¿Qué hay de nuevo en los Difusores? 🎨
'Novedades en Difusores 🎨'
Hace un mes y medio lanzamos diffusers, una biblioteca que proporciona un conjunto de herramientas modulares para modelos de difusión en diferentes modalidades. Un par de semanas después, lanzamos el soporte para Diffusion Estable, un modelo de alta calidad de texto a imagen, con una demostración gratuita para que cualquiera pueda probarlo. Además de quemar muchas GPUs, en las últimas tres semanas, el equipo ha decidido agregar una o dos nuevas características a la biblioteca que esperamos que la comunidad disfrute. ¡Esta publicación de blog ofrece una descripción general de las nuevas características en la versión 0.3 de diffusers! Recuerda dar una ⭐ al repositorio de GitHub.
- Pipelines de imagen a imagen
- Inversión textual
- Reparación de imágenes
- Optimizaciones para GPUs más pequeñas
- Ejecución en Mac
- Exportador ONNX
- Nuevos documentos
- Comunidad
- Generar videos con espacio latente SD
- Explicabilidad del modelo
- Diffusion Estable en japonés
- Modelo afinado de alta calidad
- Control de atención cruzada con Diffusion Estable
- Seeds reutilizables
Pipeline de imagen a imagen
Una de las características más solicitadas fue tener generación de imagen a imagen. ¡Este pipeline te permite ingresar una imagen y una descripción y generará una imagen basada en eso!
Echemos un vistazo a algo de código basado en el cuaderno oficial de Colab.
from diffusers import StableDiffusionImg2ImgPipeline
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=True
)
# Descargar una imagen inicial
# ...
init_image = preprocess(init_img)
prompt = "Un paisaje de fantasía, popular en artstation"
images = pipe(prompt=prompt, init_image=init_image, strength=0.75, guidance_scale=7.5, generator=generator)["sample"]¿No tienes tiempo para el código? No te preocupes, también creamos una demostración en Space donde puedes probarlo directamente.
- Cómo entrenar un Modelo de Lenguaje con Megatron-LM
- SetFit Aprendizaje Eficiente de Pocos Ejemplos Sin Indicaciones
- Cómo 🤗 Accelerate ejecuta modelos muy grandes gracias a PyTorch
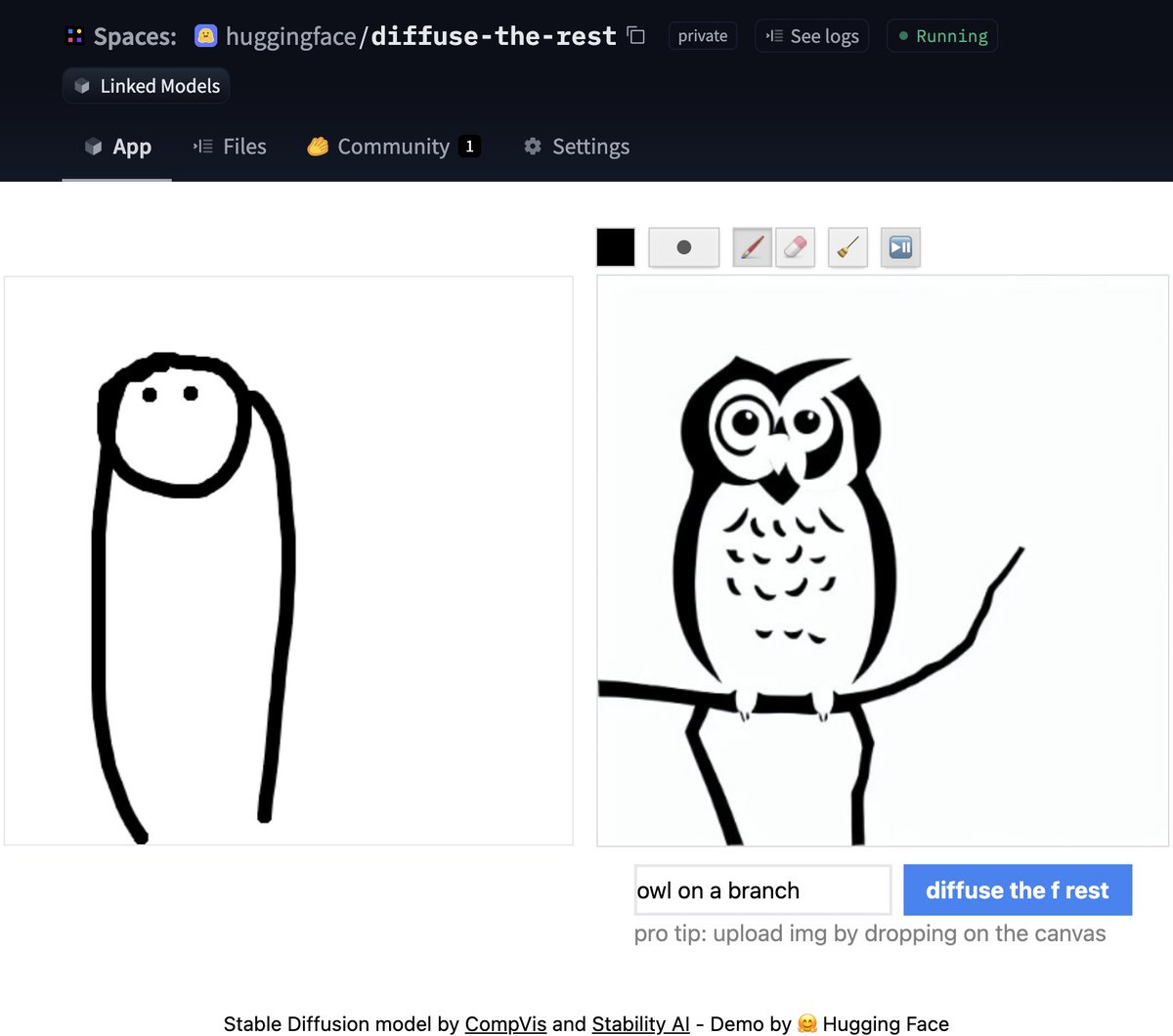
Inversión textual
La inversión textual te permite personalizar un modelo de Diffusion Estable en tus propias imágenes con solo 3-5 ejemplos. ¡Con esta herramienta, puedes entrenar un modelo en un concepto y luego compartir el concepto con el resto de la comunidad!
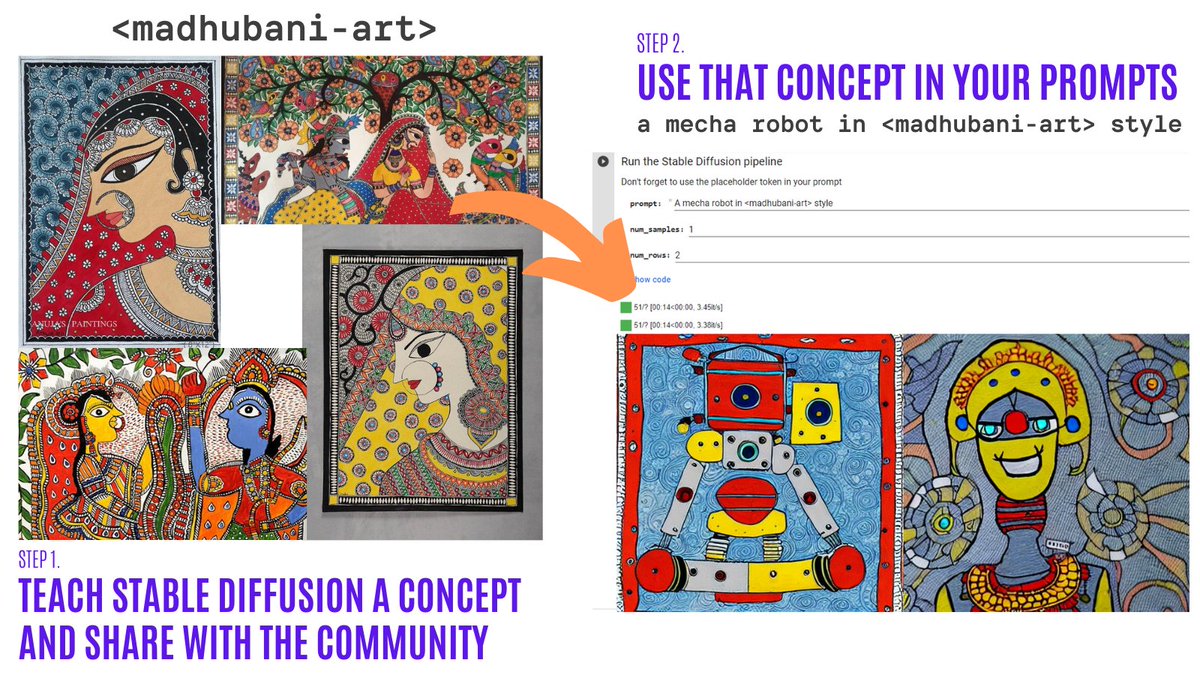
¡En solo un par de días, la comunidad compartió más de 200 conceptos! ¡Échales un vistazo!
- Organización con los conceptos.
- Colab del Navegador: Explora visualmente y utiliza más de 150 conceptos creados por la comunidad.
- Colab de Entrenamiento: Enseña a Diffusion Estable un nuevo concepto y compártelo con el resto de la comunidad.
- Colab de Inferencia: Ejecuta Diffusion Estable con los conceptos aprendidos.
Pipeline experimental de reparación de imágenes
La reparación de imágenes permite proporcionar una imagen, seleccionar un área en la imagen (o proporcionar una máscara) y utilizar Diffusion Estable para reemplazar la máscara. Aquí tienes un ejemplo:

Puedes probar un cuaderno de Colab mínimo o revisar el código a continuación. ¡Pronto habrá una demostración!
from diffusers import StableDiffusionInpaintPipeline
pipe = StableDiffusionInpaintPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=True
).to(device)
images = pipe(
prompt=["un gato sentado en un banco"] * 3,
init_image=init_image,
mask_image=mask_image,
strength=0.75,
guidance_scale=7.5,
generator=None
).imagesTen en cuenta que esto es experimental, por lo que hay margen de mejora.
Optimizaciones para GPUs más pequeñas
Después de algunas mejoras, los modelos de difusión pueden ocupar mucho menos VRAM. 🔥 Por ejemplo, ¡Stable Diffusion solo ocupa 3.2GB! Esto produce los mismos resultados exactos a costa de una velocidad 10% menor. Aquí te mostramos cómo usar estas optimizaciones
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=True
)
pipe = pipe.to("cuda")
pipe.enable_attention_slicing()¡Esto es súper emocionante ya que reducirá aún más la barrera para usar estos modelos!
Diffusers en Mac OS
🍎 ¡Así es! ¡Otra característica muy solicitada acaba de ser lanzada! Lee las instrucciones completas en la documentación oficial (incluyendo comparaciones de rendimiento, especificaciones y más).
Usando el dispositivo PyTorch mps, las personas con hardware M1/M2 pueden ejecutar inferencias con Stable Diffusion. 🤯 Esto requiere una configuración mínima para los usuarios, ¡pruébalo!
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=True)
pipe = pipe.to("mps")
prompt = "una foto de un astronauta montando un caballo en Marte"
image = pipe(prompt).images[0]Exportador y canalización experimental de ONNX
La nueva canalización experimental permite a los usuarios ejecutar Stable Diffusion en cualquier hardware que admita ONNX. Aquí tienes un ejemplo de cómo usarlo (ten en cuenta que se está utilizando la revisión onnx)
from diffusers import StableDiffusionOnnxPipeline
pipe = StableDiffusionOnnxPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="onnx",
provider="CPUExecutionProvider",
use_auth_token=True,
)
prompt = "una foto de un astronauta montando un caballo en Marte"
image = pipe(prompt).images[0]Alternativamente, también puedes convertir directamente tus puntos de control de SD a ONNX con el script de exportación.
python scripts/convert_stable_diffusion_checkpoint_to_onnx.py --model_path="CompVis/stable-diffusion-v1-4" --output_path="./stable_diffusion_onnx"Nueva documentación
Todas las características anteriores son muy geniales. Como mantenedores de bibliotecas de código abierto, sabemos la importancia de una documentación de alta calidad para facilitar al máximo que cualquier persona pruebe la biblioteca.
💅 Por eso, hicimos un sprint de Documentación y estamos muy emocionados de hacer una primera versión de nuestra documentación. Esta es una primera versión, por lo que planeamos agregar muchas cosas más (¡y siempre se agradecen las contribuciones!).
Algunos aspectos destacados de la documentación:
- Técnicas de optimización
- Descripción general del entrenamiento
- Una guía de contribución
- Documentación de API detallada para programadores
- Documentación de API detallada para canalizaciones
Comunidad
Y mientras hacíamos todo lo anterior, ¡la comunidad no se quedó quieta! Estos son algunos aspectos destacados (aunque no exhaustivos) de lo que se ha hecho hasta ahora
Videos de Stable Diffusion
Crea 🔥 videos con Stable Diffusion explorando el espacio latente y transformando entre consignas de texto. Puedes:
- Visualizar diferentes versiones de la misma consigna
- Transformar entre diferentes consignas
La herramienta Stable Diffusion Videos se puede instalar con pip, viene con un notebook de Colab y un notebook de Gradio, ¡y es muy fácil de usar!
Este es un ejemplo:
from stable_diffusion_videos import walk
video_path = walk(['un gato', 'un perro'], [42, 1337], num_steps=3, make_video=True)Diffusers Interpret
Diffusers Interpret es una herramienta de explicabilidad construida sobre diffusers. Tiene características geniales como:
- Ver todas las imágenes en el proceso de difusión
- Analizar cómo cada token en la consigna influye en la generación
- Analizar dentro de cajas delimitadoras especificadas si deseas comprender una parte de la imagen
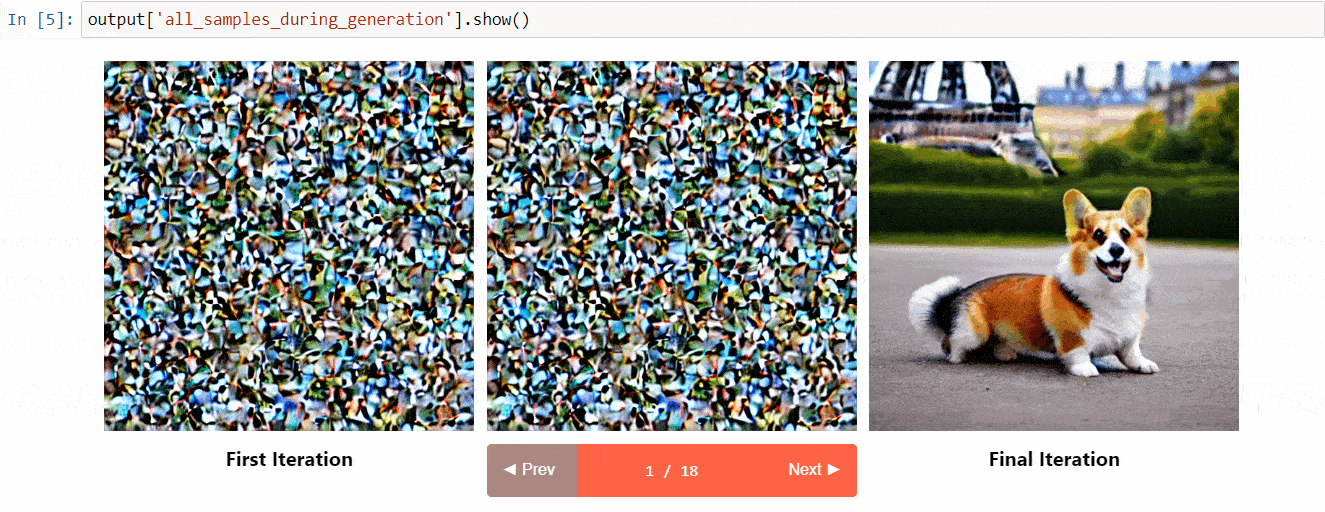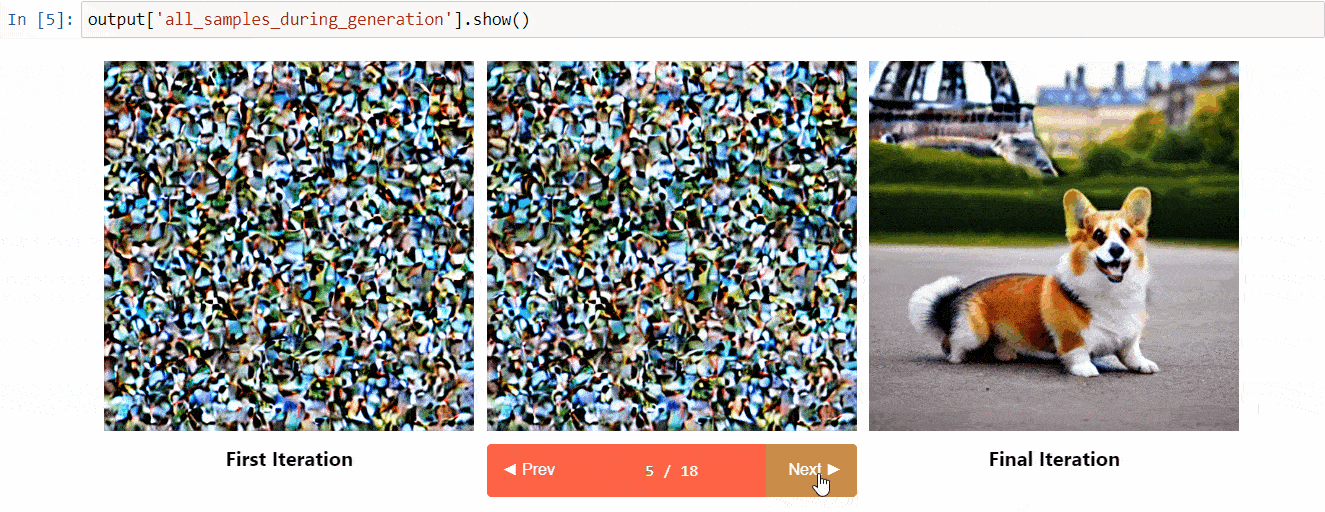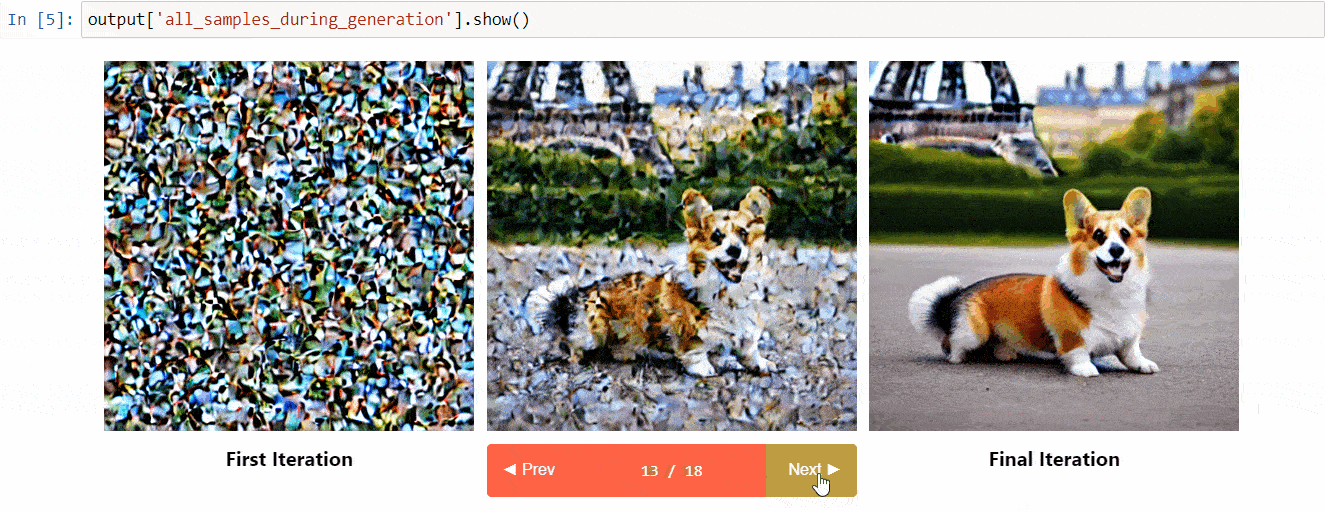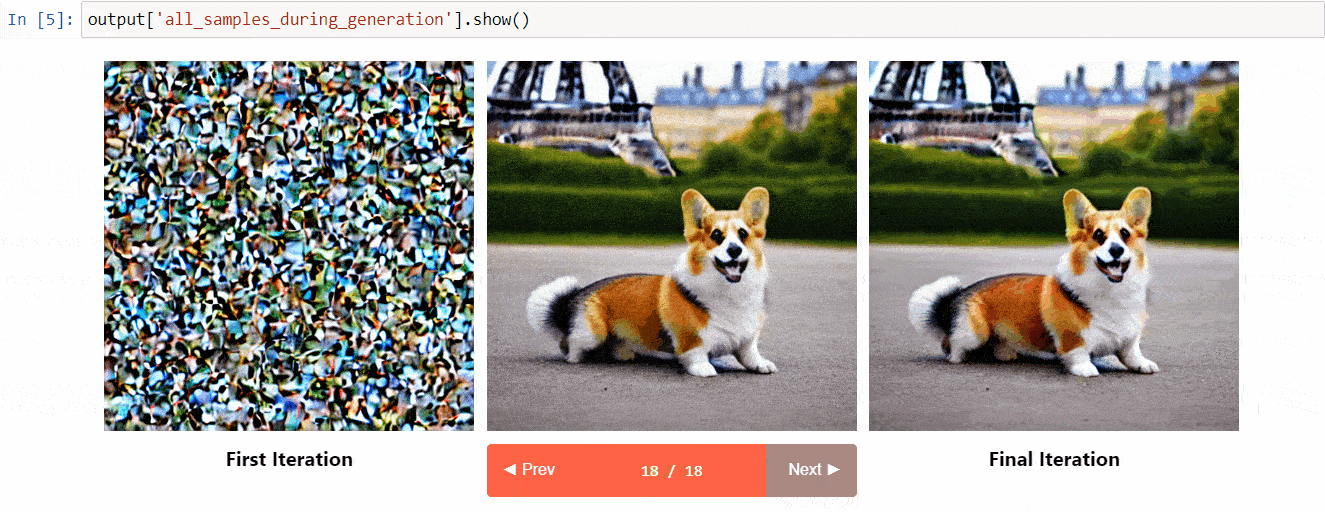 (Imagen del repositorio de herramientas)
(Imagen del repositorio de herramientas)
# pasar la tubería al explicador
explainer = StableDiffusionPipelineExplainer(pipe)
# generar una imagen con `explainer`
prompt = "Corgi con la Torre Eiffel"
output = explainer(
prompt,
num_inference_steps=15
)
output.normalized_token_attributions # (token, porcentaje de atribución)
#[('corgi', 40),
# ('con', 5),
# ('la', 5),
# ('torre', 25),
# ('eiffel', 25)]Difusión Estable en Japonés
¡El nombre lo dice todo! El objetivo de JSD era entrenar un modelo que también capturara información sobre la cultura, identidad y expresiones únicas. Fue entrenado con 100 millones de imágenes con subtítulos en japonés. Puedes leer más sobre cómo se entrenó el modelo en la tarjeta del modelo
Difusión Waifu
Waifu Diffusion es un modelo SD afinado para la generación de imágenes de anime de alta calidad.

(Imagen del repositorio de herramientas)
Control de Atención Cruzada
El Control de Atención Cruzada permite un control preciso de las indicaciones mediante la modificación de los mapas de atención de los modelos de difusión. Algunas cosas interesantes que puedes hacer:
- Reemplazar un objetivo en la indicación (por ejemplo, reemplazar gato por perro)
- Reducir o aumentar la importancia de las palabras en la indicación (por ejemplo, si quieres que se preste menos atención a “rocas”)
- Inyectar estilos fácilmente
¡Y mucho más! Echa un vistazo al repositorio.
Semillas Reutilizables
Una de las demostraciones más impresionantes de Stable Diffusion fue la reutilización de semillas para ajustar imágenes. La idea es usar la semilla de una imagen de interés para generar una nueva imagen, con una indicación diferente. ¡Esto produce resultados geniales! Echa un vistazo al Colab
¡Gracias por leer!
¡Espero que disfrutes leyendo esto! Recuerda dar una Estrella en nuestro Repositorio de GitHub y unirte al Servidor de Discord de Hugging Face, donde tenemos una categoría de canales exclusivamente para modelos de Difusión. ¡Allí se comparten las últimas noticias de la biblioteca!
No dudes en abrir problemas con solicitudes de funciones e informes de errores. Todo lo que se ha logrado no podría haberse hecho sin una comunidad tan increíble.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Clasificación de imágenes con AutoTrain
- Difusión estable en japonés
- Presentamos DOI el Identificador de Objeto Digital para Conjuntos de Datos y Modelos
- Historia de optimización Inferencia de Bloom
- 🧨 ¡Difusión estable en JAX / Flax!
- MTEB Referente de Evaluación de Incrustación de Texto Masivo
- De PyTorch DDP a Accelerate Trainer, dominio del entrenamiento distribuido con facilidad.





