Mejora la predicción de datos tabulares con el modelo de lenguaje grande a través de la API de OpenAI
Mejora predicción de datos tabulares con modelo de lenguaje grande vía API OpenAI
Implementación de Python con clasificación de aprendizaje máquina, ingeniería de prompt, ingeniería de características en incrustación de texto y explicabilidad de modelos con OpenAI API
En estos días, los modelos de lenguaje grandes y las aplicaciones o herramientas están en todas partes, en las noticias y en la VoAGI social. La página de tendencias de GitHub muestra una presencia sustancial de repositorios que utilizan ampliamente modelos de lenguaje grandes. Hemos visto las fantásticas capacidades de los modelos de lenguaje grandes para crear escritos para marketing, resumir documentos, componer música y generar código para el desarrollo de software.
Las empresas tienen una abundancia de datos tabulares (uno de los formatos de datos más antiguos y ubicuos que se pueden representar en una tabla con filas y columnas) acumulados internamente y en línea. ¿Podemos aplicar modelos de lenguaje grandes a datos tabulares en el ciclo de vida tradicional de aprendizaje máquina para mejorar el rendimiento del modelo y agregar valor comercial?
En este artículo, exploraremos el siguiente tema con código de implementación completo en Python:
- Construcción de modelos lineales generalizados y modelos basados en árboles en el conjunto de datos público de análisis y predicción de ataques cardíacos de Kaggle.
- Ingeniería de prompts para transformar datos tabulares en texto
- Clasificación sin entrenamiento con OpenAI API (modelo GPT-3.5: text-davinci-003)
- Mejora del rendimiento del modelo de aprendizaje máquina con API de incrustación de texto de OpenAI: text-embedding-ada-002
- Explicabilidad de predicciones con API de OpenAI: gpt-3.5-turbo
Descripción del conjunto de datos
Los datos están disponibles en el sitio web de Kaggle bajo la licencia CC0 1.0 Universal (CC0 1.0) Public Domain Dedication, que no tiene derechos de autor (puede copiar, modificar, distribuir y realizar el trabajo, incluso con fines comerciales). Consulte el enlace mencionado a continuación:
- ¡Deja de ignorar a Julia! Aprende ahora y agradece a tu yo más joven en el futuro
- Errores que los nuevos científicos de datos novatos deben evitar
- Explorando el Árbol de Pensamiento Promoviendo Cómo la IA puede aprender a razonar a través de la búsqueda
Conjunto de datos de análisis y predicción de ataques cardíacos
Un conjunto de datos para la clasificación de ataques cardíacos
www.kaggle.com
Contiene características demográficas, condiciones médicas y objetivo. Las columnas se explican a continuación:
- age: edad del solicitante
- sex: sexo del solicitante
- cp: tipo de dolor de pecho: el valor 1 es angina típica, el valor 2 es angina atípica, el valor 3 es dolor no anginoso y el valor 4 es asintomático.
- trtbps: presión arterial en reposo (en mm Hg)
- chol: colesterol en mg/dl obtenido a través del sensor de IMC
- fbs: azúcar en sangre en ayunas > 120 mg/dl, 1 = verdadero, 0 = falso
- restecg: resultados electrocardiográficos en reposo
- thalachh: frecuencia cardíaca máxima alcanzada
- exng: angina inducida por ejercicio (1 = sí; 0 = no)
- oldpeak: pico anterior
- slp: pendiente
- caa: número de vasos principales
- thall: tasa de thal
- output: variable objetivo, 0 = menor probabilidad de ataque cardíaco, 1 = mayor probabilidad de ataque cardíaco
Modelos de aprendizaje máquina
Se desarrollan modelos de clasificación binaria para predecir la probabilidad de tener un ataque cardíaco. Esta sección cubrirá:
- Pre-procesamiento: verificación de valores faltantes, codificación one-hot, división estratificada de entrenamiento y prueba, etc.
- Construcción de 4 modelos, incluidos tres modelos lineales generalizados y un modelo basado en árboles: Regresión Logística, Ridge, Lasso y Bosque Aleatorio
- Evaluación del modelo con AUC
Primero, importemos paquetes, carguemos los datos, pre-procesemos y dividamos en entrenamiento y prueba.
import warningswarnings.filterwarnings("ignore")# Matemáticas y Vectoresimport pandas as pdimport numpy as np# Visualizacionesimport plotly.express as px# Aprendizaje Máquinafrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import roc_auc_scoreimport concurrent.futures# Funciones de utilidadfrom utils import prediction, compile_prompt, get_embedding, ml_models, create_auc_chart, gpt_reasoningpd.set_option('display.max_columns', None)# cargar los datosdf = pd.read_csv("./data/raw data/heart_attack_predicton_kaggle.csv")df.shape# verificar valores faltantesdf.isna().sum()# verificar distribución de resultadosdf['output'].value_counts()# codificación one-hotcat_cols = ['sex','exng','cp','fbs','restecg','slp','thall']df_model = pd.get_dummies(df,columns=cat_cols)df_model.shape# división estratificada de entrenamiento y prueba# Separar variables dependientes e independientesX = df_model.drop(axis=1,columns=['output'])y = df_model['output'].tolist()X_tr, X_val, y_tr, y_val = train_test_split(X, y, test_size=0.2, random_state=101, stratify=y,shuffle=True)A continuación, construyamos el objeto del modelo, ajustemos el modelo, hagamos la predicción en el conjunto de pruebas y calculemos el AUC.
## función del modelo def ml_models(): lr = LogisticRegression(penalty='none', solver='saga', random_state=42, n_jobs=-1) lasso = LogisticRegression(penalty='l1', solver='saga', random_state=42, n_jobs=-1) ridge = LogisticRegression(penalty='l2', solver='saga', random_state=42, n_jobs=-1) rf = RandomForestClassifier(n_estimators=300, max_depth=5, min_samples_leaf=50, max_features=0.3, random_state=42, n_jobs=-1) models = {'LR': lr, 'LASSO': lasso, 'RIDGE': ridge, 'RF': rf} return modelsmodels = ml_models()lr = models['LR']lasso = models['LASSO'] ridge = models['RIDGE'] rf = models['RF'] pred_dict = {}for k, m in models.items(): print(k) m.fit(X_tr, y_tr) preds = m.predict_proba(X_val)[:,1] auc = roc_auc_score(y_val, preds) pred_dict[k] = preds print(k + ': ', auc)A continuación, visualicemos y comparemos el rendimiento del modelo (AUC).
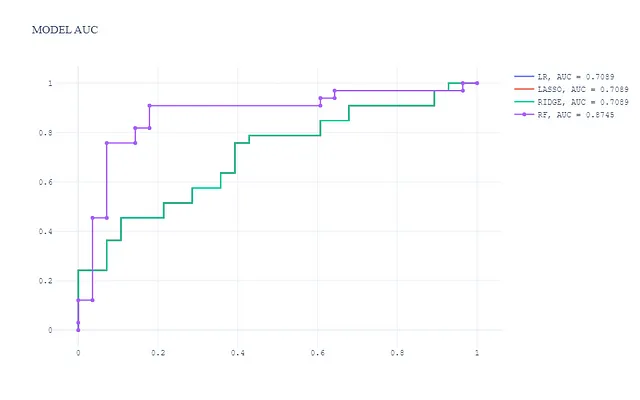
En esta visualización:
- El modelo basado en árboles (Random Forest) tiene el mejor rendimiento con un AUC mucho más alto.
- Los 3 modelos lineales generalizados tienen un nivel de rendimiento y AUC similares, que es más bajo que el modelo basado en árboles, como se esperaba.
Clasificación zero-shot con la API de OpenAI
Realizaremos una clasificación zero-shot en los datos tabulares con la API de OpenAI que se basa en el modelo de texto-davinci-003. Antes de sumergirnos en la implementación en Python, entendamos un poco más sobre la clasificación zero-shot. La definición de Hugging face es:
La clasificación zero-shot es la tarea de predecir una clase que el modelo no ha visto durante el entrenamiento. Este método, que aprovecha un modelo de lenguaje pre-entrenado, se puede pensar como una instancia de transferencia de aprendizaje, que generalmente se refiere a usar un modelo entrenado para una tarea en una aplicación diferente a aquella para la que fue entrenado originalmente. Esto es particularmente útil en situaciones donde la cantidad de datos etiquetados es pequeña.
En la clasificación zero-shot, se proporciona al modelo una indicación y una secuencia de texto que describe lo que queremos que el modelo haga, sin ningún ejemplo de comportamiento esperado. Esta sección cubrirá:
- Preprocesamiento de datos tabulares para el diseño de la indicación
- Indicaciones a modelos de lenguaje basados en aprendizaje de lenguaje
- Predicción zero-shot con la API GPT-3.5: texto-davinci-003
- Evaluación del modelo con AUC
Preprocesamiento de datos tabulares
Primero, procesemos los datos antes de la indicación:
df_gpt = df.copy()df_gpt['sex'] = np.where(df_gpt['sex'] == 1, 'Masculino', 'Femenino')df_gpt['cp'] = np.where(df_gpt['cp'] == 1, 'Angina típica', np.where(df_gpt['cp'] == 2, 'Angina atípica', np.where(df_gpt['cp'] == 3, 'Dolor no anginal', 'Asintomático')))df_gpt['fbs'] = np.where(df_gpt['fbs'] == 1, 'Azúcar en sangre en ayunas > 120 mg/dl', 'Azúcar en sangre en ayunas <= 120 mg/dl')df_gpt['restecg'] = np.where(df_gpt['restecg'] == 0, 'Normal', np.where(df_gpt['restecg'] == 1, 'Anomalía de onda ST-T (inversiones de onda T y/o elevación o depresión ST > 0.05 mV)', "Mostrando hipertrofia ventricular izquierda probable o definitiva según los criterios de Estes"))df_gpt['exng'] = np.where(df_gpt['exng'] == 1, 'Angina inducida por ejercicio', 'Sin angina inducida por ejercicio')df_gpt['slp'] = np.where(df_gpt['slp'] == 0, 'La pendiente del segmento ST del ejercicio máximo es descendente', np.where(df_gpt['slp'] == 1, 'La pendiente del segmento ST del ejercicio máximo es plana', 'La pendiente del segmento ST del ejercicio máximo es ascendente'))df_gpt['thall'] = np.where(df_gpt['thall'] == 1, 'Thall tiene un defecto fijo', np.where(df_gpt['thall'] == 2, 'Thall es normal', 'Thall tiene un defecto reversible'))# convertir df en diccionario de aplicacionesapplication_list = X_val.to_dict(orient='records')len(application_list)Interacción con LLMs
Las indicaciones son una herramienta poderosa para interactuar con modelos de lenguaje grandes para una tarea específica. Una indicación es una entrada proporcionada por el usuario a la cual se espera que el modelo responda. Las indicaciones pueden tener varias formas, como texto o una imagen.
En este artículo, la indicación incluye instrucciones con el formato de salida JSON esperado y la pregunta en sí misma. Con el conjunto de datos de ataques al corazón, una indicación de texto puede ser la siguiente:
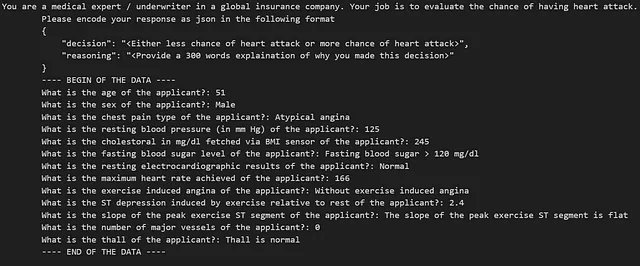
A continuación, definiremos la indicación y la función de llamada a la API, que construye la indicación y obtiene la respuesta de OpenAI-3.5 API.
def prediccion_GPT3_5(datos, explicar = False): if explicar: indicacion = logica_indicacion(explicar) else: indicacion = logica_indicacion(explicar) print(indicacion) respuesta = openai.Completion.create( model = 'text-davinci-003', prompt=indicacion, max_tokens=64, n=1, stop=None, temperature=0.5, top_p=1.0, frequency_penalty=0.0, presence_penalty=0.0 ) try: salida = respuesta.choices[0].text.strip() salida_dict = json.loads(salida) return salida_dict except (IndexError, ValueError): return Nada def prediccion(datos_combinados_argu): datos_aplicacion, explicar = datos_combinados_argu respuesta = prediccion_GPT3_5(datos_aplicacion, explicar) return respuestaObtener la respuesta de la API – multiprocesamiento
El multiprocesamiento se utiliza para acelerar la llamada a la API. El código es el siguiente:
### obtener la predicción del modelo GPT-3.5: text-davinci-003 - multiprocesamiento poolwith concurrent.futures.ThreadPoolExecutor() as executor: # Combinar datos_creditos y explicar en un solo iterable datos_combinados = zip(lista_aplicaciones, [False] * len(lista_aplicaciones)) # Enviar las tareas de procesamiento de transacciones al ejecutor resultados = executor.map(prediccion, datos_combinados) # Recopilar las respuestas en una lista respuestas = list(resultados)respuestas_df = pd.DataFrame(respuestas)respuestas_df.shapeAUC de clasificación sin etiquetas
El AUC es de 0.48 para la clasificación sin etiquetas, lo que sugiere que las predicciones son peores que el azar e indica que potencialmente no hay fugas en el modelo GPT-3.5 text-davinci-003 en este conjunto de datos.
auc_gpt= roc_auc_score(y_val, respuestas_df['salida'])auc_gptMejorar el rendimiento del modelo de aprendizaje automático con embebido de OpenAI
El embebido de LLM es un punto final de un modelo de lenguaje grande (por ejemplo, OpenAI API) que facilita la realización de tareas de lenguaje natural y código, como búsqueda semántica, agrupación, modelado de temas y clasificación. Con la ingeniería de indicaciones, los datos tabulares se transforman en texto de lenguaje natural que se puede utilizar para generar los embebidos. Los embebidos tienen el potencial de mejorar el rendimiento de los modelos de aprendizaje automático tradicionales al permitirles comprender mejor el lenguaje natural y adaptarse al contexto con una pequeña cantidad de datos etiquetados. En resumen, es un tipo de ingeniería de características en este contexto.
La ingeniería de características es el proceso de transformar datos en características que representen mejor el problema subyacente para los modelos predictivos, lo que resulta en una mayor precisión del modelo en datos no vistos.
En esta sección, veremos:
- Cómo obtener los embebidos de OpenAI mediante una llamada a la API
- Comparación del rendimiento del modelo: con embebidos vs sin embebidos
Primero, definamos la función para obtener los embebidos a través de la API y combinarlos con el conjunto de datos sin procesar:
# Definir la función para obtener el embebido def obtener_embebido(texto, modelo="text-embedding-ada-002"): texto = texto.replace("\n", " ") return openai.Embedding.create(input = [texto], model=modelo)['data'][0]['embedding']# Llamada a la API y combinación con el conjunto de datos sin procesardf_gpt['ada_embedding'] = df_gpt.combinado.apply(lambda x: obtener_embebido(x, modelo='text-embedding-ada-002'))df_gpt = df_gpt.join(pd.DataFrame(df_gpt['ada_embedding'].apply(pd.Series)))df_gpt.drop(['combinado', 'ada_embedding'], axis = 1, inplace = True)df_gpt.columns = df_gpt.columns.tolist()[:14] + ['Embebido_' + str(i) for i in df_gpt.columns.tolist()[14:]]df = pd.concat([df, df_gpt[[i for i in df_gpt.columns.tolist() if i.startswith('Embebido_')]]], axis=1)df_gpt.shapeSimilar a los modelos de aprendizaje automático puros, también realizaremos una división estratificada y ajustaremos el modelo:
# Separar variables dependientes e independientesX = df.drop(axis=1,columns=['output'])y = df['output'].tolist()X_tr, X_val, y_tr, y_val = train_test_split(X, y, test_size=0.2, random_state=101, stratify=y,shuffle=True)models = ml_models()lr = models['LR']lasso = models['LASSO'] ridge = models['RIDGE'] rf = models['RF'] pred_dict_gpt = {}for k, m in models.items(): print(k) m.fit(X_tr, y_tr) preds = m.predict_proba(X_val)[:,1] auc = roc_auc_score(y_val, preds) pred_dict_gpt[k + '_Con_Embebido_GPT'] = preds print(k + '_Con_Embebido_GPT' + ': ', auc)Comparación del rendimiento del modelo – con vs sin características de incrustación
Al combinar los modelos sin características de incrustación, tenemos un total de 8 modelos. La curva ROC en el conjunto de prueba se muestra a continuación:
pred_dict_combinado = dict(list(pred_dict.items()) + list(pred_dict_gpt.items()))create_auc_chart(pred_dict_combinado, y_val, 'AUC del modelo')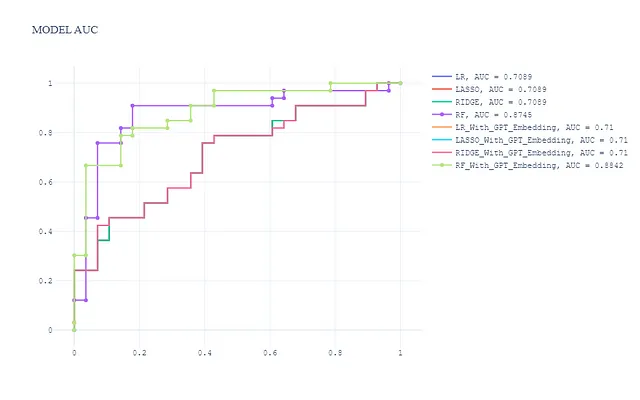
En general, observamos:
- Las características de incrustación no mejoran significativamente el rendimiento del modelo lineal generalizado (Regresión Logística, Ride y Lasso)
- El modelo de Bosque Aleatorio con características de incrustación tiene el mejor rendimiento y es ligeramente mejor que el modelo de Bosque Aleatorio sin características de incrustación.
Vemos el potencial de los grandes modelos de lenguaje para integrarse en el proceso de entrenamiento del modelo tradicional y mejorar la calidad de la salida. Nos puede surgir la pregunta, ¿pueden los grandes modelos de lenguaje ayudar a explicar la decisión del modelo? Toquemos este tema en la siguiente sección.
Explicabilidad del modelo con OpenAI API – gpt-3.5-turbo
La explicabilidad del modelo es uno de los temas clave en las aplicaciones de aprendizaje automático, especialmente en áreas como seguros, salud, finanzas y derecho, donde los usuarios necesitan comprender cómo un modelo toma decisiones a nivel local y global. He escrito un artículo relacionado con la interpretación de modelos de aprendizaje profundo utilizando SHAP si desea saber más sobre la interpretación de modelos en modelos de aprendizaje profundo.
Esta sección cubre:
- Preparar la entrada para la API de OpenAI
- Obtener razonamiento a través del modelo gpt-3.5-turbo
Primero, preparemos la entrada para la llamada a la API.
datos_aplicacion = lista_aplicacion[0]datos_aplicacion{'edad': 51, 'sexo': 'Masculino', 'cp': 'Angina atípica', 'trtbps': 125, 'chol': 245, 'fbs': 'Azúcar en sangre en ayunas > 120 mg/dl', 'restecg': 'Normal', 'thalachh': 166, 'exng': 'Sin angina inducida por ejercicio', 'oldpeak': 2.4, 'slp': 'La pendiente del segmento ST del ejercicio máximo es plana', 'caa': 0, 'thall': 'Thall es normal'}A continuación, obtengamos el razonamiento llamando a la API gpt-3.5-turbo.
objetos_mensaje = [ {"rol": "sistema", "contenido": '''Eres un experto médico/asegurador en una compañía de seguros global. Tu trabajo es evaluar la probabilidad de sufrir un ataque al corazón. Por favor, codifica tu respuesta en formato JSON en el siguiente formato {{ "decisión": "<Ya sea menor probabilidad de ataque al corazón o mayor probabilidad de ataque al corazón>", }}'''}, {"rol": "usuario", "contenido": prompt}, ]completado = openai.ChatCompletion.create( model="gpt-3.5-turbo", messages=objetos_mensaje, max_tokens=1000, # Ajusta el max_tokens según la longitud deseada de la respuesta stop=None, # Establece condiciones de parada personalizadas si es necesario )# Extrae el contenido del mensaje de respuesta contenido_respuesta = completado.choices[0].message["contenido"]La respuesta es bastante impresionante y el modelo de lenguaje grande muestra fuertes capacidades de razonamiento junto con explicaciones razonables.
{ “decision“: “menos posibilidad de ataque al corazón”, “razonamiento“: “Basado en la información proporcionada, el solicitante tiene varios factores que indican una menor probabilidad de sufrir un ataque al corazón. En primer lugar, la edad del solicitante es de 51 años, lo cual no se considera joven pero tampoco está en el rango de alto riesgo para ataques al corazón. En segundo lugar, el solicitante es hombre. Si bien los hombres generalmente tienen un mayor riesgo que las mujeres de sufrir ataques al corazón, no es el único factor determinante. En tercer lugar, el tipo de dolor en el pecho reportado por el solicitante es angina atípica. La angina atípica se caracteriza por un dolor en el pecho menos predecible y puede tener diferentes patrones en comparación con la angina típica. Esto puede indicar un menor riesgo de ataque al corazón en comparación con la angina típica. En cuarto lugar, la presión arterial en reposo del solicitante es de 125 mm Hg. Esto se encuentra dentro del rango normal y no indica hipertensión, que es un factor de riesgo para los ataques al corazón. En quinto lugar, el nivel de colesterol del solicitante es de 245 mg/dl. Aunque esto es más alto que el nivel recomendado, no es extremadamente alto y no se proporciona el IMC del solicitante, por lo que no podemos determinar si el nivel de colesterol es alto debido a la obesidad. En sexto lugar, el solicitante no tiene niveles de azúcar en sangre en ayunas superiores a 120 mg/dl, lo que indica un menor riesgo de diabetes, otro factor de riesgo para los ataques al corazón. En séptimo lugar, los resultados electrocardiográficos en reposo del solicitante son normales, lo que indica una función cardíaca normal y reduce el riesgo de ataque al corazón. En octavo lugar, la frecuencia cardíaca máxima alcanzada por el solicitante es de 166, lo cual es una buena señal ya que indica un sistema cardiovascular más saludable. En noveno lugar, el solicitante no experimenta angina inducida por el ejercicio, lo cual es otro factor positivo. En décimo lugar, la depresión del segmento ST inducida por el ejercicio en relación con el reposo es de 2.4, lo cual está dentro del rango normal y no indica una isquemia significativa. En undécimo lugar, la pendiente del segmento ST del ejercicio máximo es plana, lo cual podría ser un hallazgo normal o relacionado con la angina atípica reportada por el solicitante. Por último, el solicitante no tiene vasos principales y un Thall normal, lo cual indica un menor riesgo de enfermedad de las arterias coronarias. Teniendo en cuenta todos estos factores, es probable que el solicitante tenga una menor probabilidad de sufrir un ataque al corazón. Sin embargo, es importante tener en cuenta que esta evaluación se basa únicamente en la información proporcionada y puede ser necesario realizar una evaluación médica adicional para tomar una determinación definitiva.” }
Resumen
Los modelos de lenguaje grandes son una herramienta poderosa para resolver una amplia gama de casos de uso en diversas industrias. La creación de aplicaciones LLM es más fácil y cada vez más asequible. Los LLM definitivamente agregarán un valor real al negocio.
Antes de irte
¡Te invito a unirte a una emocionante y fructífera aventura de aprendizaje en ciencia de datos! Mantente conectado siguiendo mi página de VoAGI para recibir un flujo constante de contenido cautivador sobre ciencia de datos. Compartiré más conceptos básicos de aprendizaje automático, conceptos básicos de PLN y la implementación completa de ciencia de datos en los próximos meses. ¡Salud!
Referencia
- https://platform.openai.com/docs/guides/embeddings/what-are-embeddings
- https://platform.openai.com/docs/models/overview
¿Qué es la clasificación sin entrenamiento? – Hugging Face
Aprende sobre la clasificación sin entrenamiento usando aprendizaje automático
huggingface.co
Una introducción a los modelos de lenguaje grandes: ingeniería de indicaciones y ajuste de P | Blog técnico de NVIDIA
ChatGPT ha causado una gran impresión. Los usuarios están emocionados de usar el chatbot de IA para hacer preguntas, escribir poemas, infundir a…
developer.nvidia.com
Interpretación del modelo de aprendizaje profundo utilizando SHAP
Implementación en Python en datos de imagen y tabulares
towardsdatascience.com
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- ¿Qué es la innatismo y importa para la inteligencia artificial? (Parte 2)
- Hacia una IA de nivel Dios desde una IA de nivel Perro
- ¿Dónde ocurre la IA?
- Revolucionando el Desarrollo de Software La Dupla Dinámica de la IA y el Código
- Microsoft AI Research presenta un nuevo marco de aprendizaje profundo llamado Distributional Graphormer (DiG) para predecir la distribución de equilibrio de sistemas moleculares.
- ChatGPT obtiene una puntuación en el 1% superior en la prueba de creatividad humana
- Una forma sencilla de mejorar las entrevistas de ciencia de datos