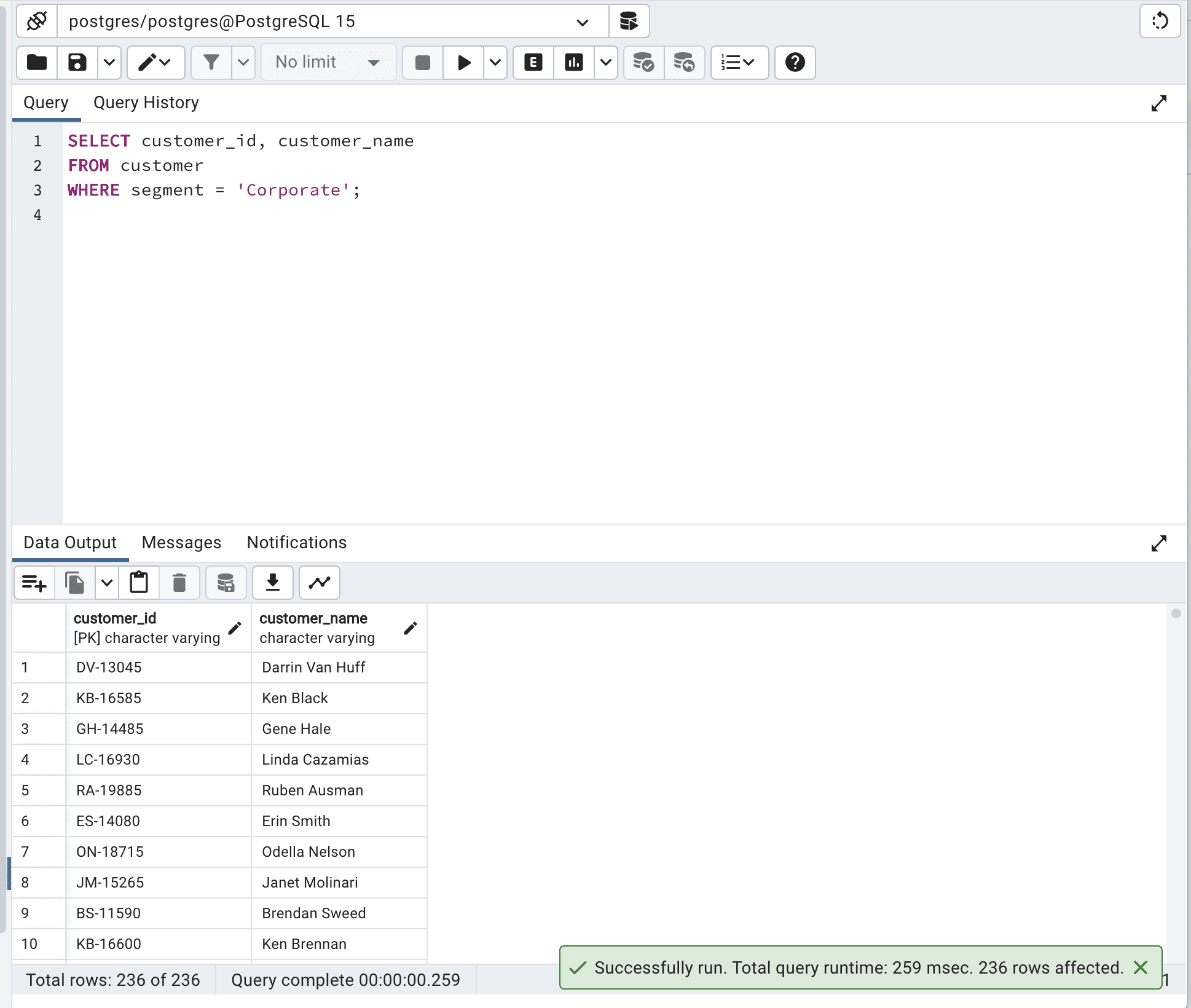
Nuestro tiempo de ejecución de consulta es de 259 milisegundos.
Intentemos mejorar eso creando el índice.
CREATE INDEX idx_segment ON customer (segment);Genial, ahora ejecutemos nuestro código de nuevo.
SELECT customer_id,
customer_name
FROM customer WITH (INDEX(idx_segment))
WHERE segment = 'Corporate';Aquí está la salida.
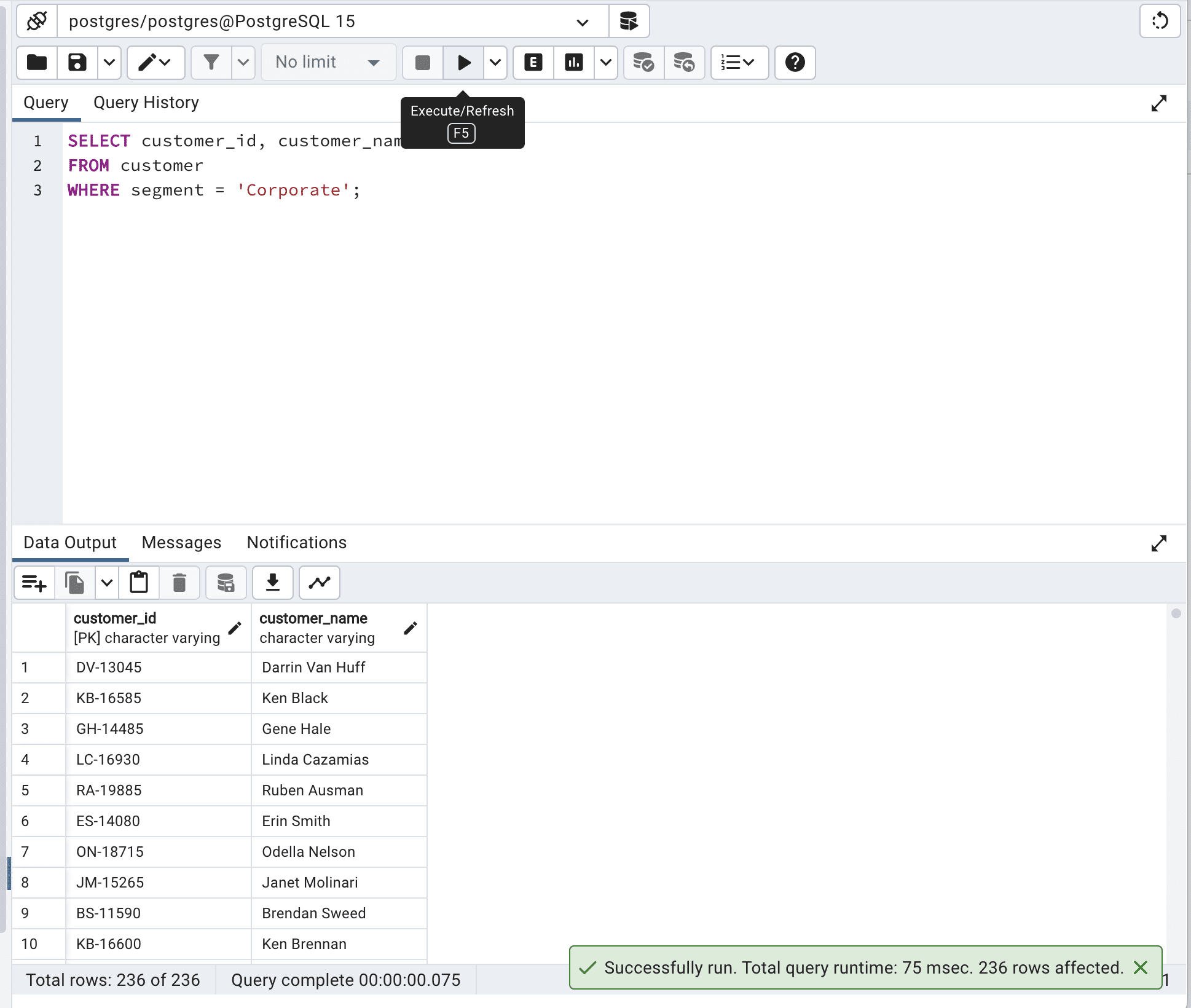
Al usar idx_segment en INDEX(), el motor de base de datos pudo buscar eficientemente en la tabla de clientes basado en la columna de segmento, haciendo que la consulta se ejecute más rápido: redujo el tiempo total de la consulta de 259 milisegundos a 75 milisegundos.
Sección de bonificación: Use herramientas de optimización de consultas SQL
Debido a la complejidad de códigos extensos y consultas altamente complejas, es posible que desee considerar el uso de herramientas de optimización de consultas.
Estas herramientas pueden analizar sus planes de ejecución de consulta, identificar índices faltantes y sugerir estructuras de consulta alternativas para ayudar a optimizar sus consultas. Algunas herramientas populares de optimización de consultas incluyen:
- SolarWinds Database Performance Analyzer : Esta herramienta lo ayuda a monitorear y mejorar el rendimiento de la base de datos. Le muestra los problemas con las consultas y cómo se ejecutan. Funciona con diferentes sistemas de base de datos como SQL Server, Oracle y MySQL.
Lo puedes encontrar aquí .
- SQL Query Tuner for SQL Diagnostic Manager : Esta herramienta tiene características avanzadas para hacer que las consultas funcionen mejor, como consejos de rendimiento, verificación de índices y mostrar cómo se ejecutan las consultas. Lo ayuda a mejorar las consultas SQL encontrando y solucionando problemas.
- SQL Server Management Studio (SSMS) : SSMS tiene herramientas integradas para verificar el rendimiento y mejorar las consultas, como Monitor de actividad, Análisis de plan de ejecución y Asistente para ajuste de índices.
- EverSQL: EverSQL es una herramienta en línea que mejora automáticamente sus consultas al mirar la estructura de la base de datos y cómo se ejecutan las consultas. Te da consejos y reescribe tus consultas SQL para hacerlas funcionar más rápido.
El uso de herramientas y recursos de optimización de consultas SQL es vital para mejorar tus consultas. Con estas herramientas, puedes aprender cómo funcionan tus consultas, encontrar problemas y usar las mejores prácticas para obtener datos más rápidamente y mejorar tus aplicaciones.
Si deseas simplificar tus consultas SQL complejas, mira esto ” Cómo simplificar consultas SQL complejas “.
Notas finales
Los cambios que hicimos al optimizar las consultas SQL anteriores pueden parecer insignificantes debido a su escala (ms). Pero a medida que la cantidad de datos con los que trabajas aumenta, estos milisegundos aumentarán a segundos, minutos y posiblemente incluso horas. Te darás cuenta entonces de que estas técnicas de optimización de consultas SQL son muy importantes.
Si buscas más información, aquí están las 30 mejores preguntas de entrevista sobre consultas SQL, que ayudarán a aquellos que también quieran prepararse para una entrevista al aprender.
¡Gracias por leer! Nate Rosidi es un científico de datos y estratega de productos. También es profesor adjunto que enseña análisis y es el fundador de StrataScratch , una plataforma que ayuda a los científicos de datos a prepararse para sus entrevistas con preguntas de entrevista reales de las principales empresas. Conéctate con él en Twitter: StrataScratch o LinkedIn .
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles