Mejora Amazon Lex con LLMs y mejora la experiencia de las preguntas frecuentes utilizando la ingestión de URL
Optimiza Amazon Lex con LLMs y mejora la experiencia de preguntas frecuentes con la ingestión de URL
En el mundo digital actual, la mayoría de los consumidores prefieren encontrar respuestas a sus preguntas de servicio al cliente por sí mismos en lugar de tomar el tiempo para comunicarse con las empresas y/o proveedores de servicios. Esta publicación de blog explora una solución innovadora para construir un chatbot de preguntas y respuestas en Amazon Lex que utiliza las preguntas frecuentes existentes de su sitio web. Esta herramienta con inteligencia artificial puede proporcionar respuestas rápidas y precisas a consultas del mundo real, permitiendo que el cliente resuelva de manera rápida y fácil problemas comunes de forma independiente.
Ingestión de URL única
Muchas empresas tienen un conjunto de respuestas publicadas para preguntas frecuentes de sus clientes disponibles en su sitio web. En este caso, queremos ofrecer a los clientes un chatbot que pueda responder a sus preguntas a partir de nuestras preguntas frecuentes publicadas. En la publicación de blog titulada Mejore Amazon Lex con funciones de preguntas frecuentes conversacionales utilizando LLMs, demostramos cómo puede utilizar una combinación de Amazon Lex y LlamaIndex para construir un chatbot basado en sus fuentes de conocimiento existentes, como documentos PDF o Word. Para admitir una FAQ simple, basada en un sitio web de preguntas frecuentes, necesitamos crear un proceso de ingestión que pueda rastrear el sitio web y crear embeddings que puedan ser utilizados por LlamaIndex para responder preguntas de los clientes. En este caso, construiremos sobre el bot creado en la publicación de blog anterior, que consulta esos embeddings con la expresión del usuario y devuelve la respuesta de las preguntas frecuentes del sitio web.
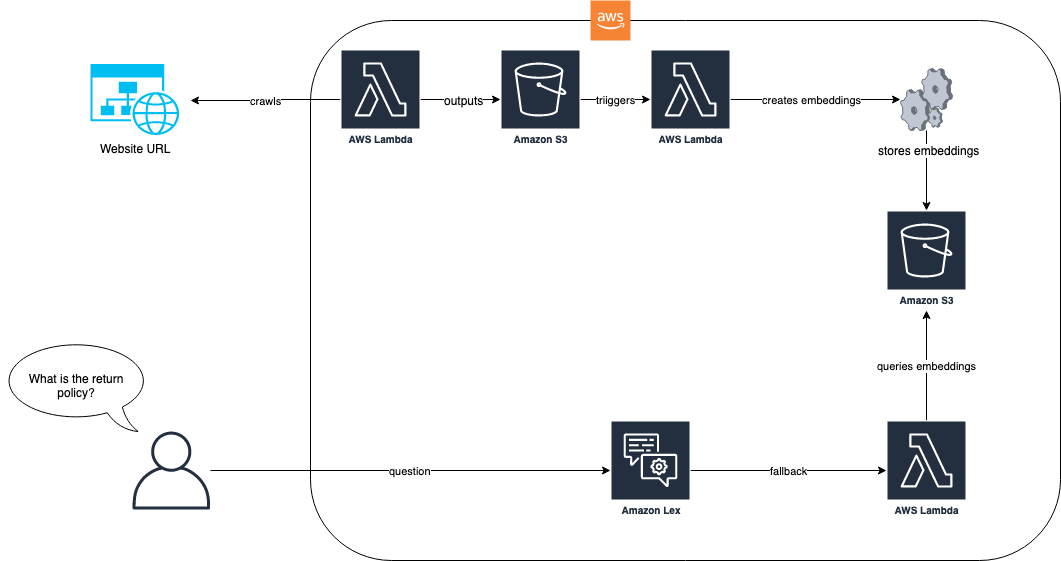
El siguiente diagrama muestra cómo el proceso de ingestión y el bot de Amazon Lex funcionan juntos para nuestra solución.
- Mejora Amazon Lex con características de preguntas frecuentes conversacionales utilizando LLMs
- Llama 2 está aquí – obténlo en Hugging Face
- Los actores aseguran que los estudios quieren usar réplicas de IA
En el flujo de trabajo de la solución, el sitio web con preguntas frecuentes se ingiere a través de AWS Lambda. Esta función de Lambda rastrea el sitio web y almacena el texto resultante en un bucket de Amazon Simple Storage Service (Amazon S3). El bucket de S3 luego activa una función de Lambda que utiliza LlamaIndex para crear embeddings que se almacenan en Amazon S3. Cuando llega una pregunta de un usuario final, como “¿Cuál es su política de devolución?”, el bot de Amazon Lex utiliza su función de Lambda para consultar los embeddings utilizando un enfoque basado en RAG con LlamaIndex. Para obtener más información sobre este enfoque y los requisitos previos, consulte la publicación de blog, Mejore Amazon Lex con funciones de preguntas frecuentes conversacionales utilizando LLMs.
Después de completar los requisitos previos de la publicación de blog mencionada anteriormente, el primer paso es ingresar las preguntas frecuentes en un repositorio de documentos que puede ser vectorizado e indexado por LlamaIndex. El siguiente código muestra cómo lograr esto:
import logging
import sys
import requests
import html2text
from llama_index.readers.schema.base import Document
from llama_index import GPTVectorStoreIndex
from typing import List
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
class EZWebLoader:
def __init__(self, default_header: str = None):
self._html_to_text_parser = html2text()
if default_header is None:
self._default_header = {"User-agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36"}
else:
self._default_header = default_header
def load_data(self, urls: List[str], headers: str = None) -> List[Document]:
if headers is None:
headers = self._default_header
documents = []
for url in urls:
response = requests.get(url, headers=headers).text
response = self._html2text.html2text(response)
documents.append(Document(response))
return documents
url = "http://www.zappos.com/general-questions"
loader = EZWebLoader()
documents = loader.load_data([url])
index = GPTVectorStoreIndex.from_documents(documents)En el ejemplo anterior, tomamos una URL de un sitio web de preguntas frecuentes predefinido de Zappos y lo ingresamos utilizando la clase EZWebLoader. Con esta clase, hemos navegado a la URL y cargado todas las preguntas que están en la página en un índice. Ahora podemos hacer una pregunta como “¿Zappos tiene tarjetas de regalo?” y obtener las respuestas directamente de nuestras preguntas frecuentes en el sitio web. La siguiente captura de pantalla muestra la consola de pruebas del bot de Amazon Lex respondiendo esa pregunta a partir de las preguntas frecuentes.

Pudimos lograr esto porque habíamos rastreado la URL en el primer paso y creado embeddings que LlamaIndex podría usar para buscar la respuesta a nuestra pregunta. La función Lambda de nuestro bot muestra cómo se ejecuta esta búsqueda cada vez que se devuelve la intención de fallback:
import time
import json
import os
import logging
import boto3
from llama_index import StorageContext, load_index_from_storage
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
def download_docstore():
# Crear un cliente de S3
s3 = boto3.client('s3')
# Enumerar todos los objetos en el bucket de S3 y descargar cada uno
try:
bucket_name = 'faq-bot-storage-001'
s3_response = s3.list_objects_v2(Bucket=bucket_name)
if 'Contents' in s3_response:
for item in s3_response['Contents']:
file_name = item['Key']
logger.debug("Descargando en /tmp/" + file_name)
s3.download_file(bucket_name, file_name, '/tmp/' + file_name)
logger.debug('Todos los archivos descargados de S3 y escritos en el sistema de archivos local.')
except Exception as e:
logger.error(e)
raise e
# descargar el almacenamiento de documentos localmente
download_docstore()
storage_context = StorageContext.from_defaults(persist_dir="/tmp/")
# cargar el índice
index = load_index_from_storage(storage_context)
query_engine = index.as_query_engine()
def lambda_handler(event, context):
"""
Enrutar la solicitud entrante en función de la intención.
El cuerpo JSON de la solicitud se proporciona en la ranura del evento.
"""
# De forma predeterminada, tratamos la solicitud del usuario como si viniera de la zona horaria de America/New_York.
os.environ['TZ'] = 'America/New_York'
time.tzset()
logger.debug("===== COMIENZO DE LEX FULFILLMENT ====")
logger.debug(event)
slots = {}
if "currentIntent" in event and "slots" in event["currentIntent"]:
slots = event["currentIntent"]["slots"]
intent = event["sessionState"]["intent"]
dialogaction = {"type": "Delegate"}
message = []
if str.lower(intent["name"]) == "fallbackintent":
# ejecutar la consulta a partir de la entrada proporcionada por el usuario
response = str.strip(query_engine.query(event["inputTranscript"]).response)
dialogaction["type"] = "Close"
message.append({'content': f'{response}', 'contentType': 'PlainText'})
final_response = {
"sessionState": {
"dialogAction": dialogaction,
"intent": intent
},
"messages": message
}
logger.debug(json.dumps(final_response, indent=1))
logger.debug("===== FIN DE LEX FULFILLMENT ====")
return final_responseEsta solución funciona bien cuando una sola página web tiene todas las respuestas. Sin embargo, la mayoría de los sitios de preguntas frecuentes no se construyen en una sola página. Por ejemplo, en nuestro ejemplo de Zappos, si hacemos la pregunta “¿Tienen una política de igualación de precios?”, obtenemos una respuesta insatisfactoria, como se muestra en la siguiente captura de pantalla.
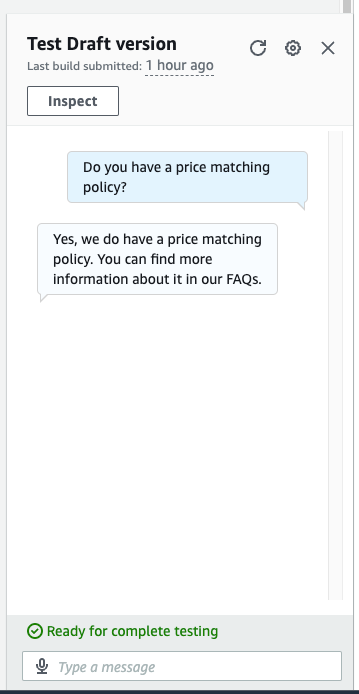
En la interacción anterior, la respuesta de la política de igualación de precios no es útil para nuestro usuario. Esta respuesta es breve porque la pregunta frecuente referenciada es un enlace a una página específica sobre la política de igualación de precios y nuestro rastreo web fue solo para esa única página. Obtener respuestas mejores implicará rastrear también estos enlaces. La siguiente sección muestra cómo obtener respuestas a preguntas que requieren dos o más niveles de profundidad de página.
Rastreo de n niveles
Cuando rastreamos una página web para obtener conocimientos de preguntas frecuentes, la información que queremos puede estar contenida en páginas enlazadas. Por ejemplo, en nuestro ejemplo de Zappos, hacemos la pregunta “¿Tienen una política de igualación de precios?” y la respuesta es “Sí, visita <enlace> para obtener más información”. Si alguien pregunta “¿Cuál es su política de igualación de precios?”, queremos dar una respuesta completa con la política. Para lograr esto, necesitamos recorrer los enlaces para obtener la información real para nuestro usuario final. Durante el proceso de ingestión, podemos usar nuestro cargador web para encontrar los enlaces de anclaje a otras páginas HTML y luego recorrerlos. El siguiente cambio de código en nuestro rastreador web nos permite encontrar enlaces en las páginas que rastreamos. También incluye cierta lógica adicional para evitar rastreos circulares y permitir un filtro por prefijo.
import logging
import requests
import html2text
from llama_index.readers.schema.base import Document
from typing import List
import re
def find_http_urls_in_parentheses(s: str, prefix: str = None):
pattern = r'\((https?://[^)]+)\)'
urls = re.findall(pattern, s)
matched = []
if prefix is not None:
for url in urls:
if str(url).startswith(prefix):
matched.append(url)
else:
matched = urls
return list(set(matched)) # eliminar duplicados convirtiendo a conjunto, luego convertir de nuevo a lista
class EZWebLoader:
def __init__(self, default_header: str = None):
self._html_to_text_parser = html2text
if default_header is None:
self._default_header = {"User-agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36"}
else:
self._default_header = default_header
def load_data(self,
urls: List[str],
num_levels: int = 0,
level_prefix: str = None,
headers: str = None) -> List[Document]:
logging.info(f"Número de URLs: {len(urls)}.")
if headers is None:
headers = self._default_header
documents = []
visited = {}
for url in urls:
q = [url]
depth = num_levels
for page in q:
if page not in visited: # evitar ciclos comprobando si ya hemos rastreado un enlace
logging.info(f"Rastreando {page}")
visited[page] = True # agregar entrada a visitados para evitar volver a rastrear páginas
response = requests.get(page, headers=headers).text
response = self._html_to_text_parser.html2text(response) # reducir HTML a texto
documents.append(Document(response))
if depth > 0:
# rastrear páginas enlazadas
ingest_urls = find_http_urls_in_parentheses(response, level_prefix)
logging.info(f"Encontradas {len(ingest_urls)} páginas para rastrear.")
q.extend(ingest_urls)
depth -= 1 # reducir el contador de profundidad para rastrear solo num_levels de profundidad en nuestro rastreo
else:
logging.info(f"Saltando {page} porque ya se ha rastreado")
logging.info(f"Número de documentos: {len(documents)}.")
return documents
url = "http://www.zappos.com/general-questions"
loader = EZWebLoader()
# rastrear el sitio con una profundidad de 1 nivel y un prefijo de "/c/" para la raíz del servicio al cliente
documents = loader.load_data([url]
num_levels=1, level_prefix="https://www.zappos.com/c/")
index = GPTVectorStoreIndex.from_documents(documents)En el código anterior, introducimos la capacidad de rastrear N niveles de profundidad, y damos un prefijo que nos permite limitar el rastreo solo a cosas que comienzan con un cierto patrón de URL. En nuestro ejemplo de Zappos, todas las páginas de servicio al cliente se originan en zappos.com/c, por lo que incluimos eso como un prefijo para limitar nuestros rastreos a un subconjunto más pequeño y relevante. El código muestra cómo podemos procesar hasta dos niveles de profundidad. La lógica Lambda de nuestro bot sigue siendo la misma porque nada ha cambiado excepto que el rastreador procesa más documentos.
Ahora tenemos todos los documentos indexados y podemos hacer una pregunta más detallada. En la siguiente captura de pantalla, nuestro bot proporciona la respuesta correcta a la pregunta “¿Tienen una política de igualación de precios?”

Ahora tenemos una respuesta completa a nuestra pregunta sobre la igualación de precios. En lugar de simplemente que nos digan “Sí, consulte nuestra política”, nos da los detalles del rastreo de segundo nivel.
Limpieza
Para evitar incurrir en gastos futuros, proceda a eliminar todos los recursos que se implementaron como parte de este ejercicio. Hemos proporcionado un script para cerrar el punto de conexión de Sagemaker de manera adecuada. Los detalles de uso se encuentran en el archivo README. Además, para eliminar todos los demás recursos, puede ejecutar cdk destroy en el mismo directorio que los otros comandos de cdk para desaprovisionar todos los recursos en su pila.
Conclusión
La capacidad de procesar un conjunto de preguntas frecuentes en un chatbot permite a sus clientes encontrar las respuestas a sus preguntas con consultas sencillas y en lenguaje natural. Al combinar el soporte incorporado en Amazon Lex para el manejo de respuestas alternativas con una solución RAG como LlamaIndex, podemos proporcionar un camino rápido para que nuestros clientes obtengan respuestas satisfactorias, seleccionadas y aprobadas para preguntas frecuentes. Al aplicar el rastreo de N niveles en nuestra solución, podemos permitir respuestas que posiblemente abarquen varios enlaces de preguntas frecuentes y proporcionar respuestas más detalladas a las consultas de nuestros clientes. Siguiendo estos pasos, puede incorporar sin problemas capacidades poderosas de preguntas y respuestas basadas en LLM y una ingestión eficiente de URL en su chatbot de Amazon Lex. Esto resulta en interacciones más precisas, completas y contextualmente conscientes con los usuarios.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Herramientas de IA principales para podcasting (2023)
- ChatGPT y Tesla Full-Self-Driving tienen el mismo problema
- Inmersión profunda en la visualización de barras de error
- Una guía completa para usar Pandas en Python
- 5 Estrategias para Mejorar la Ingeniería de la Pronta Respuesta
- GenAIOps Evolucionando el marco de MLOps
- Las dos caras de la alineación de la IA