Mejorando el rendimiento de consulta de archivos CSV en ChatGPT
Mejorando rendimiento consulta CSV en ChatGPT
con la Autoconsulta de LangChain basada en un cargador de CSV personalizado
La llegada de modelos de lenguaje sofisticados, como ChatGPT, ha traído un enfoque novedoso y prometedor para consultar datos tabulares. Sin embargo, debido a las limitaciones de tokens, ejecutar una consulta directamente se vuelve desafiante sin la ayuda de APIs como retriever. En consecuencia, la precisión de las consultas depende en gran medida de la calidad de la consulta, y no es raro que los recuperadores estándar no logren devolver la información exacta requerida.
En este artículo, profundizaré en las razones detrás del fracaso de los métodos de recuperación convencionales en ciertos casos de uso. Además, proponemos una solución revolucionaria en forma de un cargador de datos CSV personalizado que incorpora información de metadatos. Al aprovechar la API de Autoconsulta de LangChain junto con el nuevo cargador de datos CSV, podemos extraer información con un rendimiento y precisión significativamente mejorados.
Para ver el código detallado utilizado en este artículo, por favor eche un vistazo al cuaderno aquí. Me gustaría destacar el hecho de que este cuaderno ilustra la posibilidad de que consultar grandes conjuntos de datos tabulares con un LLM puede lograr una precisión notable.
Recuperación en Conjunto de Datos de Población de Enfermedades
Nos gustaría consultar el siguiente conjunto de datos sintético SIR creado por el autor: simulamos los tres grupos diferentes de la población durante 90 días de enfermedad en 10 ciudades basado en un modelo SIR simple. Para simplificar, suponemos que la población de cada ciudad oscila entre 5e3 y 2e4 y no hay movimiento de población entre ciudades. Además, generamos diez números enteros aleatorios entre 500 y 2000 como el número de personas infectadas originalmente.
- Presentamos OpenLLM Biblioteca de código abierto para LLMs
- Construyendo un panel interactivo de ML en Panel
- Cómo construí una canalización de datos en cascada basada en AWS
La tabla tiene la siguiente forma con cinco columnas: “time” que indica el momento en que se midió la población, “city” la ciudad donde se midieron los datos y “susceptible”, “infectious” y “removed” los tres grupos de la población. Para simplificar, los datos se han guardado localmente como un archivo CSV.
time susceptible infectious removed city0 2018-01-01 8639 8639 0 city01 2018-01-02 3857 12338 1081 city02 2018-01-03 1458 13414 2405 city03 2018-01-04 545 12983 3749 city04 2018-01-05 214 12046 5017 city0Desearíamos hacer preguntas a ChatGPT relevantes para el conjunto de datos. Para permitir que ChatGPT interactúe con dichos datos tabulares, seguimos los siguientes pasos estándar utilizando LangChain:
- Usar el Cargador de CSV para cargar los datos,
- Crear un vectorstore (usamos Chroma aquí) para almacenar los datos integrados con los embeddings de OpenAI,
- Usar recuperadores para devolver documentos relevantes para una consulta no estructurada dada.
Puede usar el siguiente código para realizar los pasos anteriores.
# cargar datos desde la ruta localloader = CSVLoader(file_path=LOCAL_PATH)data = loader.load()# Crear embeddingsembeddings = OpenAIEmbeddings()vectorstore = Chroma.from_documents(data, embeddings)# Crear recuperadorretriever=vectorstore.as_retriever(search_kwargs={"k": 20})Ahora podemos definir una ConversationalRetriverChain para consultar el conjunto de datos SIR.
llm=ChatOpenAI(model_name="gpt-4",temperature=0)# Definir las plantillas de mensajes del sistemasystem_template = """El {context} proporcionado es un conjunto de datos tabular que contiene población susceptible, infectada y eliminada durante 90 días en 10 ciudades.El conjunto de datos incluye las siguientes columnas:'time': momento en que se midió la población,'city': ciudad en la que se midió la población,"susceptible": población susceptible de la enfermedad, "infectious": población infectada de la enfermedad, "removed": población eliminada de la enfermedad. ----------------{context}"""# Crear las plantillas de mensajes del chatmessages = [ SystemMessagePromptTemplate.from_template(system_template), HumanMessagePromptTemplate.from_template("{question}")]qa_prompt = ChatPromptTemplate.from_messages(messages)memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)qa = ConversationalRetrievalChain.from_llm(llm=llm, retriever=vectorstore.as_retriever(), return_source_documents=False,combine_docs_chain_kwargs={"prompt": qa_prompt},memory=memory,verbose=True)En el código anterior, he definido una cadena de conversación que buscará la información relevante de la consulta en el conjunto de datos SIR utilizando el recuperador definido en el paso anterior y dará una respuesta basada en la información recuperada. Para dar instrucciones más claras a ChatGPT, también he dado una indicación aclarando la definición de todas las columnas en el conjunto de datos.
Ahora hagamos una pregunta sencilla: “¿Qué ciudad tiene más personas infectadas el 03-02-2018?”
Sorprendentemente, nuestro chatbot dijo: “El conjunto de datos proporcionado no incluye datos para la fecha 03-02-2018.”
¿Cómo es posible?
¿Por qué falló la recuperación?
Para investigar por qué el chatbot no pudo responder una pregunta cuya respuesta está en el conjunto de datos proporcionado, eché un vistazo al documento relevante que recuperó con la pregunta “¿Qué ciudad tiene más personas infectadas el 03-02-2018?”. Obtuve las siguientes líneas:
[Documento(contenido_de_la_página=': 31\ntiempo: 2018-02-01\nsusceptible: 0\ninfecciosos: 1729\nremovidos: 35608\nciudad: ciudad3', metadatos={'fuente': 'sir.csv', 'fila': 301}), Documento(contenido_de_la_página=': 1\ntiempo: 2018-01-02\nsusceptible: 3109\ninfecciosos: 9118\nremovidos: 804\nciudad: ciudad8', metadatos={'fuente': 'sir.csv', 'fila': 721}), Documento(contenido_de_la_página=': 15\ntiempo: 2018-01-16\nsusceptible: 1\ninfecciosos: 2035\nremovidos: 6507\nciudad: ciudad7', metadatos={'fuente': 'sir.csv', 'fila': 645}), Documento(contenido_de_la_página=': 1\ntiempo: 2018-01-02\nsusceptible: 3481\ninfecciosos: 10873\nremovidos: 954\nciudad: ciudad5', metadatos={'fuente': 'sir.csv', 'fila': 451}), Documento(contenido_de_la_página=': 23\ntiempo: 2018-01-24\nsusceptible: 0\ninfecciosos: 2828\nremovidos: 24231\nciudad: ciudad9', metadatos={'fuente': 'sir.csv', 'fila': 833}), Documento(contenido_de_la_página=': 1\ntiempo: 2018-01-02\nsusceptible: 8081\ninfecciosos: 25424\nremovidos: 2231\nciudad: ciudad6', metadatos={'fuente': 'sir.csv', 'fila': 541}), Documento(contenido_de_la_página=': 3\ntiempo: 2018-01-04\nsusceptible: 511\ninfecciosos: 9733\nremovidos: 2787\nciudad: ciudad8', metadatos={'fuente': 'sir.csv', 'fila': 723}), Documento(contenido_de_la_página=': 24\ntiempo: 2018-01-25\nsusceptible: 0\ninfecciosos: 3510\nremovidos: 33826\nciudad: ciudad3', metadatos={'fuente': 'sir.csv', 'fila': 294}), Documento(contenido_de_la_página=': 33\ntiempo: 2018-02-03\nsusceptible: 0\ninfecciosos: 1413\nremovidos: 35924\nciudad: ciudad3', metadatos={'fuente': 'sir.csv', 'fila': 303}), Documento(contenido_de_la_página=': 25\ntiempo: 2018-01-26\nsusceptible: 0\ninfecciosos: 3173\nremovidos: 34164\nciudad: ciudad3', metadatos={'fuente': 'sir.csv', 'fila': 295}), Documento(contenido_de_la_página=': 1\ntiempo: 2018-01-02\nsusceptible: 3857\ninfecciosos: 12338\nremovidos: 1081\nciudad: ciudad0', metadatos={'fuente': 'sir.csv', 'fila': 1}), Documento(contenido_de_la_página=': 23\ntiempo: 2018-01-24\nsusceptible: 0\ninfecciosos: 1365\nremovidos: 11666\nciudad: ciudad8', metadatos={'fuente': 'sir.csv', 'fila': 743}), Documento(contenido_de_la_página=': 16\ntiempo: 2018-01-17\nsusceptible: 0\ninfecciosos: 2770\nremovidos: 10260\nciudad: ciudad8', metadatos={'fuente': 'sir.csv', 'fila': 736}), Documento(contenido_de_la_página=': 3\ntiempo: 2018-01-04\nsusceptible: 487\ninfecciosos: 6280\nremovidos: 1775\nciudad: ciudad7', metadatos={'fuente': 'sir.csv', 'fila': 633}), Documento(contenido_de_la_página=': 14\ntiempo: 2018-01-15\nsusceptible: 0\ninfecciosos: 3391\nremovidos: 9639\nciudad: ciudad8', metadatos={'fuente': 'sir.csv', 'fila': 734}), Documento(contenido_de_la_página=': 20\ntiempo: 2018-01-21\nsusceptible: 0\ninfecciosos: 1849\nremovidos: 11182\nciudad: ciudad8', metadatos={'fuente': 'sir.csv', 'fila': 740}), Documento(contenido_de_la_página=': 28\ntiempo: 2018-01-29\nsusceptible: 0\ninfecciosos: 1705\nremovidos: 25353\nciudad: ciudad9', metadatos={'fuente': 'sir.csv', 'fila': 838}), Documento(contenido_de_la_página=': 23\ntiempo: 2018-01-24\nsusceptible: 0\ninfecciosos: 3884\nremovidos: 33453\nciudad: ciudad3', metadatos={'fuente': 'sir.csv', 'fila': 293}), Documento(contenido_de_la_página=': 16\ntiempo: 2018-01-17\nsusceptible: 1\ninfecciosos: 1839\nremovidos: 6703\nciudad: ciudad7', metadatos={'fuente': 'sir.csv', 'fila': 646}), Documento(contenido_de_la_página=': 15\ntiempo: 2018-01-16\nsusceptible: 1\ninfecciosos: 6350\nremovidos: 20708\nciudad: ciudad9', metadatos={'fuente': 'sir.csv', 'fila': 825})]Sorprendentemente, a pesar de que especifiqué que quería saber qué sucedió en la fecha 2018-02-03, no se devolvió ninguna línea de esa fecha. Dado que nunca se envió información sobre esa fecha a ChatGPT, no hay duda de que no puede responder esa pregunta.
Sumergiéndonos en el código fuente del recuperador, podemos ver que el método get_relevant_documents llama a similarity_search de forma predeterminada. El método devuelve los n fragmentos principales (4 de forma predeterminada, pero establecí el número en 20 en mi código) basados en la métrica de distancia calculada (distancia del coseno de forma predeterminada) que mide la ‘similitud’ entre el vector de la consulta y el vector de los fragmentos del documento.
Volviendo al conjunto de datos del SIR, notamos que cada línea cuenta casi la misma historia: en qué fecha, en qué ciudad y cuántas personas están marcadas como qué grupo. No es sorprendente que los vectores que representan estas líneas sean similares entre sí. Una comprobación rápida de la puntuación de similitud nos da el hecho de que muchas líneas terminan con una puntuación alrededor de 0.29.
Por lo tanto, una puntuación de similitud no es lo suficientemente fuerte como para distinguir las líneas en cuanto a su relevancia para la consulta: esto siempre ocurre en datos tabulares donde las líneas no tienen diferencias significativas entre sí. Necesitamos filtros más fuertes que puedan trabajar en los metadatos.
CSVLoader con Metadatos Personalizados
Parece evidente que la mejora del rendimiento del chatbot depende en gran medida de la eficiencia del recuperador. Para hacerlo, comenzamos definiendo un CSVLoader personalizado que pueda comunicar la información de los metadatos con el recuperador.
Escribimos el siguiente código:
class MetaDataCSVLoader(BaseLoader): """Carga un archivo CSV en una lista de documentos. Cada documento representa una fila del archivo CSV. Cada fila se convierte en un par clave/valor y se muestra en una nueva línea en el contenido de la página del documento. Por defecto, la fuente de cada documento cargado desde el csv se establece en el valor del argumento `file_path` para todos los documentos. Puede anular esto configurando el argumento `source_column` con el nombre de una columna en el archivo CSV. La fuente de cada documento se establecerá entonces en el valor de la columna con el nombre especificado en `source_column`. Ejemplo de salida: .. code-block:: txt columna1: valor1 columna2: valor2 columna3: valor3 """ def __init__( self, file_path: str, source_column: Optional[str] = None, metadata_columns: Optional[List[str]] = None, content_columns: Optional[List[str]] =None , csv_args: Optional[Dict] = None, encoding: Optional[str] = None, ): # omitido (guardado como código original) self.metadata_columns = metadata_columns # < AGREGADO def load(self) -> List[Document]: """Carga los datos en objetos de documento.""" docs = [] with open(self.file_path, newline="", encoding=self.encoding) as csvfile: # omitido (guardado como código original) # CÓDIGO AGREGADO if self.metadata_columns: for k, v in row.items(): if k in self.metadata_columns: metadata[k] = v # FIN DEL CÓDIGO AGREGADO doc = Document(page_content=content, metadata=metadata) docs.append(doc) return docsPara ahorrar espacio, he omitido el código que es igual que el API original y solo he incluido las pocas líneas adicionales que se utilizan principalmente para agregar ciertas columnas que requieren atención especial a los metadatos. De hecho, en los datos impresos anteriormente, se pueden observar dos partes: contenido de la página y metadatos. El CSVLoader estándar escribe todas las columnas de la tabla en el contenido de la página y solo los recursos de datos y los números de línea en los metadatos. El “MetaDataCSVLoader” definido nos permite escribir otras columnas en los metadatos.
Re-creamos ahora el vector store, con los mismos pasos que en la sección anterior, excepto en el cargador de datos en el que agregamos dos metadata_columns “time” y “city”.
# Cargar datos y establecer el cargador de incrustaciones = MetaDataCSVLoader(file_path="sir.csv",metadata_columns=['time','city']) #<= modificado data = loader.load()Autoconsulta en un Vectorstore Informado por Metadatos
Ahora estamos listos para usar la API de Autoconsulta de LangChain:
Según la documentación de LangChain: Un recuperador de autoconsulta es aquel que, como su nombre indica, puede consultarse a sí mismo. … Esto permite al recuperador no solo utilizar la consulta de entrada del usuario para realizar una comparación de similitud semántica con el contenido de los documentos almacenados, sino también extraer filtros de la consulta del usuario sobre los metadatos de los documentos almacenados y ejecutar esos filtros.
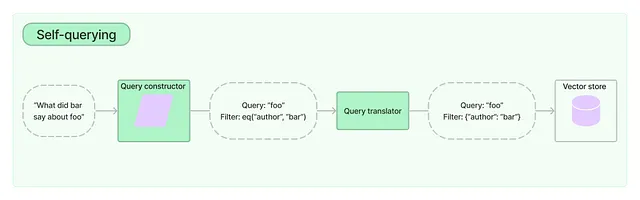
Ahora puedes entender por qué enfaticé los metadatos en el último capítulo: se basa en ellos que ChatGPT u otros LLM pueden construir el filtro para obtener la información más relevante del conjunto de datos. Usamos el siguiente código para construir un recuperador de autoconsulta de este tipo, describiendo los metadatos y la descripción del contenido del documento en base a los cuales se puede construir un filtro bien realizado para extraer la información precisa. En particular, le damos al recuperador un metadata_field_info, especificando el tipo y la descripción de las dos columnas a las que queremos que el recuperador preste más atención.
llm = ChatOpenAI(model_name="gpt-4", temperature=0)metadata_field_info = [ AttributeInfo( name="time", description="tiempo en que se midió la población", type="datetime", ), AttributeInfo( name="city", description="ciudad en la que se midió la población", type="string", ),]document_content_description = "Población susceptible, infectada y removida durante 90 días en 10 ciudades"retriever = SelfQueryRetriever.from_llm( llm, vectorstore, document_content_description, metadata_field_info, search_kwargs={"k": 20}, verbose=True)Ahora podemos definir una ConversationalRetriverChain similar para consultar el conjunto de datos SIR, pero esta vez, con el SelfQueryRetriever. Veamos qué sucederá ahora cuando hagamos la misma pregunta: “¿Qué ciudad tiene la mayor cantidad de personas infectadas el 2018-02-03?”
El chatbot dijo: “La ciudad con la mayor cantidad de personas infectadas el 2018-02-03 es la ciudad3 con 1413 personas infectadas”.
¡Damas y caballeros, es correcto! ¡El chatbot está haciendo su trabajo con un recuperador mejor!
No hace daño ver qué documentos relevantes devuelve el recuperador esta vez y nos da:
[Documento(page_content=': 33\ntiempo: 2018-02-03\nsusceptible: 0\ninfectada: 1413\nremovida: 35924\nciudad: ciudad3', metadata={'source': 'sir.csv', 'row': 303, 'time': '2018-02-03', 'city': 'ciudad3'}), Document(page_content=': 33\ntiempo: 2018-02-03\nsusceptible: 0\ninfectada: 822\nremovida: 20895\nciudad: ciudad4', metadata={'source': 'sir.csv', 'row': 393, 'time': '2018-02-03', 'city': 'ciudad4'}), Document(page_content=': 33\ntiempo: 2018-02-03\nsusceptible: 0\ninfectada: 581\nremovida: 14728\nciudad: ciudad5', metadata={'source': 'sir.csv', 'row': 483, 'time': '2018-02-03', 'city': 'ciudad5'}), Document(page_content=': 33\ntiempo: 2018-02-03\nsusceptible: 0\ninfectada: 1355\nremovida: 34382\nciudad: ciudad6', metadata={'source': 'sir.csv', 'row': 573, 'time': '2018-02-03', 'city': 'ciudad6'}), Document(page_content=': 33\ntiempo: 2018-02-03\nsusceptible: 0\ninfectada: 496\nremovida: 12535\nciudad: ciudad8', metadata={'source': 'sir.csv', 'row': 753, 'time': '2018-02-03', 'city': 'ciudad8'}), Document(page_content=': 33\ntiempo: 2018-02-03\nsusceptible: 0\ninfectada: 1028\nremovida: 26030\nciudad: ciudad9', metadata={'source': 'sir.csv', 'row': 843, 'time': '2018-02-03', 'city': 'ciudad9'}), Document(page_content=': 33\ntiempo: 2018-02-03\nsusceptible: 0\ninfectada: 330\nremovida: 8213\nciudad: ciudad7', metadata={'source': 'sir.csv', 'row': 663, 'time': '2018-02-03', 'city': 'ciudad7'}), Document(page_content=': 33\ntiempo: 2018-02-03\nsusceptible: 0\ninfectada: 1320\nremovida: 33505\nciudad: ciudad2', metadata={'source': 'sir.csv', 'row': 213, 'time': '2018-02-03', 'city': 'ciudad2'}), Document(page_content=': 33\ntiempo: 2018-02-03\nsusceptible: 0\ninfectada: 776\nremovida: 19753\nciudad: ciudad1', metadata={'source': 'sir.csv', 'row': 123, 'time': '2018-02-03', 'city': 'ciudad1'}), Document(page_content=': 33\ntiempo: 2018-02-03\nsusceptible: 0\ninfectada: 654\nremovida: 16623\nciudad: ciudad0', metadata={'source': 'sir.csv', 'row': 33, 'time': '2018-02-03', 'city': 'ciudad0'})]Puede que notes de inmediato que ahora hay “tiempo” y “ciudad” en “metadatos” en los documentos recuperados.
Conclusión
En esta publicación de blog, he explorado las limitaciones de ChatGPT al consultar conjuntos de datos en formato CSV, utilizando el conjunto de datos SIR de 10 ciudades durante un período de 90 días como ejemplo. Para abordar estas limitaciones, he propuesto un enfoque novedoso: un cargador de datos CSV con conocimiento de metadatos que nos permite aprovechar la API de autoconsulta, mejorando significativamente la precisión y el rendimiento del Chatbot.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 4-bit Cuantización con GPTQ
- Formas fascinantes en las que la IA está ayudando a las personas a dominar el alemán y otros idiomas
- Transforma tu proyecto de Ciencia de Datos Descubre los beneficios de almacenar variables en un archivo YAML
- Desbloqueando el potencial del texto Un vistazo más cercano a los métodos de limpieza de texto previo a la incrustación
- Conoce a los razonadores RAP y LLM Dos marcos basados en conceptos similares para el razonamiento avanzado con LLMs
- Keras 3.0 Todo lo que necesitas saber
- La IA y los implantes cerebrales restauran el movimiento y la sensación para un hombre paralizado






