¿Necesitas compresión?
¿Necesitas compresión?
Una implementación más eficiente de clasificación de temas basada en compresión
El recientemente publicado artículo titulado “Clasificación de Textos con Recursos Limitados: Un Método de Clasificación Sin Parámetros con Compresores [1]” ha recibido bastante atención pública en los últimos días. Su hallazgo clave es que, en algunos casos, pueden superar a grandes modelos de lenguaje como BERT utilizando la simple idea de que dos documentos de texto son más similares si pueden comprimirse a un tamaño de archivo más pequeño (aunque hay cierta controversia sobre la validez de sus resultados, ver esta publicación de blog y esta discusión que incluye la respuesta del autor).
La idea principal detrás de su enfoque es que la “distancia de información” entre dos documentos, como se define por Bennet et. al [2], es una buena métrica de distancia para utilizar durante la clasificación de textos. Dado que la distancia de información en sí misma no es computable, la aproximan utilizando la Distancia de Compresión Normalizada (NCD) [3], que estima la distancia de información utilizando compresores de datos “en la vida real” como gzip. NCD tiene la propiedad de que los compresores mejores (es decir, los compresores con una mejor relación de compresión) permitirán una mejor estimación de la verdadera distancia de información.
Parece natural entonces esperar que un mejor compresor logre un rendimiento superior en la clasificación. Pero no pueden validar esto experimentalmente; el mejor compresor considerado en el artículo, bz2, tiene un rendimiento inferior en términos de precisión que gzip. Lo explican de la siguiente manera: “[…] el algoritmo de Burrows-Wheeler utilizado por bz2 descarta la información del orden de los caracteres al permutar los caracteres durante la compresión” [1, p.6817]. Esto implica que la compresión por sí sola no explica sus hallazgos, sino que también tiene algo que ver con el orden de los caracteres.
Esto me hizo preguntarme: ¿Cuánto de sus resultados se deben a la compresión y cuánto se debe a la comparación de cadenas entre dos documentos?
- Cómo automatizar la calidad del código con los ganchos pre-commit de Python
- Final DXA-nación
- Conoce a Prismer Un modelo de visión-lenguaje de código abierto con un conjunto de expertos.
Para investigar esta pregunta, comparo sus resultados con dos alternativas: (1) un compresor simple que se basa únicamente en reemplazar cadenas recurrentes, y (2) un algoritmo que hace coincidir explícitamente subcadenas entre un documento de consulta y todos los documentos pertenecientes a algún tema.
Un primer estudio de ablación: ¿Hará el trabajo LZ4? El algoritmo de compresión gzip se basa en DEFLATE, que a su vez utiliza LZ77 y la codificación Huffman para comprimir los datos. Veamos estos dos algoritmos con más detalle y pensemos en lo que implican cuando se aplican a nuestro caso de uso.
Durante la compresión, LZ77 utiliza una ventana deslizante sobre los datos previamente vistos. Si se repite una cadena de caracteres, se almacena una referencia a la primera aparición de la cadena de caracteres, en lugar de la cadena misma. Por lo tanto, si tomamos la longitud de dos documentos concatenados como una métrica de distancia, los documentos estarán más cerca si tienen más subcadenas superpuestas dentro del tamaño de la ventana deslizante (normalmente 32KB).
La codificación Huffman comprime aún más el texto resultante: en lugar de usar 8 bits para cada carácter, representa aquellas letras que ocurren con frecuencia con menos bits y las letras que ocurren raramente con más bits. Si aplicamos la codificación Huffman a los documentos concatenados, dos documentos serían más pequeños después de la compresión si utilizan los caracteres con frecuencia similar.
Se esperaría que las subcadenas coincidentes sean mucho más importantes para la clasificación de temas que las frecuencias de caracteres similares. Por lo tanto, realizo un estudio de ablación examinando el rendimiento al utilizar el algoritmo LZ4 [4] para la compresión (básicamente LZ77 pero con una implementación rápida disponible en Python). Dado que LZ4 tiene una relación de compresión mucho menor que gzip, su explicación sugeriría que el rendimiento de LZ4 es peor que el de gzip. Sin embargo, si lo principal que está sucediendo es la coincidencia de subcadenas, LZ4 funcionará tan bien como gzip.
Un algoritmo más explícito Para ir aún más lejos, implemento un algoritmo simple que hace coincidir explícitamente las subcadenas: asigna documentos al tema con las subcadenas más similares (siendo las subcadenas aquí n-gramas a nivel de caracteres). Funciona de la siguiente manera:
Codificación de texto:1. Extraer todos los n-gramas de caracteres dentro del texto con 5 ≤ n ≤ 50.2. Para los n-gramas extraídos, calcular un código hash de 8 dígitos usando `hash(n_gram) % int(10e8)` en Python (ya que quiero controlar cuántas cosas diferentes llevar un registro).3. Llevar un registro de esto en conjuntos (perdiendo así la información sobre cuántas veces ocurre un código dado).
Entrenamiento: 1. Calcular el conjunto de códigos hash para cada texto de un tema dado. 2. Tomar la unión de conjuntos para obtener un conjunto de códigos hash que ocurran en el tema.
Inferencia: 1. Para algún texto de consulta, calcular el conjunto de sus n-gramas hash. 2. Para cada tema encontrado durante el entrenamiento, calcular el tamaño de la intersección entre los conjuntos de temas y el conjunto de consulta. 3. Asignar el texto de consulta al tema con la mayor intersección.
Experimento y Resultados Comparo los resultados de gzip, lz4 y el algoritmo de n-gramas hash en la configuración de 100 iteraciones con 5 ejecuciones, como se describe en su artículo. Para los tres métodos, me adhiero a su configuración experimental para reproducir sus resultados reportados (una vez más, lo que puede resultar en medidas de precisión potencialmente infladas). El código se puede encontrar en github.
Puede ver el rendimiento en tres conjuntos de datos de torchtext (AG_NEWS [5], DBpedia [6] y YahooAnswers [5]) en la siguiente tabla:
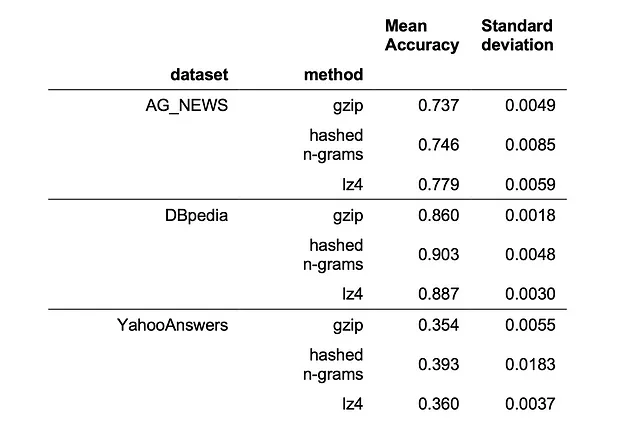
Vemos que lz4 y los n-gramas hash superan a gzip en los tres conjuntos de datos considerados, siendo el algoritmo de n-gramas hash el mejor en 2 de los 3 conjuntos de datos. Pero aún no compite con BERT, que tiene un rendimiento de 0.82 en AG_NEWS y cerca de 1 en DBpedia según su artículo en la configuración de 100 iteraciones.
Estos resultados tienen importantes implicaciones prácticas: en nuestro experimento, el algoritmo basado en lz4 se ejecuta aproximadamente 10 veces más rápido que el algoritmo basado en gzip. Y aún más importante, el algoritmo de n-gramas hash mejora incluso la complejidad computacional en el momento de la inferencia: en lugar de tener que comparar un documento de consulta con cada otro documento en el corpus de texto, solo tiene que hacer una comparación con cada conjunto de temas.
¿Qué aprendemos de esto? Mis resultados sugieren que la fuerza impulsora detrás del impresionante rendimiento reportado de gzip se puede atribuir al hecho de que su método compara implícitamente n-gramas a nivel de caracteres entre documentos. Este hallazgo permite el uso de compresores más rápidos como lz4 sin ninguna pérdida de rendimiento. Además, incluso se puede reescribir su algoritmo para tener una complejidad constante respecto al tamaño del conjunto de datos en el momento de la inferencia, acercando su método un paso más hacia su uso práctico en conjuntos de datos grandes. Si desea utilizarlo en la práctica, he comenzado una implementación siguiendo la API scikit-learn de mi algoritmo propuesto aquí.
La única pregunta que queda es, ¿por qué esto supera al enfoque TF-IDF que también compara palabras entre documentos?
Tal vez considerar n-gramas a nivel de caracteres hace un mejor trabajo para algunas tareas que dividir el texto en palabras individuales. Pero probablemente, lo que es más importante, el método aquí otorga el mismo peso a todos los n-gramas, independientemente de su frecuencia de aparición. Esto significa que se le da mucha importancia a la llamada información de “cola larga” (léase: rara), que aparentemente es relevante para algunas tareas de texto como la detección de temas. Tenga en cuenta que las redes de transformadores no hacen un buen trabajo modelando esta información de “cola larga” (para evidencia, consulte por ejemplo [5]), por lo que estos enfoques muy simples son una referencia muy interesante para medir su modelo de millones de parámetros.
Referencias [1] Z. Jiang, M. Yang, M. Tsirlin, R. Tang, Y. Dai, J. Lin. “Low-Resource” Text Classification: A Parameter-Free Classification Method with Compressors (2023), ACL 2023 [2] C. H. Bennett, P. Gács, M. Li, P. MB Vitányi, and W. H. Zurek, Information distance (1998), IEEE Transactions on information theory [3] M. Li, X. Chen, X. Li, B. Ma, and P. Vitányi, The similarity metric (2004), IEEE transactions on Information Theory [4] N. Kandpal, H. Deng, A. Roberts, E. Wallace, C. Raffel, Large Language Models Struggle to Learn Long-Tail Knowledge (2022), arxiv.org/abs/2211.08411
Gracias a Joel Niklaus y Marcel Gygli por nuestras discusiones y sus comentarios.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Una nueva investigación de IA de China combina métodos de aprendizaje automático con preguntas para revelar nuevas dimensiones en las conexiones entre las relaciones supervisor-estudiante
- Pensar, rápido y lento + IA
- Construyendo Funciones de Activación para Redes Profundas
- ¡La Biblioteca de Python de OpenAI y 5 cosas destacadas que ChatGPT puede hacer con ejemplos prácticos en Python!
- EU AI Act ¿Un paso prometedor o una apuesta arriesgada para el futuro de la IA?
- Por qué su próximo director financiero debería ser un científico de datos impulsando decisiones empresariales con ciencia de datos y análisis
- Desplegando un modelo TFLite en GCP Serverless






