Potencia tu Python Asyncio con Aiomultiprocess Una guía completa
Mejora tu Python Asyncio con Aiomultiprocess Guía completa.
CAJA DE HERRAMIENTAS DE PYTHON
Aprovecha el poder de asyncio y multiprocessing para acelerar tus aplicaciones

En este artículo, te llevaré al mundo de aiomultiprocess, una biblioteca que combina las poderosas capacidades de Python asyncio y multiprocessing.
Este artículo explicará a través de ejemplos de código y mejores prácticas.
Al final de este artículo, comprenderás cómo aprovechar las potentes características de aiomultiprocess para mejorar tus aplicaciones de Python, al igual que un chef principal liderando a un equipo de chefs para crear un festín delicioso.
Introducción
Imagina que quieres invitar a tus colegas a una gran comida durante el fin de semana. ¿Cómo lo harías?
- Cómo convertí una base de datos relacional regular en una base de datos vectorial para almacenar incrustaciones
- Investigadores de la Universidad de Pekín presentan ChatLaw un modelo de lenguaje legal de código abierto de gran tamaño con bases de conocimientos externas integradas.
- 5 Idiomas mejor pagados para aprender este año
Como chef experimentado, ciertamente no cocinarías un plato a la vez; eso sería demasiado lento. Utilizarías eficientemente tu tiempo, dejando que múltiples tareas ocurran simultáneamente.
Por ejemplo, mientras esperas a que hierva el agua, puedes ir a lavar las verduras. De esta manera, puedes echar las verduras en la olla cuando el agua esté hirviendo. Ese es el encanto de la concurrencia.
Sin embargo, las recetas a menudo pueden ser crueles: necesitas seguir revolviendo al hacer sopa; las verduras necesitan ser lavadas y picadas; también necesitas hornear pan, freír filetes y más.
Cuando hay muchos platos que preparar, puedes sentirte abrumado.
Afortunadamente, tus colegas no se quedarán sentados esperando para comer. Vendrán a la cocina a ayudarte, y cada persona adicional actuará como un proceso de trabajo adicional. Esta es la poderosa combinación de multiprocessing y concurrencia.
Lo mismo ocurre con el código. Incluso con asyncio, ¿tu aplicación de Python todavía ha encontrado cuellos de botella? ¿Estás buscando formas de mejorar aún más el rendimiento de tu código concurrente? Si es así, aiomultiprocess es la respuesta que has estado buscando.
Cómo instalar y usarlo básicamente
Instalación
Si usas pip, instálalo de esta manera:
python -m pip install aiomultiprocessSi usas Anaconda, instálalo desde conda-forge:
conda install -c conda-forge aiomultiprocessUso básico
aiomultiprocess se compone de tres clases principales:
Process es la clase base para las otras dos clases y se utiliza para iniciar un proceso y ejecutar una función de coroutine. Normalmente no necesitarás usar esta clase.
Worker se utiliza para iniciar un proceso, ejecutar una función de coroutine y devolver el resultado. Tampoco usaremos esta clase.
Pool es la clase principal en la que nos centraremos. Al igual que multiprocessing.Pool, inicia un grupo de procesos, pero su contexto debe gestionarse utilizando async with. Utilizaremos los dos métodos de Pool: map y apply.
El método map acepta una función de coroutine y un iterable. El Pool iterará sobre el iterable y asignará la función de coroutine para que se ejecute en varios procesos. El resultado del método map se puede iterar de forma asíncrona utilizando async for:
import asyncioimport randomimport aiomultiprocessasync def coro_func(value: int) -> int: await asyncio.sleep(random.randint(1, 3)) return value * 2async def main(): results = [] async with aiomultiprocess.Pool() as pool: async for result in pool.map(coro_func, [1, 2, 3]): results.append(result) print(results)if __name__ == "__main__": asyncio.run(main())El método apply acepta una función de tipo coroutine y la tupla de argumentos requeridos para la función. Según las reglas del planificador, el Pool asignará la función de tipo coroutine a un proceso adecuado para su ejecución.
import asyncio
import random
import aiomultiprocess
async def coro_func(valor: int) -> int:
await asyncio.sleep(random.randint(1, 3))
return valor * 2
async def main():
tareas = []
async with aiomultiprocess.Pool() as pool:
tareas.append(pool.apply(coro_func, (1,)))
tareas.append(pool.apply(coro_func, (2,)))
tareas.append(pool.apply(coro_func, (3,)))
resultados = await asyncio.gather(*tareas)
print(resultados) # Resultado: [2, 4, 6]
if __name__ == "__main__":
asyncio.run(main())Principio de Implementación y Ejemplos Prácticos
Principio de Implementación de aiomultiprocess.Pool
En un artículo anterior, expliqué cómo distribuir tareas asyncio en múltiples núcleos de CPU.
El enfoque general consiste en iniciar un pool de procesos en el proceso principal utilizando loop.run_in_executor. Luego, se crea un bucle de eventos asyncio en cada proceso del pool de procesos y las funciones de tipo coroutine se ejecutan en sus respectivos bucles. El esquema es el siguiente:
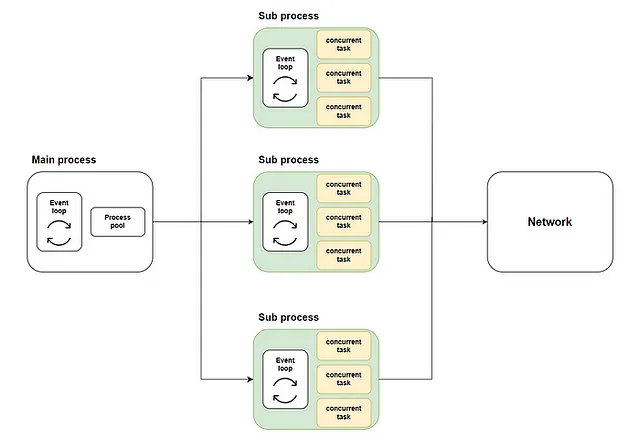
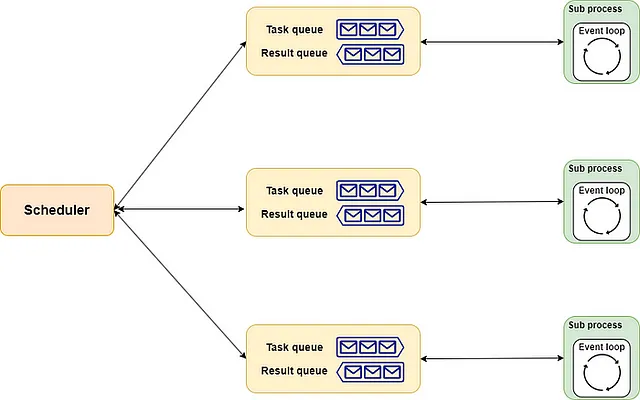
La implementación de aiomultiprocess.Pool es similar. Incluye scheduler, queue y process como sus tres componentes.
- El
schedulerse puede entender como el chef principal, responsable de asignar tareas de manera adecuada a cada chef. Por supuesto, puedes contratar (implementar) un chef principal adecuado a tus necesidades. - La
queuees como la línea de montaje de la cocina. Estrictamente hablando, incluye una línea de pedido y una línea de entrega. El chef principal pasa el menú a través de la línea de pedido a los chefs, y los chefs devuelven los platos terminados a través de la línea de entrega. - El
processes como los chefs en el restaurante. Cada uno maneja varios platos simultáneamente según la asignación. Cada vez que un plato está listo, se entrega en el orden asignado.
Todo el esquema se muestra a continuación:
Ejemplo del Mundo Real
Basado en la introducción proporcionada anteriormente, ahora deberías entender cómo usar aiomultiprocess. Sumerjámonos en un ejemplo del mundo real para experimentar el poder de esta herramienta.
Primero, utilizaremos una llamada remota y un cálculo en bucle para simular el proceso de recuperación y procesamiento de datos en la vida real. Este método demuestra que las tareas vinculadas a E/S y a la CPU a menudo se mezclan, y la frontera entre ellas no es tan clara.
import asyncio
import random
import time
from aiohttp import ClientSession
from aiomultiprocess import Pool
def cpu_bound(n: int) -> int:
resultado = 0
for i in range(n*100_000):
resultado += 1
return resultado
async def invocar_remoto(url: str) -> int:
await asyncio.sleep(random.uniform(0.2, 0.7))
async with ClientSession() as session:
async with session.get(url) as response:
estado = response.status
resultado = cpu_bound(estado)
return resultado
async def main():
inicio = time.monotonic()
tareas = [asyncio.create_task(invocar_remoto("https://www.example.com"))
for _ in range(30)]
await asyncio.gather(*tareas)
print(f"Todas las tareas se completaron en {time.monotonic() - inicio} segundos")
if __name__ == "__main__":
asyncio.run(main())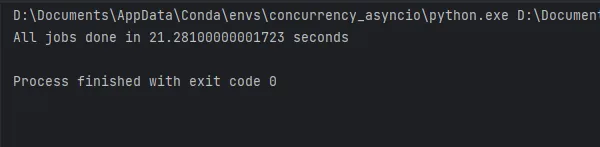
Los resultados de la ejecución del código se muestran en la figura y tarda aproximadamente 21 segundos. Ahora veamos cuánto puede mejorar esto aiomultiprocess.
Usar aiomultiprocess es simple. El código concurrente original no necesita ser modificado. Solo necesitas ajustar el código en el método principal para que se ejecute dentro del Pool:
async def main(): start = time.monotonic() async with Pool() as pool: tasks = [pool.apply(invoke_remote, ("https://www.example.com",)) for _ in range(30)] await asyncio.gather(*tasks) print(f"Todos los trabajos se completaron en {time.monotonic() - start} segundos")if __name__ == "__main__": asyncio.run(main())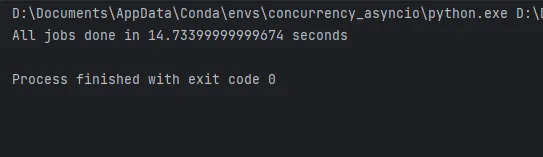
Como puedes ver, el código que utiliza aiomultiprocess solo tarda 14 segundos en completarse en mi computadora portátil. La mejora de rendimiento sería aún mayor en una computadora más potente.
Prácticas recomendadas detalladas
Por último, en base a mi experiencia, permíteme compartir algunas prácticas recomendadas más prácticas.
Usa solo el pool
Aunque aiomultiprocess también proporciona las clases Process y Worker para que podamos elegir, siempre debemos usar la clase Pool para garantizar la máxima eficiencia debido al consumo significativo de recursos al crear procesos.
Cómo usar colas
En un artículo anterior , expliqué cómo usar asyncio.Queue para implementar el patrón productor-consumidor y equilibrar recursos y rendimiento. En aiomultiprocess , también podemos usar colas. Sin embargo, como estamos en un grupo de procesos, no podemos usar asyncio.Queue . Al mismo tiempo, no podemos usar directamente multiprocessing.Queue en el grupo de procesos. En este caso, debes usar multiprocessing.Manager().Queue() para crear una cola, con el siguiente código:
import randomimport asynciofrom multiprocessing import Managerfrom multiprocessing.queues import Queuefrom aiomultiprocess import Poolasync def worker(name: str, queue: Queue): while True: item = queue.get() if not item: print(f"worker: {name} recibió la señal de finalización y dejará de ejecutarse.") queue.put(item) break await asyncio.sleep(random.uniform(0.2, 0.7)) print(f"worker: {name} comienza a procesar el valor {item}", flush=True)async def producer(queue: Queue): for i in range(20): await asyncio.sleep(random.uniform(0.2, 0.7)) queue.put(random.randint(1, 3)) queue.put(None)async def main(): queue: Queue = Manager().Queue() producer_task = asyncio.create_task(producer(queue)) async with Pool() as pool: c_tasks = [pool.apply(worker, args=(f"worker-{i}", queue)) for i in range(5)] await asyncio.gather(*c_tasks) await producer_taskif __name__ == "__main__": asyncio.run(main())Usando initializer para inicializar recursos
Supongamos que necesitas usar una sesión de aiohttp o un grupo de conexiones de base de datos en un método de coroutine, pero no podemos pasar argumentos al crear tareas en el proceso principal porque estos objetos no se pueden serializar.
Una alternativa es definir un objeto global y un método de inicialización. En este método de inicialización, accede al objeto global y realiza la inicialización.
Al igual que multiprocessing.Pool, aiomultiprocess.Pool puede aceptar un método de inicialización y los parámetros de inicialización correspondientes al inicializarse. Este método se llamará para completar la inicialización cuando cada proceso comienza:
import asyncio
from aiomultiprocess import Pool
import aiohttp
from aiohttp import ClientSession, ClientTimeout
session: ClientSession | None = None
def init_session(timeout: ClientTimeout = None):
global session
session = aiohttp.ClientSession(timeout=timeout)
async def get_status(url: str) -> int:
global session
async with session.get(url) as response:
status_code = response.status
return status_code
async def main():
url = "https://httpbin.org/get"
timeout = ClientTimeout(2)
async with Pool(initializer=init_session, initargs=(timeout,)) as pool:
tasks = [asyncio.create_task(pool.apply(get_status, (url,)))
for i in range(3)]
status = await asyncio.gather(*tasks)
print(status)
if __name__ == "__main__":
asyncio.run(main())Manejo de excepciones y reintentos
Aunque aiomultiprocess.Pool proporciona el parámetro exception_handler para ayudar con el manejo de excepciones, si necesitas más flexibilidad, debes combinarlo con asyncio.wait. Para el uso de asyncio.wait, puedes consultar mi artículo anterior.
Con asyncio.wait, puedes obtener tareas que encuentran excepciones. Después de extraer la tarea, puedes hacer algunos ajustes y luego volver a ejecutar la tarea, como se muestra en el siguiente código:
import asyncio
import random
from aiomultiprocess import Pool
async def worker():
await asyncio.sleep(0.2)
result = random.random()
if result > 0.5:
print("lanzará una excepción")
raise Exception("algo salió mal")
return result
async def main():
pending, results = set(), []
async with Pool() as pool:
for i in range(7):
pending.add(asyncio.create_task(pool.apply(worker)))
while len(pending) > 0:
done, pending = await asyncio.wait(pending, return_when=asyncio.FIRST_EXCEPTION)
print(f"ahora el recuento de hechas, pendientes es {len(done)}, {len(pending)}")
for result in done:
if result.exception():
pending.add(asyncio.create_task(pool.apply(worker)))
else:
results.append(await result)
print(results)
if __name__ == "__main__":
asyncio.run(main())Uso de Tenacity para reintentos
Por supuesto, tenemos opciones más flexibles y poderosas para el manejo de excepciones y reintentos, como el uso de la biblioteca Tenacity, que expliqué en este artículo.
Con Tenacity, el código anterior se puede simplificar significativamente. Solo necesitas agregar un decorador al método de la corutina y el método se reintentará automáticamente cuando se lance una excepción.
import asyncio
from random import random
from aiomultiprocess import Pool
from tenacity import *
@retry()
async def worker(name: str):
await asyncio.sleep(0.3)
result = random()
if result > 0.6:
print(f"{name} lanzará una excepción")
raise Exception("algo salió mal")
return result
async def main():
async with Pool() as pool:
tasks = pool.map(worker, [f"worker-{i}" for i in range(5)])
results = await tasks
print(results)
if __name__ == "__main__":
asyncio.run(main())Uso de tqdm para indicar el progreso
Me gusta tqdm porque siempre puede decirme hasta dónde ha llegado el código cuando estoy esperando frente a la pantalla. Este artículo también explica cómo usarlo.
Dado que aiomultiprocess utiliza la API de asyncio para esperar a que se completen las tareas, también es compatible con tqdm:
import asyncio
from random import uniform
from aiomultiprocess import Pool
from tqdm.asyncio import tqdm_asyncio
async def worker():
delay = uniform(0.5, 5)
await asyncio.sleep(delay)
return delay * 10
async def main():
async with Pool() as pool:
tasks = [asyncio.create_task(pool.apply(worker)) for _ in range(1000)]
results = await tqdm_asyncio.gather(*tasks)
print(results[:10])
if __name__ == "__main__":
asyncio.run(main())Conclusión
Correr código asyncio es como un chef cocinando una comida. Aunque puedas mejorar la eficiencia al correr diferentes tareas concurrentemente, eventualmente te encontrarás con cuellos de botella.
La solución más simple en este punto es agregar más chefs para aumentar la paralelización del proceso de cocina.
Aiomultiprocess es una poderosa biblioteca de Python. Al permitir que las tareas concurrentes se ejecuten en múltiples procesos, rompe perfectamente los cuellos de botella de rendimiento causados por la naturaleza de un solo hilo de asyncio.
El uso y las mejores prácticas de aiomultiprocess en este artículo se basan en mi experiencia laboral. Si estás interesado en algún aspecto, no dudes en comentar y unirte a la discusión.
Además de mejorar la velocidad de ejecución del código y el rendimiento, el uso de varias herramientas para mejorar la eficiencia en el trabajo también es una mejora de rendimiento:

Peng Qian
Python Toolbox
Ver lista de 4 historias 
Únete a VoAGI con mi enlace de referencia – Peng Qian
Como miembro de VoAGI, una parte de tu tarifa de membresía se destina a los escritores que lees y obtienes acceso completo a cada historia…
qtalen.medium.com
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Investigadores de Stanford presentan HyenaDNA un modelo genómico de base de largo alcance con longitudes de contexto de hasta 1 millón de tokens a una resolución de nucleótido único.
- Aprendizaje Automático Hecho Intuitivo
- Guía para principiantes para construir tus propios modelos de lenguaje grandes desde cero.
- Simplifica la creación y mantenimiento de DAG en Airflow con Hamilton en 8 minutos
- Conoce Magic123 Un novedoso proceso de conversión de imagen a 3D que utiliza una optimización en dos etapas, de áspero a refinado, para producir geometría y texturas 3D de alta calidad y alta resolución.
- Bootcamp Intensivo de Aprendizaje Automático para el Desarrollo de Habilidades
- Usé ChatGPT (todos los días) durante 5 meses. Aquí hay algunas joyas ocultas que cambiarán tu vida.






