Hacia modelos de lenguaje grandes encriptados con FHE
Modelos de lenguaje grandes encriptados con FHE
Los Modelos de Lenguaje Grandes (LLM) han demostrado recientemente ser herramientas confiables para mejorar la productividad en muchas áreas como programación, creación de contenido, análisis de texto, búsqueda en la web y aprendizaje a distancia.
El Impacto de los Modelos de Lenguaje Grandes en la Privacidad de los Usuarios
A pesar del atractivo de los LLM, persisten preocupaciones sobre la privacidad en relación a las consultas de los usuarios que son procesadas por estos modelos. Por un lado, aprovechar el poder de los LLM es deseable, pero por otro lado, existe el riesgo de filtrar información sensible al proveedor de servicios de LLM. En algunas áreas, como la salud, las finanzas o el derecho, este riesgo de privacidad es un obstáculo insalvable.
Una posible solución a este problema es la implementación en las instalaciones del cliente, donde el propietario del LLM implementaría su modelo en la máquina del cliente. Sin embargo, esta no es una solución óptima, ya que construir un LLM puede costar millones de dólares (4.6 millones de dólares para GPT3) y la implementación en las instalaciones corre el riesgo de filtrar la propiedad intelectual (PI) del modelo.
Zama cree que se puede obtener lo mejor de ambos mundos: nuestra ambición es proteger tanto la privacidad del usuario como la PI del modelo. En este blog, verás cómo aprovechar la biblioteca Hugging Face transformers y hacer que partes de estos modelos se ejecuten en datos encriptados. El código completo se puede encontrar en este ejemplo de caso de uso.
- Usando los valores SHAP para la interpretación del modelo en Aprendizaje Automático
- AIIMS Delhi comienza a investigar la robótica, la inteligencia artificial y los drones para la atención médica
- AWS y Accel lanzan ML Elevate 2023 para potenciar el ecosistema de startups de IA en India
La Encriptación Totalmente Homomórfica (FHE) Puede Resolver los Desafíos de Privacidad de los LLM
La solución de Zama a los desafíos de implementación de LLM es utilizar la Encriptación Totalmente Homomórfica (FHE), que permite la ejecución de funciones en datos encriptados. Es posible lograr el objetivo de proteger la PI del propietario del modelo mientras se mantiene la privacidad de los datos del usuario. Esta demostración muestra que un modelo LLM implementado en FHE mantiene la calidad de las predicciones del modelo original. Para hacer esto, es necesario adaptar la implementación de GPT2 de la biblioteca Hugging Face transformers, reorganizando secciones de la inferencia usando Concrete-Python, que permite la conversión de funciones de Python en sus equivalentes en FHE.
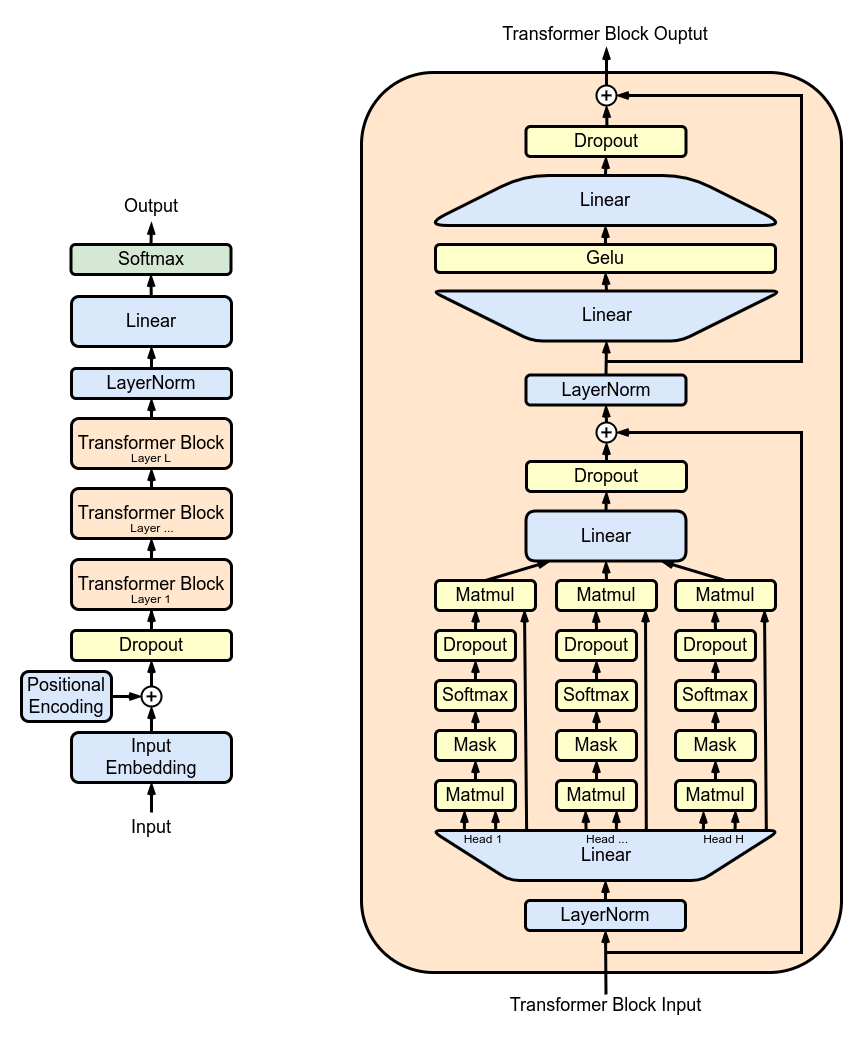
La Figura 1 muestra la arquitectura de GPT2, que tiene una estructura repetitiva: una serie de capas de atención de múltiples cabezas (MHA) aplicadas sucesivamente. Cada capa MHA proyecta las entradas utilizando los pesos del modelo, calcula el mecanismo de atención y vuelve a proyectar la salida de la atención en un nuevo tensor.
En TFHE, los pesos y las activaciones del modelo se representan con enteros. Las funciones no lineales deben implementarse con una operación de Arranque Programable (PBS, por sus siglas en inglés). PBS implementa una operación de búsqueda en tabla (TLU, por sus siglas en inglés) en datos encriptados mientras actualiza los textos cifrados para permitir un cálculo arbitrario. Por otro lado, el tiempo de cálculo de PBS domina el de las operaciones lineales. Aprovechando estos dos tipos de operaciones, se puede expresar cualquier subparte o incluso la computación completa de LLM en FHE.
Implementación de una Capa LLM con FHE
A continuación, verás cómo encriptar una sola cabeza de atención de la estructura de atención de múltiples cabezas (MHA). También puedes encontrar un ejemplo para el bloque MHA completo en este ejemplo de caso de uso.

La Figura 2 muestra una vista general simplificada de la implementación subyacente. Un cliente inicia la inferencia localmente hasta la primera capa que se ha eliminado del modelo compartido. El usuario encripta las operaciones intermedias y las envía al servidor. El servidor aplica parte del mecanismo de atención y luego devuelve los resultados al cliente, quien puede descifrarlos y continuar la inferencia local.
Cuantización
Primero, para realizar la inferencia del modelo en valores encriptados, los pesos y las activaciones del modelo deben ser cuantizados y convertidos a enteros. Lo ideal es utilizar la cuantización después del entrenamiento, que no requiere volver a entrenar el modelo. El proceso consiste en implementar un mecanismo de atención compatible con FHE, utilizar enteros y PBS, y luego examinar el impacto en la precisión del LLM.
Para evaluar el impacto de la cuantización, ejecuta el modelo completo de GPT2 con una sola Cabeza LLM que opera sobre datos encriptados. Luego, evalúa la precisión obtenida al variar el número de bits de cuantización tanto para los pesos como para las activaciones.
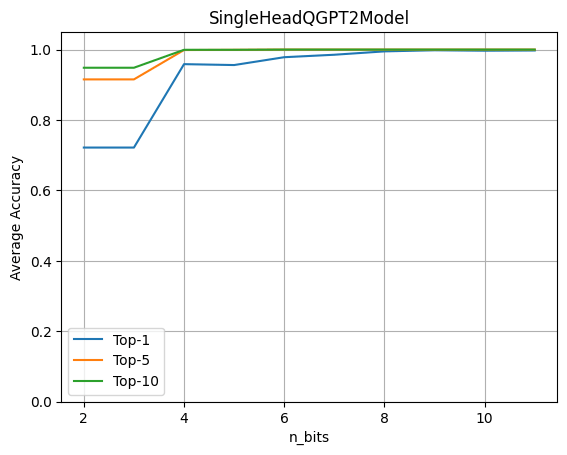
Este gráfico muestra que la cuantificación de 4 bits mantiene el 96% de la precisión original. El experimento se realiza utilizando un conjunto de datos de aproximadamente 80 oraciones. Las métricas se calculan comparando la predicción de los logitos del modelo original con el modelo con la cabeza cuantizada.
Aplicando FHE al modelo GPT2 de Hugging Face
Basado en la biblioteca transformers de Hugging Face, reescribe el paso hacia adelante de los módulos que deseas encriptar, para incluir los operadores cuantizados. Construye una instancia de SingleHeadQGPT2Model cargando primero un GPT2LMHeadModel y luego reemplazando manualmente el primer módulo de atención multi-head como se muestra a continuación utilizando un módulo QGPT2SingleHeadAttention. La implementación completa se puede encontrar aquí.
self.transformer.h[0].attn = QGPT2SingleHeadAttention(config, n_bits=n_bits)Luego se sobrescribe el paso hacia adelante para que la primera cabeza del mecanismo de atención multi-head, incluyendo las proyecciones realizadas para construir las matrices de consulta, claves y valores, se realice con operadores amigables para FHE. El siguiente módulo QGPT2 se puede encontrar aquí.
class SingleHeadAttention(QGPT2):
"""Clase que representa una sola cabeza de atención implementada con métodos de cuantización."""
def run_numpy(self, q_hidden_states: np.ndarray):
# Convertir la entrada a una instancia de DualArray
q_x = DualArray(
float_array=self.x_calib,
int_array=q_hidden_states,
quantizer=self.quantizer
)
# Extraer el nombre del módulo base de atención
mha_weights_name = f"transformer.h.{self.layer}.attn."
# Extraer los valores de peso y sesgo de consulta, clave y valor utilizando los índices adecuados
head_0_indices = [
list(range(i * self.n_embd, i * self.n_embd + self.head_dim))
for i in range(3)
]
q_qkv_weights = ...
q_qkv_bias = ...
# Aplicar la primera proyección para extraer Q, K y V como una sola matriz
q_qkv = q_x.linear(
weight=q_qkv_weights,
bias=q_qkv_bias,
key=f"attention_qkv_proj_layer_{self.layer}",
)
# Extraer las consultas, claves y valores
q_qkv = q_qkv.expand_dims(axis=1, key=f"unsqueeze_{self.layer}")
q_q, q_k, q_v = q_qkv.enc_split(
3,
axis=-1,
key=f"qkv_split_layer_{self.layer}"
)
# Calcular el mecanismo de atención
q_y = self.attention(q_q, q_k, q_v)
return self.finalize(q_y)Otros cálculos en el modelo permanecen en punto flotante, no encriptados y se espera que sean ejecutados por el cliente en el lugar.
Cargando pesos pre-entrenados en el modelo GPT2 modificado de esta manera, luego puedes llamar al método generate:
qgpt2_model = SingleHeadQGPT2Model.from_pretrained(
"gpt2_model", n_bits=4, use_cache=False
)
output_ids = qgpt2_model.generate(input_ids)Como ejemplo, puedes pedirle al modelo cuantizado que complete la frase “La criptografía es”. Con una precisión de cuantización suficiente al ejecutar el modelo en FHE, el resultado de la generación es:
“La criptografía es una parte muy importante de la seguridad de tu computadora”
Cuando la precisión de cuantización es demasiado baja, obtendrás:
“La criptografía es una excelente manera de aprender sobre el mundo que te rodea”
Compilación a FHE
Ahora puedes compilar la cabeza de atención usando el siguiente código de Concrete-ML:
circuit_head = qgpt2_model.compile(input_ids)Al ejecutar esto, verás la siguiente impresión: “Circuito compilado con un ancho de bit de 8”. Esta configuración, compatible con FHE, muestra el ancho de bit máximo necesario para realizar operaciones en FHE.
Complejidad
En los modelos de transformadores, la operación más intensiva computacionalmente es el mecanismo de atención que multiplica las consultas, claves y valores. En FHE, el costo se ve incrementado por la especificidad de las multiplicaciones en el dominio encriptado. Además, a medida que aumenta la longitud de la secuencia, el número de estas multiplicaciones desafiantes aumenta cuadráticamente.
Para la cabeza encriptada, una secuencia de longitud 6 requiere 11,622 operaciones PBS. Este es un primer experimento que no ha sido optimizado para el rendimiento. Si bien puede ejecutarse en cuestión de segundos, requeriría bastante potencia de cálculo. Afortunadamente, el hardware mejorará la latencia de 1000x a 10000x, por lo que las cosas pasarán de varios minutos en la CPU a <100 ms en ASIC una vez que estén disponibles en unos años. Para obtener más información sobre estas proyecciones, consulte esta publicación de blog.
Conclusión
Los Modelos de Lenguaje Grandes son excelentes herramientas de asistencia en una amplia variedad de casos de uso, pero su implementación plantea problemas importantes para la privacidad del usuario. En este blog, viste un primer paso hacia la posibilidad de que todo el LLM funcione con datos encriptados, donde el modelo se ejecutaría completamente en la nube mientras se respeta plenamente la privacidad de los usuarios.
Este paso incluye la conversión de una parte específica en un modelo como GPT2 al ámbito FHE. Esta implementación aprovecha la biblioteca transformers y le permite evaluar el impacto en la precisión cuando parte del modelo se ejecuta en datos encriptados. Además de preservar la privacidad del usuario, este enfoque también permite que el propietario del modelo mantenga una parte importante de su modelo en privado. El código completo se puede encontrar en este ejemplo de caso de uso.
Las bibliotecas Zama Concrete y Concrete-ML (No olvides marcar con estrella los repositorios en GitHub ⭐️💛) permiten la construcción sencilla de modelos de aprendizaje automático y su conversión al equivalente de FHE para poder realizar cálculos y predicciones sobre datos encriptados.
¡Espero que hayas disfrutado esta publicación; no dudes en compartir tus pensamientos/comentarios!
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Un nuevo fondo para mujeres que crean startups de IA en Asia Pacífico
- El Gobierno de Delhi planea construir un centro de IA en la propuesta Ciudad Electrónica
- Conoce a Skill-it un marco de habilidades impulsado por datos para comprender y entrenar modelos de lenguaje
- Las dos métricas que revelan la verdadera dispersión de datos más allá de la desviación estándar
- Desbloqueando la creatividad Cómo la inteligencia artificial generativa y Amazon SageMaker ayudan a las empresas a producir creatividades publicitarias para campañas de marketing con AWS
- Explorando opciones de resumen para Healthcare con Amazon SageMaker
- Código de Destilación de Conocimiento y Pesos de SD-Small y SD-Tiny de código abierto






