En busca de un método generalizable para la adaptación de dominio sin fuente
Método generalizable para adaptación de dominio sin fuente
Publicado por Eleni Triantafillou, Científica Investigadora, y Malik Boudiaf, Investigador Estudiantil, Google
El aprendizaje profundo ha avanzado mucho recientemente en una amplia gama de problemas y aplicaciones, pero a menudo los modelos fallan de manera impredecible cuando se implementan en dominios o distribuciones no vistos. La adaptación de dominio sin fuente (SFDA, por sus siglas en inglés) es un área de investigación que tiene como objetivo diseñar métodos para adaptar un modelo pre-entrenado (entrenado en un “dominio fuente”) a un nuevo “dominio objetivo”, utilizando solo datos no etiquetados de este último.
Diseñar métodos de adaptación para modelos profundos es un área importante de investigación. Si bien la escala cada vez mayor de los modelos y los conjuntos de datos de entrenamiento ha sido un ingrediente clave para su éxito, una consecuencia negativa de esta tendencia es que el entrenamiento de dichos modelos es cada vez más costoso computacionalmente, en algunos casos haciendo que el entrenamiento de modelos grandes sea menos accesible y aumentando innecesariamente la huella de carbono. Una forma de mitigar este problema es mediante el diseño de técnicas que puedan aprovechar y reutilizar modelos ya entrenados para abordar nuevas tareas o generalizar a nuevos dominios. De hecho, la adaptación de modelos a nuevas tareas se estudia ampliamente bajo el paraguas del aprendizaje por transferencia.
SFDA es un área particularmente práctica de esta investigación porque varias aplicaciones del mundo real donde se desea la adaptación sufren de la falta de ejemplos etiquetados del dominio objetivo. De hecho, SFDA está recibiendo cada vez más atención [1, 2, 3, 4]. Sin embargo, aunque motivada por objetivos ambiciosos, la mayoría de la investigación en SFDA se basa en un marco muy estrecho, considerando cambios simples en la distribución en tareas de clasificación de imágenes.
- Desbloqueando el éxito con el software de SCM todo lo que necesitas saber
- Codey La IA Generativa de Google para tareas de codificación
- Conoce GPTCache una biblioteca para desarrollar una caché semántica de consultas LLM.
En un cambio significativo de esa tendencia, dirigimos nuestra atención al campo de la bioacústica, donde los cambios en la distribución que ocurren de manera natural son ubicuos, a menudo caracterizados por la falta de datos etiquetados del objetivo y representan un obstáculo para los profesionales. Estudiar SFDA en esta aplicación puede, por lo tanto, no solo informar a la comunidad académica sobre la generalizabilidad de los métodos existentes e identificar direcciones de investigación abiertas, sino que también puede beneficiar directamente a los profesionales en el campo y ayudar a abordar uno de los mayores desafíos de nuestro siglo: la preservación de la biodiversidad.
En esta publicación, anunciamos “En busca de un método generalizable para la adaptación de dominio sin fuente”, que aparece en ICML 2023. Mostramos que los métodos de SFDA de última generación pueden tener un rendimiento deficiente o incluso colapsar cuando se enfrentan a cambios realistas en la distribución en bioacústica. Además, los métodos existentes se comportan de manera diferente entre sí en comparación con lo observado en los puntos de referencia de visión, y sorprendentemente, a veces tienen un rendimiento peor que la ausencia de adaptación. También proponemos NOTELA, un nuevo método simple que supera a los métodos existentes en estos cambios al tiempo que muestra un rendimiento sólido en una variedad de conjuntos de datos de visión. En general, concluimos que evaluar los métodos de SFDA (únicamente) en los conjuntos de datos y cambios de distribución comúnmente utilizados nos deja con una visión miope de su rendimiento relativo y generalizabilidad. Para cumplir con su promesa, los métodos de SFDA deben ser probados en una gama más amplia de cambios de distribución, y abogamos por considerar aquellos que ocurren de manera natural y que pueden beneficiar a aplicaciones de alto impacto.
Cambios en la distribución en bioacústica
Los cambios en la distribución que ocurren de manera natural son ubicuos en la bioacústica. El conjunto de datos etiquetados más grande para canciones de aves es Xeno-Canto (XC), una colección de grabaciones contribuidas por usuarios de aves silvestres de todo el mundo. Las grabaciones en XC son “focalizadas”: se centran en un individuo capturado en condiciones naturales, donde el canto del ave identificada está en primer plano. Sin embargo, para fines de monitoreo y seguimiento continuo, los profesionales a menudo están más interesados en identificar aves en grabaciones pasivas (“paisajes sonoros”), obtenidas a través de micrófonos omnidireccionales. Este es un problema bien documentado que trabajos recientes muestran que es muy desafiante. Inspirados por esta aplicación realista, estudiamos SFDA en bioacústica utilizando un clasificador de especies de aves pre-entrenado en XC como modelo fuente y varios “paisajes sonoros” provenientes de diferentes ubicaciones geográficas: Sierra Nevada (S. Nevada); Powdermill Nature Reserve, Pennsylvania, EE. UU .; Hawái; Caples Watershed, California, EE. UU .; Sapsucker Woods, Nueva York, EE. UU. (SSW); y Colombia – como nuestros dominios objetivo.
Este cambio de un dominio focalizado al pasivo es sustancial: las grabaciones en este último a menudo presentan una relación señal-ruido mucho más baja, varias aves vocalizando al mismo tiempo y distracciones significativas y ruido ambiental, como la lluvia o el viento. Además, diferentes paisajes sonoros se originan en diferentes ubicaciones geográficas, lo que induce cambios extremos en las etiquetas, ya que una pequeña porción de las especies en XC aparecerá en una ubicación determinada. Además, como es común en los datos del mundo real, tanto los dominios fuente como los objetivos tienen una desigualdad significativa en las clases, ya que algunas especies son significativamente más comunes que otras. Además, consideramos un problema de clasificación multi-etiqueta, ya que puede haber varias aves identificadas en cada grabación, un cambio significativo del escenario estándar de clasificación de imágenes de una sola etiqueta donde se suele estudiar SFDA.
 |
| Ilustración del cambio de “focal → paisajes sonoros”. En el dominio focalizado, las grabaciones suelen estar compuestas por una única vocalización de ave en primer plano, capturada con una alta relación señal-ruido (SNR), aunque puede haber otras aves vocalizando en segundo plano. Por otro lado, los paisajes sonoros contienen grabaciones de micrófonos omnidireccionales y pueden estar compuestos por varias aves vocalizando simultáneamente, así como ruidos ambientales de insectos, lluvia, coches, aviones, etc. |
| Archivos de audio | Dominio focal | Dominio de paisajes sonoros1 | ||
| Imágenes de espectrograma |  |
 |
| Ilustración del cambio de distribución del dominio focal (izquierda) al dominio de paisajes sonoros (derecha), en términos de los archivos de audio (arriba) e imágenes de espectrograma (abajo) de una grabación representativa de cada conjunto de datos. Nótese que en el segundo fragmento de audio, el canto del ave es muy tenue; una propiedad común en las grabaciones de paisajes sonoros donde las llamadas de aves no están en primer plano. Créditos: Izquierda: Grabación de XC por Sue Riffe (licencia CC-BY-NC). Derecha: Extracto de una grabación disponible de Kahl, Charif y Klinck. (2022) “Una colección de grabaciones de paisajes sonoros completamente anotadas del Noreste de Estados Unidos” [enlace] del conjunto de datos de paisajes sonoros SSW (licencia CC-BY). |
Los modelos SFDA de última generación tienen un rendimiento deficiente en los cambios de bioacústica
Como punto de partida, evaluamos seis métodos SFDA de última generación en nuestro banco de pruebas de bioacústica y los comparamos con el modelo de origen no adaptado (el modelo de origen). Nuestros hallazgos son sorprendentes: sin excepción, los métodos existentes no son capaces de superar consistentemente al modelo de origen en todos los dominios de destino. De hecho, a menudo tienen un rendimiento inferior de manera significativa.
A modo de ejemplo, Tent, un método reciente, tiene como objetivo hacer que los modelos produzcan predicciones seguras para cada ejemplo reduciendo la incertidumbre de las probabilidades de salida del modelo. Si bien Tent tiene un buen rendimiento en varias tareas, no funciona de manera efectiva para nuestra tarea de bioacústica. En el escenario de una sola etiqueta, minimizar la entropía obliga al modelo a elegir una sola clase para cada ejemplo con confianza. Sin embargo, en nuestro escenario de múltiples etiquetas, no existe tal restricción de que se deba seleccionar alguna clase como presente. Esto, combinado con cambios significativos en la distribución, puede hacer que el modelo colapse, dando como resultado probabilidades cero para todas las clases. Otros métodos evaluados como SHOT, AdaBN, Tent, NRC, DUST y Pseudo-Labelling, que son baselines sólidos para bancos de pruebas SFDA estándar, también tienen dificultades con esta tarea de bioacústica.
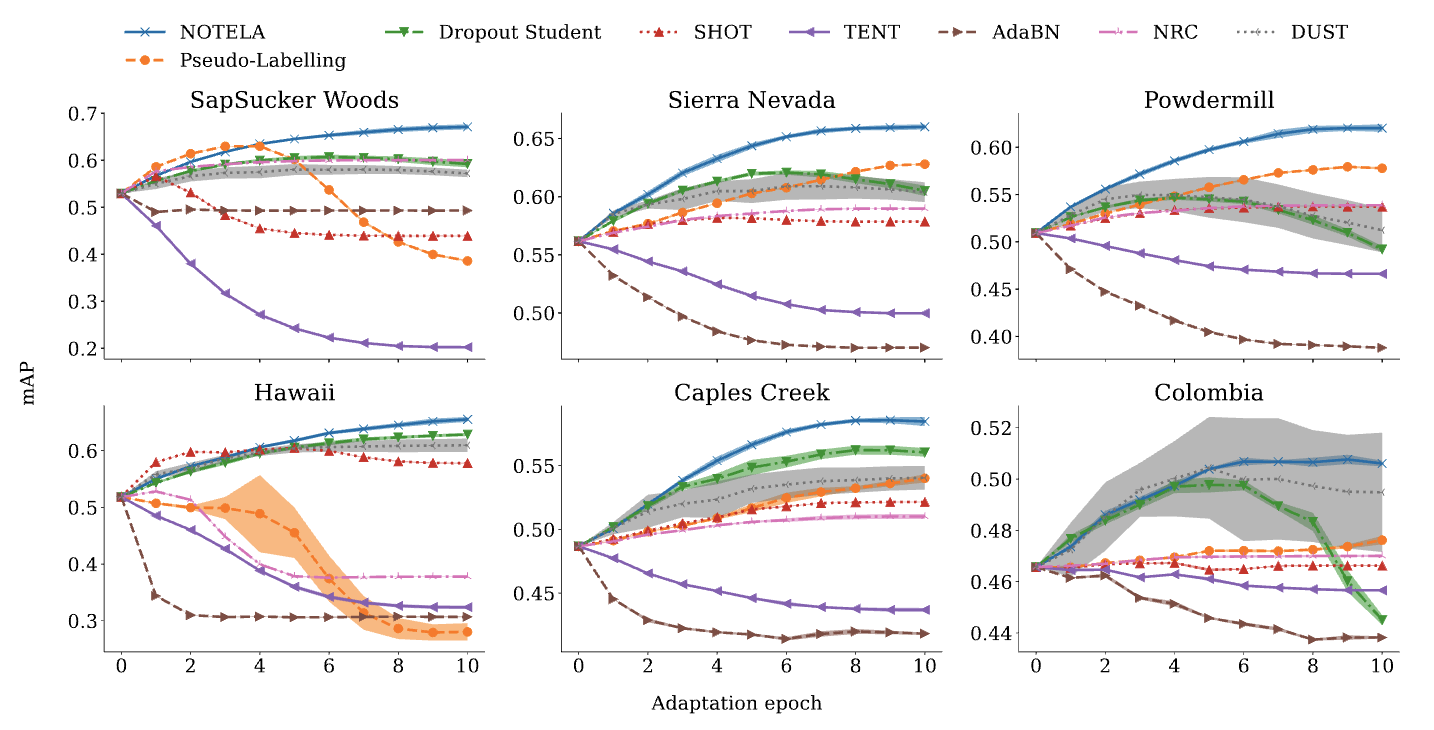 |
| Evolución de la precisión promedio del test (mAP), una métrica estándar para la clasificación multietiqueta, a lo largo del procedimiento de adaptación en los seis conjuntos de datos de paisajes sonoros. Evaluamos nuestro método propuesto NOTELA y Dropout Student (ver más abajo), así como SHOT, AdaBN, Tent, NRC, DUST y Pseudo-Labelling. Aparte de NOTELA, todos los demás métodos no mejoran de manera consistente al modelo de origen. |
Presentando NOisy student TEacher with Laplacian Adjustment (NOTELA)
No obstante, destaca un resultado sorprendentemente positivo: el principio de Noisy Student, menos conocido, parece prometedor. Este enfoque no supervisado alienta al modelo a reconstruir sus propias predicciones en algún conjunto de datos de destino, pero aplicando ruido aleatorio. Aunque el ruido puede introducirse a través de varios canales, buscamos la simplicidad y utilizamos la eliminación de capas (dropout) del modelo como única fuente de ruido: por lo tanto, nos referimos a este enfoque como Dropout Student (DS). En pocas palabras, este enfoque alienta al modelo a limitar la influencia de las neuronas individuales (o filtros) al hacer predicciones en un conjunto de datos de destino específico.
DS, aunque es efectivo, presenta un problema de colapso del modelo en varios dominios de destino. Hipotetizamos que esto ocurre porque el modelo de origen inicialmente carece de confianza en esos dominios de destino. Proponemos mejorar la estabilidad de DS utilizando directamente el espacio de características como una fuente auxiliar de verdad. NOTELA lo logra al alentar pseudoetiquetas similares para puntos cercanos en el espacio de características, inspirado en el método de NRC y la regularización Laplaciana. Este enfoque simple se visualiza a continuación y supera de manera consistente y significativa al modelo de origen tanto en tareas de audio como visuales.
 |
 |
| NOTELA en acción. Las grabaciones de audio se envían a través del modelo completo para obtener un primer conjunto de predicciones, que luego se refinan mediante regularización laplaciana, una forma de post-procesamiento basada en la agrupación de puntos cercanos. Finalmente, las predicciones refinadas se utilizan como objetivos para que el modelo ruidoso las reconstruya. |
Conclusión
Los estándares de referencia para la clasificación artificial de imágenes han limitado inadvertidamente nuestra comprensión de la verdadera generalización y robustez de los métodos SFDA. Abogamos por ampliar el alcance y adoptar un nuevo marco de evaluación que incorpore cambios de distribución de origen natural en bioacústica. También esperamos que NOTELA sirva como una referencia sólida para facilitar la investigación en esa dirección. El alto rendimiento de NOTELA tal vez señale dos factores que pueden conducir al desarrollo de modelos más generalizables: primero, desarrollar métodos teniendo en cuenta problemas más difíciles y segundo, favorecer principios de modelado simples. Sin embargo, aún queda trabajo futuro por hacer para identificar y comprender los modos de falla de los métodos existentes en problemas más difíciles. Creemos que nuestra investigación representa un paso significativo en esta dirección, sirviendo como base para el diseño de métodos SFDA con mayor generalizabilidad.
Agradecimientos
Uno de los autores de esta publicación, Eleni Triantafillou, ahora está en Google DeepMind. Publicamos esta entrada en el blog en nombre de los autores del artículo NOTELA: Malik Boudiaf, Tom Denton, Bart van Merriënboer, Vincent Dumoulin*, Eleni Triantafillou* (donde * indica una contribución igual). Agradecemos a nuestros coautores por el arduo trabajo en este artículo y al resto del equipo de Perch por su apoyo y comentarios.
1Tenga en cuenta que en este fragmento de audio, el canto del pájaro es muy tenue; una propiedad común en las grabaciones de paisajes sonoros donde las llamadas de aves no están en primer plano. ↩︎
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- ¿Qué pasó con la Web Semántica?
- Por qué Silicon Valley es el lugar ideal para la Inteligencia Artificial
- Construye y entrena modelos de visión por computadora para detectar posiciones de autos en imágenes utilizando Amazon SageMaker y Amazon Rekognition
- Acélere los resultados comerciales con mejoras del 70% en el rendimiento del procesamiento de datos, entrenamiento e inferencia con Amazon SageMaker Canvas
- Escala el entrenamiento y la inferencia de miles de modelos de aprendizaje automático con Amazon SageMaker
- Dando a los usuarios más de lo que pueden manejar
- Píldoras de la impresora 3D





