En busca de la confianza de una modelo ¿Puedes confiar en una caja negra?
En busca de la confianza de una modelo ¿Puedes confiar en una caja negra?

Los Modelos de Lenguaje Grandes (LLMs) como GPT-4 y LLaMA2 han entrado en la conversación de la [etiquetado de datos]. Los LLMs han recorrido un largo camino y ahora pueden etiquetar datos y asumir tareas históricamente realizadas por humanos. Si bien obtener etiquetas de datos con un LLM es increíblemente rápido y relativamente barato, todavía hay un gran problema, estos modelos son la caja negra definitiva. Entonces, la gran pregunta es: ¿cuánta confianza deberíamos tener en las etiquetas generadas por estos LLMs? En la publicación de hoy, analizamos este dilema para establecer algunas pautas fundamentales para medir la confianza que podemos tener en los datos etiquetados por LLMs.
Antecedentes
- Consejos para navegar con éxito las entrevistas de trabajo de ciencia de datos para principiantes
- Tendencias laborales en análisis de datos IA en análisis de las tendencias laborales
- ¿Quieres convertirte en un científico de datos? Parte 2 10 habilidades blandas que necesitas
Los resultados presentados a continuación son de un experimento realizado por Toloka utilizando modelos populares y un conjunto de datos en turco. Esto no es un informe científico, sino más bien una breve descripción de enfoques posibles para el problema y algunas sugerencias sobre cómo determinar qué método funciona mejor para su aplicación.
La Gran Pregunta
Antes de entrar en los detalles, aquí está la gran pregunta: ¿Cuándo podemos confiar en una etiqueta generada por un LLM y cuándo debemos ser escépticos? Saber esto puede ayudarnos en el etiquetado automático de datos y también puede ser útil en otras tareas aplicadas como el soporte al cliente, la generación de contenido y más.
El Estado Actual de las Cosas
Entonces, ¿cómo están abordando las personas este problema ahora? Algunos le preguntan directamente al modelo para que les dé una puntuación de confianza, otros observan la consistencia de las respuestas del modelo en múltiples ejecuciones, mientras que otros examinan las probabilidades de registro del modelo. Pero, ¿alguno de estos enfoques es confiable? Descubrámoslo.
La Regla General
¿Qué hace que una medida de confianza sea “buena”? Una regla simple a seguir es que debe haber una correlación positiva entre la puntuación de confianza y la precisión de la etiqueta. En otras palabras, una puntuación de confianza más alta debería significar una mayor probabilidad de ser correcta. Puedes visualizar esta relación utilizando un gráfico de calibración, donde los ejes X e Y representan la confianza y la precisión, respectivamente.
Experimentos y Sus Resultados
Enfoque 1: Autoconfianza
El enfoque de autoconfianza implica preguntar directamente al modelo sobre su confianza. ¿Y adivina qué? ¡Los resultados no fueron tan malos! Si bien los LLMs que probamos tuvieron dificultades con el conjunto de datos en un idioma que no es inglés, la correlación entre la confianza autoinformada y la precisión real fue bastante sólida, lo que significa que los modelos son conscientes de sus limitaciones. Obtuvimos resultados similares para GPT-3.5 y GPT-4 aquí.
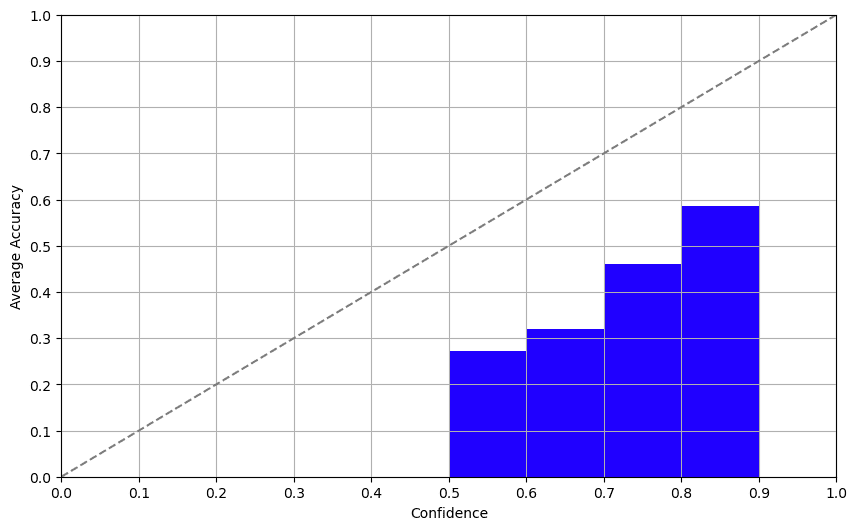
Enfoque 2: Consistencia
Establecer una temperatura alta (~0.7–1.0), etiquetar el mismo elemento varias veces y analizar la consistencia de las respuestas. Para más detalles, ver este artículo. Probamos esto con GPT-3.5 y fue, para decirlo suavemente, un completo desastre. Pedimos al modelo que respondiera la misma pregunta varias veces y los resultados fueron consistentemente erráticos. Este enfoque no es confiable, al igual que pedirle consejos sobre la vida a una bola 8 mágica.
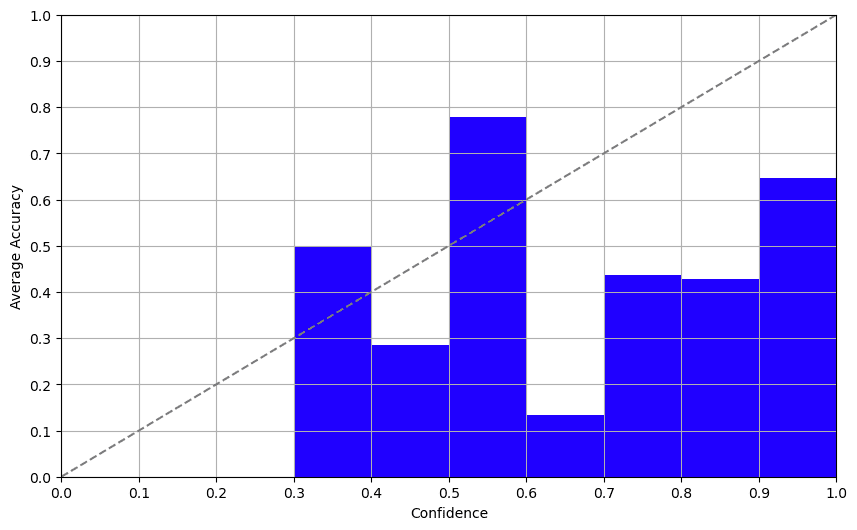
Enfoque 3: Probabilidades de Registro
Las probabilidades de registro ofrecieron una grata sorpresa. Davinci-003 devuelve los logaritmos de probabilidad de los tokens en el modo de completado. Examinando esta salida, obtuvimos una puntuación de confianza sorprendentemente decente que se correlacionó bien con la precisión. Este método ofrece un enfoque prometedor para determinar una puntuación de confianza confiable.
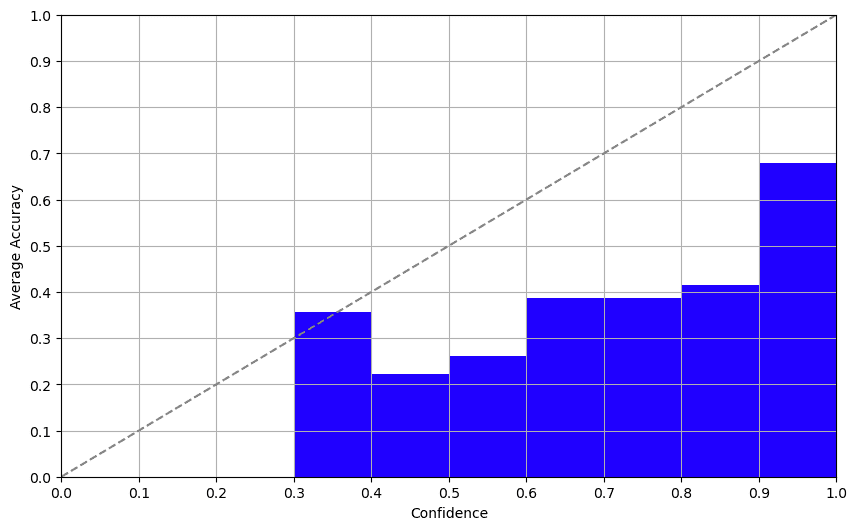
La conclusión
Entonces, ¿qué hemos aprendido? Aquí está, sin rodeos:
- Autoconfianza: útil, pero hay que tener cuidado. Los sesgos se informan ampliamente.
- Consistencia: mejor evitarla. A menos que disfrutes del caos.
- Probabilidades logarítmicas: una apuesta sorprendentemente buena por ahora si el modelo te permite acceder a ellas.
¿Lo emocionante? Las probabilidades logarítmicas parecen ser bastante robustas incluso sin ajustar finamente el modelo, a pesar de que este artículo informa que este método es demasiado confiado. Hay espacio para una mayor exploración.
Avenidas futuras
Un siguiente paso lógico podría ser encontrar una fórmula dorada que combine las mejores partes de cada uno de estos tres enfoques, o explorar nuevos. Entonces, si estás listo para un desafío, ¡este podría ser tu próximo proyecto de fin de semana!
Conclusión
De acuerdo, aficionados y principiantes en el aprendizaje automático, eso es todo. Recuerda, ya sea que estés trabajando en etiquetado de datos o construyendo el próximo gran agente conversacional, entender la confianza del modelo es clave. No tomes esos puntajes de confianza como algo infalible y asegúrate de hacer tu tarea.
Espero que hayas encontrado esto esclarecedor. Hasta la próxima vez, sigue procesando esos números y cuestionando esos modelos. Ivan Yamshchikov es profesor de Procesamiento de Datos Semánticos y Computación Cognitiva en el Center for AI and Robotics, Technical University of Applied Sciences Würzburg-Schweinfurt. También lidera el equipo de Defensores de Datos en Toloka AI. Sus intereses de investigación incluyen la creatividad computacional, el procesamiento de datos semánticos y los modelos generativos.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- SQL en Pandas con Pandasql
- VoAGI Noticias, 5 de octubre 5 libros gratuitos para ayudarte a dominar Python • Los 7 mejores cuadernos de nube gratuitos para Ciencia de Datos
- Combatir la suplantación de identidad por la IA
- ¿Qué tan cerca estamos de la IA generalizada?
- Revelando patrones ocultos Una introducción al agrupamiento jerárquico
- Maximizar el rendimiento en aplicaciones de IA de borde
- La Inteligencia Artificial está controlando la lucha contra el robo de paquetes de UPS





