Código de Destilación de Conocimiento y Pesos de SD-Small y SD-Tiny de código abierto
Open-source Knowledge Distillation Code and Weights for SD-Small and SD-Tiny

En tiempos recientes, la comunidad de IA ha presenciado un notable aumento en el desarrollo de modelos de lenguaje más grandes y con mejor rendimiento, como Falcon 40B, LLaMa-2 70B, Falcon 40B, MPT 30B, y en el dominio de la imagen con modelos como SD2.1 y SDXL. Estos avances sin duda han empujado los límites de lo que la IA puede lograr, permitiendo capacidades de generación de imágenes y comprensión del lenguaje altamente versátiles y de vanguardia. Sin embargo, mientras nos maravillamos con el poder y la complejidad de estos modelos, es esencial reconocer una creciente necesidad de hacer que los modelos de IA sean más pequeños, eficientes y accesibles, particularmente mediante su código abierto.
En Segmind, hemos estado trabajando en cómo hacer que los modelos generativos de IA sean más rápidos y económicos. El año pasado, hemos abierto el código de nuestra biblioteca acelerada SD-WebUI llamada voltaML, que es una biblioteca de aceleración de inferencia basada en AITemplate/TensorRT que ha logrado aumentar entre 4 y 6 veces la velocidad de inferencia. Para seguir avanzando hacia el objetivo de hacer que los modelos generativos sean más rápidos, más pequeños y más económicos, estamos abriendo el código y los pesos de nuestros modelos comprimidos SD; SD-Small y SD-Tiny. Los checkpoints pre-entrenados están disponibles en Huggingface 🤗
Destilación de Conocimiento

- Generación práctica de activos en 3D Una guía paso a paso
- Gigantesco Telescopio Adopta Robots de Mantenimiento Inteligentes
- 4 Herramientas de IA para trabajar con PDFs – Además de herramientas adicionales de bonificación
Nuestros nuevos modelos comprimidos han sido entrenados en técnicas de Destilación de Conocimiento (KD) y el trabajo se ha basado en gran medida en este paper. Los autores describen un método de destilación de conocimiento mediante eliminación de bloques, donde se eliminan algunas capas de UNet y se entrenan los pesos del modelo estudiante. Utilizando los métodos de KD descritos en el paper, pudimos entrenar dos modelos comprimidos utilizando la biblioteca 🧨 diffusers; Small y Tiny, que tienen un 35% y un 55% menos de parámetros, respectivamente, que el modelo base, al tiempo que logran una fidelidad de imagen comparable al modelo base. Hemos abierto el código de nuestra destilación en este repositorio y los checkpoints pre-entrenados en Huggingface 🤗.
La formación de la red neuronal mediante la destilación de conocimiento es similar a un maestro guiando a un estudiante paso a paso. Un modelo maestro grande se pre-entrena en una gran cantidad de datos y luego se entrena un modelo más pequeño en un conjunto de datos más pequeño, para imitar las salidas del modelo más grande junto con el entrenamiento clásico en el conjunto de datos.
En este tipo particular de destilación de conocimiento, el modelo estudiante se entrena para realizar la tarea normal de difusión de recuperar una imagen a partir de ruido puro, pero al mismo tiempo, el modelo se hace coincidir con la salida del modelo maestro más grande. La coincidencia de las salidas ocurre en cada bloque de los U-nets, por lo que la calidad del modelo se mantiene en su mayoría. Por lo tanto, utilizando la analogía anterior, podemos decir que durante este tipo de destilación, el estudiante no solo intentará aprender de las preguntas y respuestas, sino también de las respuestas del profesor, así como del método paso a paso para llegar a la respuesta. Tenemos 3 componentes en la función de pérdida para lograr esto, en primer lugar la pérdida tradicional entre los latentes de la imagen objetivo y los latentes de la imagen generada. En segundo lugar, la pérdida entre los latentes de la imagen generada por el modelo maestro y los latentes de la imagen generada por el modelo estudiante. Y por último, y el componente más importante, es la pérdida a nivel de características, que es la pérdida entre las salidas de cada uno de los bloques del modelo maestro y del modelo estudiante.
La combinación de todo esto conforma la formación mediante destilación de conocimiento. A continuación se muestra una arquitectura del UNet con bloques eliminados utilizado en la KD, como se describe en el paper.
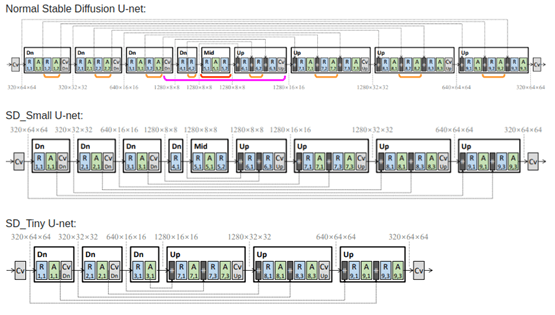
Imagen tomada del paper “Sobre la Compresión Arquitectónica de los Modelos de Difusión de Texto a Imagen” por Shinkook. et. al
Hemos tomado Realistic-Vision 4.0 como nuestro modelo maestro base y lo hemos entrenado en el conjunto de datos de Estética de Arte LAION con puntuaciones de imagen superiores a 7.5, debido a sus descripciones de imágenes de alta calidad. A diferencia del paper, hemos elegido entrenar los dos modelos con 1 millón de imágenes durante 100 mil pasos para el modo Small y 125 mil pasos para el modo Tiny, respectivamente. El código para el entrenamiento de destilación se puede encontrar aquí.
Uso del Modelo
El modelo se puede utilizar utilizando el DiffusionPipeline de 🧨 diffusers
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained("segmind/small-sd", torch_dtype=torch.float16)
prompt = "Retrato de una chica bonita"
negative_prompt = "(iris deformado, pupilas deformadas, semi-realista, cgi, 3d, renderizado, boceto, dibujo, anime:1.4), texto, primer plano, recortado, fuera de cuadro, peor calidad, baja calidad, artefactos de jpeg, feo, duplicado, mórbido, mutilado, dedos extra, manos mutadas, manos mal dibujadas, rostro mal dibujado, mutación, deformado, borroso, deshidratado, anatomía incorrecta, proporciones incorrectas, extremidades adicionales, rostro clonado, desfigurado, proporciones incorrectas, extremidades malformadas, brazos faltantes, piernas faltantes, brazos adicionales, piernas adicionales, dedos fusionados, demasiados dedos, cuello largo"
image = pipeline(prompt, negative_prompt = negative_prompt).images[0]
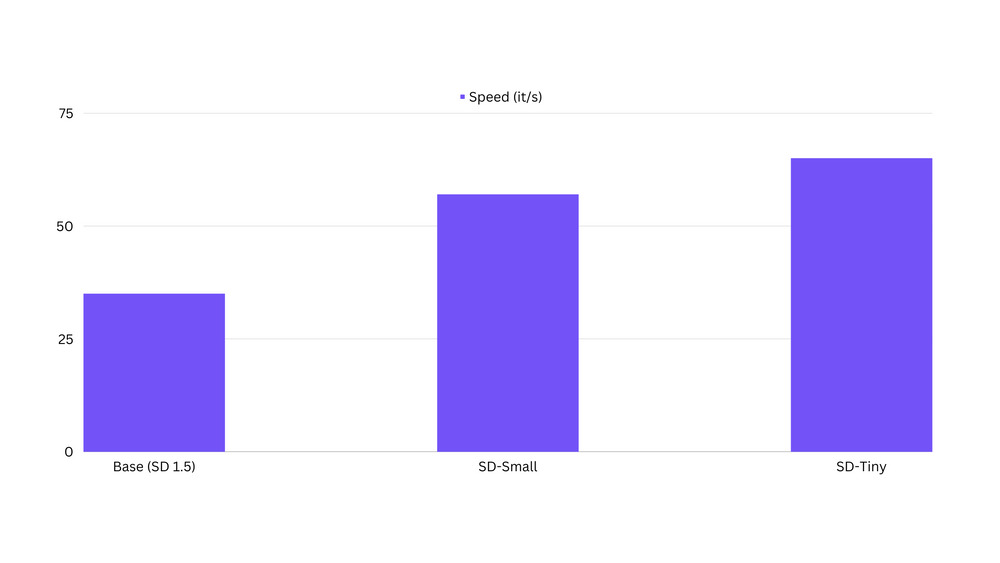
image.save("mi_imagen.png")Velocidad en términos de latencia de inferencia
Hemos observado que los modelos destilados son hasta un 100% más rápidos que los modelos base originales. El código de referencia se puede encontrar aquí.
Limitaciones potenciales
Los modelos destilados están en una fase temprana y las salidas pueden no ser de calidad de producción todavía. Estos modelos pueden no ser los mejores modelos generales. Se utilizan mejor como modelos afinados o entrenados en LoRA sobre conceptos/estilos específicos. Los modelos destilados aún no son muy buenos en cuanto a composibilidad o multiconceptos.
Afinando el modelo SD-tiny en un conjunto de datos de retratos
Hemos afinado nuestro modelo SD-tiny en imágenes de retratos generadas con el modelo Realistic Vision v4.0. A continuación se muestran los parámetros de afinamiento utilizados.
- Pasos: 131000
- Tasa de aprendizaje: 1e-4
- Tamaño de lote: 32
- Pasos de acumulación de gradiente: 4
- Resolución de imagen: 768
- Tamaño del conjunto de datos: 7k imágenes
- Precisión mixta: fp16
Hemos logrado producir una calidad de imagen cercana a las imágenes producidas por el modelo original, con casi un 40% menos de parámetros y los resultados de muestra a continuación hablan por sí mismos:

El código para afinar los modelos base se puede encontrar aquí.
Entrenamiento de LoRA
Una de las ventajas del entrenamiento de LoRA en un modelo destilado es un entrenamiento más rápido. A continuación se muestran algunas de las imágenes de la primera LoRA que entrenamos en el modelo destilado sobre algunos conceptos abstractos. El código para el entrenamiento de LoRA se puede encontrar aquí.

Conclusión
Invitamos a la comunidad de código abierto a ayudarnos a mejorar y lograr una adopción más amplia de estos modelos destilados de SD. Los usuarios pueden unirse a nuestro servidor de Discord, donde anunciaremos las últimas actualizaciones de estos modelos, lanzaremos más puntos de control y algunas nuevas y emocionantes LoRAs. Y si te gusta nuestro trabajo, por favor danos una estrella en nuestro Github.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Identificación Lingüística con Python
- Análisis de acordes de jazz con Transformers
- Principales artículos de Visión por Computadora durante la semana del 24/7 al 31/7
- 10 Mejores Herramientas de Intercambio de Caras de IA (Agosto 2023)
- API de Pronóstico Un Ejemplo con Django y Google Trends
- ChatGPT y la ingeniería avanzada de instrucciones impulsando la evolución de la IA
- Detecta cualquier cosa que desees con UniDetector






