Operaciones de Matrices y Vectores en Regresión Logística
'Operaciones en Regresión Logística'
Regresión Logística Vectorizada
Las matemáticas subyacentes detrás de cualquier algoritmo de Red Neuronal Artificial (RNA) pueden resultar abrumadoras de entender. Además, las operaciones matriciales y vectoriales utilizadas para representar las computaciones de propagación hacia adelante y retropropagación durante el entrenamiento por lotes del modelo pueden agregar a la sobrecarga de comprensión. Si bien las notaciones matriciales y vectoriales concisas tienen sentido, profundizar en esas notaciones hasta los detalles de funcionamiento sutiles de dichas operaciones matriciales aportaría más claridad. Me di cuenta de que la mejor manera de comprender esos detalles sutiles es considerar un modelo de red mínimo. No pude encontrar un algoritmo mejor que la Regresión Logística para explorar lo que sucede bajo el capó porque tiene todas las características de una RNA, como entradas multidimensionales, los pesos de la red, el sesgo, las operaciones de propagación hacia adelante, las activaciones que aplican una función no lineal, la función de pérdida y la retropropagación basada en gradientes. Mi intención con este blog es compartir mis notas y hallazgos sobre las operaciones matriciales y vectoriales que son fundamentales para el modelo de Regresión Logística.
Breve Sinopsis de la Regresión Logística
A pesar de su nombre, la Regresión Logística es un algoritmo de clasificación y no de regresión. Normalmente se utiliza para la clasificación binaria para predecir la probabilidad de que una instancia pertenezca a una de las dos clases, por ejemplo, predecir si un correo electrónico es spam o no. Como tal, en la Regresión Logística, la variable dependiente o variable objetivo se considera una variable categórica. Por ejemplo, un correo electrónico que es spam se representa como 1 y un correo que no es spam como 0. El objetivo principal del modelo de Regresión Logística es establecer una relación entre las variables de entrada (características) y la probabilidad de la variable objetivo. Por ejemplo, dadas las características de un correo electrónico como un conjunto de características de entrada, un modelo de Regresión Logística encontraría una relación entre dichas características y la probabilidad de que el correo electrónico sea spam. Si ‘Y’ representa la clase de salida, como un correo electrónico que es spam, ‘X’ representa las características de entrada, la probabilidad se puede designar como π = Pr( Y = 1 | X, βi), donde βi representa los parámetros de regresión logística que incluyen los pesos del modelo ‘wi’ y un parámetro de sesgo ‘b’. Efectivamente, una Regresión Logística predice la probabilidad de que Y = 1 dadas las características de entrada y los parámetros del modelo. Específicamente, la probabilidad π se modela como una función logística en forma de S llamada función Sigmoidal, dada por π = e^z/(1 + e^z) o equivalente a π = 1/(1 + e^-z), donde z = βi . X. La función sigmoidal permite obtener una curva suave limitada entre 0 y 1, lo que la hace adecuada para estimar probabilidades. Esencialmente, un modelo de Regresión Logística aplica la función sigmoidal a una combinación lineal de las características de entrada para predecir una probabilidad entre 0 y 1. Un enfoque común para determinar la clase de salida de una instancia es establecer un umbral en la probabilidad predicha. Por ejemplo, si la probabilidad predicha es mayor o igual a 0.5, la instancia se clasifica como perteneciente a la clase 1; de lo contrario, se clasifica como clase 0.
Un modelo de Regresión Logística se entrena ajustando el modelo a los datos de entrenamiento y luego minimizando una función de pérdida para ajustar los parámetros del modelo. Una función de pérdida estima la diferencia entre las probabilidades predichas y reales de la clase de salida. La función de pérdida más comúnmente utilizada en el entrenamiento de un modelo de Regresión Logística es la función de pérdida de Log Loss, también conocida como función de Entropía Cruzada Binaria. La fórmula para la función de pérdida de Log Loss es la siguiente:
L = — ( y * ln(p) + (1 — y) * ln(1 — p) )
- DataHour Reducción del 80% de las alucinaciones de ChatGPT
- Pic2Word Mapeo de imágenes a palabras para la recuperación de imágenes compuestas sin entrenamiento previo.
- La IA combate la plaga de los desechos espaciales
Donde:
- L representa la pérdida de Log.
- y es la etiqueta binaria de verdad (0 o 1).
- p es la probabilidad predicha de la clase de salida.
Un modelo de Regresión Logística ajusta sus parámetros minimizando la función de pérdida utilizando técnicas como el descenso de gradiente. Dado un lote de características de entrada y sus etiquetas de clase de verdad, el entrenamiento del modelo se lleva a cabo en varias iteraciones, llamadas épocas. En cada época, el modelo lleva a cabo operaciones de propagación hacia adelante para estimar las pérdidas y operaciones de retropropagación para minimizar la función de pérdida y ajustar los parámetros. Todas estas operaciones en una época emplean cálculos matriciales y vectoriales como se ilustra en las siguientes secciones.
Notaciones de Matrices y Vectores
Por favor, tenga en cuenta que usé scripts LaTeX para crear las ecuaciones matemáticas y las representaciones de matrices/vectores incrustadas como imágenes en este blog. Si alguien está interesado en los scripts LaTeX, no dude en contactarme; estaré encantado de compartirlos.
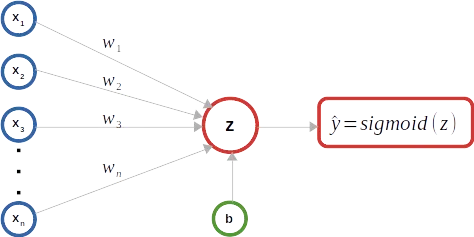
Como se muestra en el diagrama esquemático anterior, se utiliza un clasificador de Regresión Logística binaria como ejemplo para mantener las ilustraciones simples. Como se muestra a continuación, una matriz X representa el número ‘m’ de instancias de entrada. Cada instancia de entrada comprende un número ‘n’ de características y se representa como una columna, un vector de características de entrada, dentro de la matriz X, lo que la convierte en una matriz de tamaño (n x m). El superíndice (i) representa el número ordinal del vector de entrada en la matriz X. El subíndice ‘j’ representa el índice ordinal de la característica dentro de un vector de entrada. La matriz Y de tamaño (1 x m) captura las etiquetas de verdad correspondientes a cada vector de entrada en la matriz X. Los pesos del modelo se representan mediante un vector columna W de tamaño (n x 1) que comprende ‘n’ parámetros de peso correspondientes a cada característica en el vector de entrada. Si bien solo hay un parámetro de sesgo ‘b’, para ilustrar las operaciones de matriz/vector, se considera una matriz B de tamaño (1 x m) que comprende ‘m’ número del mismo parámetro de sesgo b.
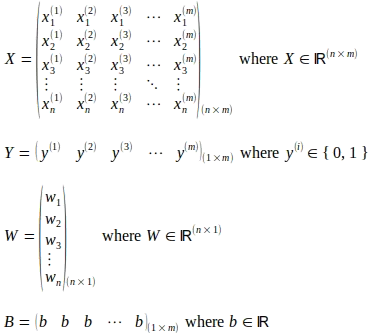
Propagación hacia adelante
El primer paso en la operación de propagación hacia adelante es calcular una combinación lineal de los parámetros del modelo y las características de entrada. La notación para esta operación de matriz se muestra a continuación, donde se evalúa una nueva matriz Z:
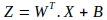
Observe el uso de la transposición de la matriz de pesos W. La operación anterior en la representación expandida de la matriz es la siguiente:
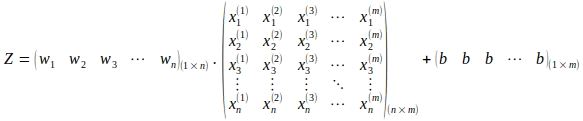
La operación de matriz anterior da como resultado el cálculo de la matriz Z de tamaño (1 x m) como se muestra a continuación:

El siguiente paso es obtener las activaciones aplicando la función sigmoide a las combinaciones lineales calculadas para cada entrada, como se muestra en la siguiente operación de matriz. Esto da como resultado una matriz de activación A de tamaño (1 x m).
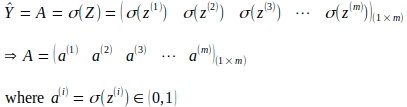
Propagación hacia atrás
La propagación hacia atrás o retropropagación es una técnica para calcular las contribuciones de cada parámetro al error general o pérdida causada por predicciones incorrectas al final de cada época. Las contribuciones individuales de pérdida se evalúan calculando los gradientes de la función de pérdida con respecto (w.r.t) a cada parámetro del modelo. Un gradiente o derivada de una función es la tasa de cambio o la pendiente de esa función con respecto a un parámetro considerando los otros parámetros como constantes. Cuando se evalúa para un valor o punto de parámetro específico, el signo del gradiente indica en qué dirección aumenta la función y la magnitud del gradiente indica la inclinación de la pendiente. La función de pérdida logarítmica, como se muestra a continuación, es una función convexa en forma de tazón con un único punto mínimo global. Como tal, en la mayoría de los casos, el gradiente de la función de pérdida logarítmica w.r.t a un parámetro apunta en dirección opuesta a los mínimos globales. Una vez que se evalúan los gradientes, cada valor de parámetro se actualiza utilizando el gradiente del parámetro, generalmente mediante una técnica llamada descenso de gradiente.
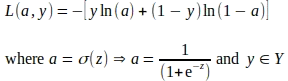
El gradiente para cada parámetro se calcula utilizando la regla de la cadena. La regla de la cadena permite el cálculo de derivadas de funciones que están compuestas por otras funciones. En el caso de la Regresión Logística, la función de pérdida logarítmica L es una función de la activación ‘a’ y la etiqueta de verdad ‘y’, mientras que ‘a’ en sí es una función sigmoide de ‘z’ y ‘z’ es una función lineal de los pesos ‘w’ y el sesgo ‘b’, lo que implica que la función de pérdida L es una función compuesta por otras funciones, como se muestra a continuación.
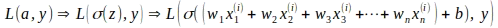
Usando la regla de la cadena de derivadas parciales, los gradientes de los parámetros de peso y sesgo se pueden calcular de la siguiente manera:
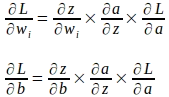
Derivación de los gradientes para una única instancia de entrada
Antes de revisar las representaciones matriciales y vectoriales que entran en juego como parte de la actualización de los parámetros de una sola vez, primero derivaremos los gradientes utilizando una única instancia de entrada para comprender mejor la base de tales representaciones.
Suponiendo que ‘a’ y ‘z’ representan los valores calculados para una única instancia de entrada con la etiqueta verdadera ‘y’, el gradiente de la función de pérdida con respecto a ‘a’ se puede derivar de la siguiente manera. Tenga en cuenta que este gradiente es la primera cantidad requerida para evaluar la regla de la cadena para derivar los gradientes de los parámetros más adelante.
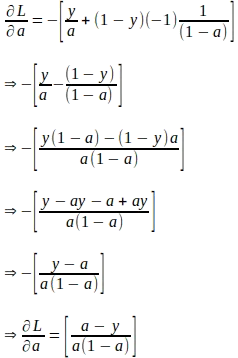
Dado el gradiente de la función de pérdida con respecto a ‘a’, el gradiente de la función de pérdida con respecto a ‘z’ se puede derivar utilizando la siguiente regla de la cadena:
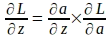
La regla de la cadena anterior implica que también se debe derivar el gradiente de ‘a’ con respecto a ‘z’. Tenga en cuenta que ‘a’ se calcula aplicando la función sigmoide a ‘z’. Por lo tanto, el gradiente de ‘a’ con respecto a ‘z’ se puede derivar utilizando la expresión de la función sigmoide de la siguiente manera:
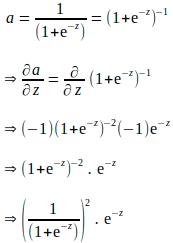
La derivación anterior se expresa en términos de ‘e’, y parece que se necesitan cálculos adicionales para evaluar el gradiente de ‘a’ con respecto a ‘z’. Sabemos que ‘a’ se calcula como parte de la propagación hacia adelante. Por lo tanto, para eliminar cualquier cálculo adicional, la derivada anterior se puede expresar completamente en términos de ‘a’ de la siguiente manera:
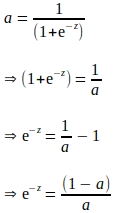
Insertando los términos anteriores expresados en ‘a’, el gradiente de ‘a’ con respecto a ‘z’ es el siguiente:
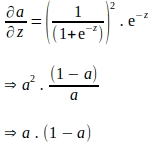
Ahora que tenemos el gradiente de la función de pérdida con respecto a ‘a’ y el gradiente de ‘a’ con respecto a ‘z’, podemos evaluar el gradiente de la función de pérdida con respecto a ‘z’ de la siguiente manera:
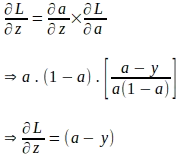
Hemos llegado lejos en la evaluación del gradiente de la función de pérdida con respecto a ‘z’. Aún necesitamos evaluar los gradientes de la función de pérdida con respecto a los parámetros del modelo. Sabemos que ‘z’ es una combinación lineal de los parámetros del modelo y las características de una instancia de entrada ‘x’ como se muestra a continuación:
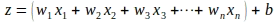
Usando la regla de la cadena, el gradiente de la función de pérdida con respecto al parámetro de peso ‘wi’ se evalúa de la siguiente manera:
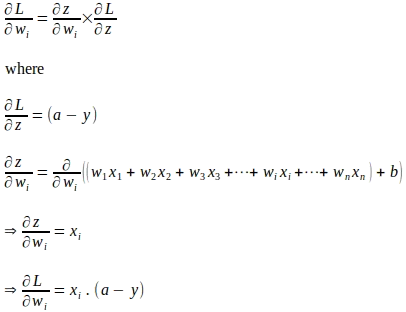
De manera similar, el gradiente de la función de pérdida con respecto a ‘b’ se evalúa de la siguiente manera:
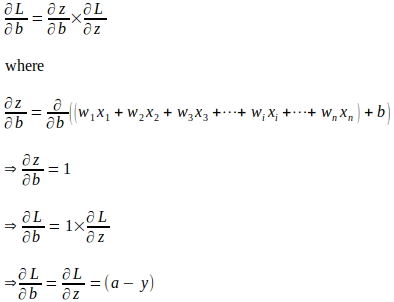
Representación de matrices y vectores de actualizaciones de parámetros utilizando gradientes
Ahora que entendemos las fórmulas de gradientes para los parámetros del modelo derivadas utilizando una sola instancia de entrada, podemos representar las fórmulas en forma de matrices y vectores teniendo en cuenta todo el lote de entrenamiento. Primero vectorizaremos los gradientes de la función de pérdida con respecto a ‘z’ dados por la siguiente expresión:
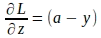
La forma vectorial de lo anterior para todas las ‘m’ instancias es:
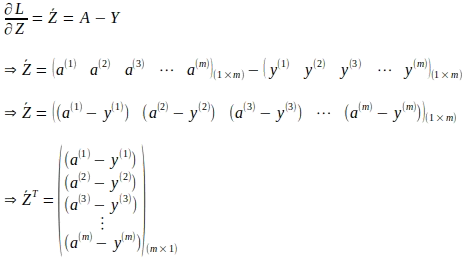
De manera similar, los gradientes de la función de pérdida con respecto a cada peso ‘wi’ se pueden vectorizar. El gradiente de la función de pérdida con respecto al peso ‘wi’ para una sola instancia se da por:
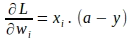
La forma vectorial de lo anterior para todos los pesos en todas las instancias de entrada ‘m’ se evalúa como la media de los ‘m’ gradientes de la siguiente manera:
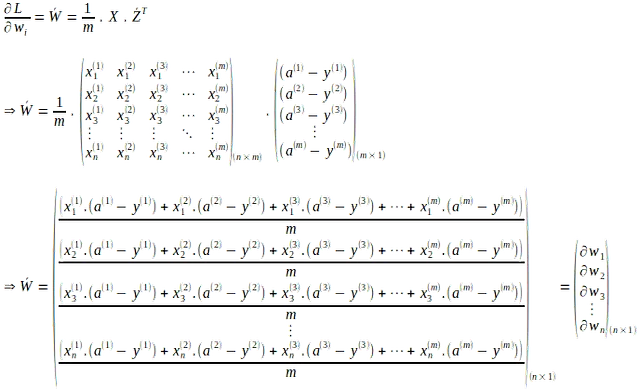
De manera similar, el gradiente resultante de la función de pérdida con respecto a ‘b’ en todas las instancias de entrada ‘m’ se calcula como la media de los gradientes de las instancias individuales de la siguiente manera:
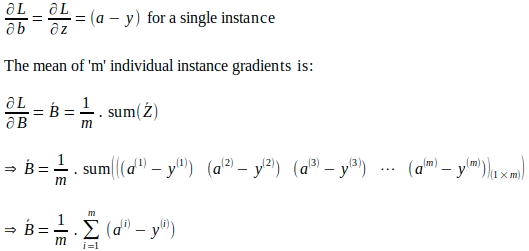
Dados el vector de gradientes de los pesos del modelo y el gradiente general para el sesgo, los parámetros del modelo se actualizan de la siguiente manera. Las actualizaciones de los parámetros que se muestran a continuación se basan en la técnica llamada descenso de gradientes donde se utiliza una tasa de aprendizaje. La tasa de aprendizaje es un hiperparámetro utilizado en técnicas de optimización como el descenso de gradientes para controlar el tamaño del paso de los ajustes realizados en cada época a los parámetros del modelo basados en los gradientes calculados. De manera efectiva, una tasa de aprendizaje actúa como un factor de escalamiento, influyendo en la velocidad y convergencia del algoritmo de optimización.

Conclusión
Como se puede observar a partir de las representaciones matriciales y vectoriales ilustradas en este blog, la Regresión Logística permite un modelo de red mínimo para comprender los detalles sutiles de estas operaciones matriciales y vectoriales. La mayoría de las bibliotecas de aprendizaje automático encapsulan estos detalles matemáticos, pero en su lugar exponen interfaces de programación bien definidas a un nivel superior, como la propagación hacia adelante o hacia atrás. Si bien no es necesario comprender todos estos detalles sutiles para desarrollar modelos utilizando dichas bibliotecas, estos detalles iluminan las intuiciones matemáticas detrás de estos algoritmos. Sin embargo, este entendimiento ciertamente ayudará a llevar adelante las intuiciones matemáticas subyacentes a otros modelos como las Redes Neuronales Artificiales (ANN), las Redes Neuronales Recurrentes (RNN), las Redes Neuronales Convolutivas (CNN) y las Redes Generativas Antagónicas (GAN).
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Fiber Óptica Pantalones Inteligentes Ofrecen una Forma de Bajo Costo para Monitorear Movimientos
- Cómo hacer gráficos, diagramas y diagramas con ChatGPT
- Dominando la Interpretabilidad del Modelo Un Análisis Integral de los Gráficos de Dependencia Parcial
- People Analytics es lo nuevo y grande, y aquí te explicamos por qué debes conocerlo.
- Esta Investigación de IA Explica los Rasgos de Personalidad Sintéticos en los Modelos de Lenguaje de Gran Escala (LLMs)
- Aprendiendo Transformers Code First Parte 1 – La Configuración
- El diablo está en los detalles Conviértete en un campeón de Power BI pensando fuera de lo convencional.






