Mejor que GPT-4 para consultas SQL NSQL (Totalmente OpenSource)
Mejor que GPT-4 para consultas SQL NSQL (Totalmente OpenSource)
NSQL es una nueva familia de modelos de base grandes de código abierto (FMs) diseñados específicamente para tareas de generación de SQL
Levanta la mano si has intentado usar ChatGPT o cualquiera de los otros LLMs para generar consultas SQL. ¡Yo lo he hecho, y actualmente lo estoy haciendo! Pero me emociona compartir contigo que se ha lanzado una nueva familia de modelos de base grandes de código abierto (FMs) diseñados específicamente para tareas de generación de SQL. Su nombre es NSQL. Tiene múltiples versiones, comenzando desde NSQL-350M, NSQL-2B y NSQL-6B. NSQL-6B supera a todos los modelos de código abierto existentes en las pruebas de referencia de SQL estándar e incluso a modelos generales comerciales como ChatGPT, GPT3, GPT3.5 y GPT4.
¿Listo para usar vs. Afinamiento fino?
¿Por qué SQL? SQL sigue siendo el lenguaje más comúnmente utilizado. Puede que estés utilizando diferentes variantes de SQL, desde Oracle, MySQL, PostgreSQL hasta MSSQL; pero SQL sigue siendo utilizado universalmente. ¿No sería genial si pudiéramos escribir consultas SQL haciendo preguntas a un modelo de lenguaje grande? Ahorraría mucho trabajo y probablemente democratizaría el acceso a información para casi todos en la empresa que la necesiten.
¿Cómo podemos lograr eso? Por lo general, pensamos en una de las dos opciones, un modelo listo para usar o un modelo de base afinado para una tarea específica. Ambos tienen ventajas y desventajas, como que los modelos listos para usar están entrenados con datos públicos y carecen del conocimiento específico de tu organización.
Si eres como yo, sabes a lo que me refiero. Cada empresa, unidad de negocio e incluso a veces ingeniero (desafortunadamente) pueden tener su propia convención de nombres para diversas bases de datos, esquemas, nombres de tablas y campos. Saber qué significa cada campo es el 80% de la batalla por la que todos luchamos en los primeros 3-6 meses del proceso de capacitación que comienza con la integración y aparentemente nunca termina. Pero dejando las bromas a un lado, este es verdaderamente el problema con los modelos de código abierto desarrollados utilizando datos públicos. Personalizar estos modelos utilizando datos específicos de la organización es el reto para los científicos de datos y la oportunidad para el negocio. Esto permite que el modelo sea más flexible con los datos que cada organización tiene para ofrecer.
- Benford’s Law se encuentra con el aprendizaje automático para detectar seguidores falsos en Twitter
- Decodificación del código de vestimenta 👗 Aprendizaje profundo para la detección automatizada de prendas de moda
- Introducción al procesamiento de imágenes con Python
Uno podría usar un mega modelo como GPTs y pensar que funcionará si solo se proporciona el contexto. Bueno, digo que no estás completamente equivocado, pero aún así te sorprenderás la cantidad de veces que el modelo alucina (incluso en configuraciones de temperatura=0). Además, pedirle a un modelo general del tamaño de 500B parámetros que escriba una consulta SQL específica puede ser un trabajo que no se ajuste a los recursos utilizados. Entonces, ¿cuál es la solución?
Un FM completamente de código abierto específicamente para tareas de SQL
La IA está ganando impulso y la adopción de la IA ha sido bastante lenta en las empresas. Algunas industrias están preparadas para su adopción, pero hay mucho rezago en términos de experiencia, infraestructura y, en general, disposición para invertir en soluciones de datos basadas en IA. De hecho, muy pocas empresas tienen la capacidad de construir su propio código FM. Esto significa que necesitarán una alternativa de código abierto o cerrado para llenar el vacío. Hay algunas brechas específicas cuando se trata de usar modelos de estantería abiertos/cerrados.
Carecen de personalización, como se mencionó antes. Cada dato en cada empresa y su base de código casi siempre son únicos. Eso significa que el modelo único que se adapta a todos puede no ser la mejor idea.
Además, hay muchos lenguajes de programación en uso en las empresas en varios departamentos. Los modelos desarrollados para manejar muchos lenguajes pueden funcionar como generalistas pero no como especialistas. A veces eso significa que “casi” obtuviste la respuesta, pero el “casi” lo hizo completamente e inutilizable.
La privacidad también es uno de los grandes problemas. Las empresas a menudo son reticentes a utilizar un motor de terceros para impulsar el autobús de la IA. Preferirían no compartir nada con la empresa que les proporciona el modelo de IA. Esto significa que es difícil construir cosas que estén especializadas en la tarea. Si se realiza una encuesta, apuesto a que la mayoría de las empresas hoy preferirían utilizar su propio hardware para manejar todo en lugar de un tercero (especialmente si las tareas se centran en la privacidad).
Enfoque de NSQL para responder tus preguntas

NSQL ha ejecutado la siguiente solución. El primer paso fue recolectar una gran cantidad de datos. Este es el corpus de códigos SQL generales de la web utilizando aprendizaje auto-supervisado. Los datos de entrada para el proceso de entrenamiento del modelo contienen tanto el código SQL como el esquema de datos utilizando pares de texto-etiqueta SQL. Luego, se entrenó aún más para seguir las tareas específicas más comunes y se le proporcionaron los códigos que ejecutan estas tareas. Este es el proceso de ajuste fino para que un modelo SQL general esté más sintonizado con las preguntas más comunes que una persona puede hacer a la base de datos.
NSQL: Detalles de datos y entrenamiento
Para entrenar NSQL se crearon 2 conjuntos de datos.
- Un conjunto de datos de pre-entrenamiento compuesto por consultas SQL generales (Los datos están disponibles en huggingface aquí https://huggingface.co/datasets/bigcode/the-stack )
- Un conjunto de datos de ajuste fino compuesto por pares de texto-etiqueta SQL (Estos pares de texto-etiqueta SQL provienen de 20 fuentes públicas diferentes en la web y abarcan desde WiliSQL hasta datos médicos como MIMIC_III (lee más sobre la serie MIMIC aquí https://medium.com/mlearning-ai/what-is-mimic-iv-newer-better-modular-release-of-mimic-4083e3cb14fe )
Aquí está la lista completa de bases de datos de ajuste fino

Estos datos se aumentaron con ampliación de esquemas, limpieza de SQL y generación de mejores instrucciones. Se incluyeron un total de 300,000 muestras en los datos de ajuste fino. Los datos estarán disponibles en HuggingFace.
El entrenamiento se realizó en 2 pasos, comenzando con el pre-entrenamiento utilizando solo códigos SQL como el primer paso, y luego el ajuste fino utilizando los pares de texto-etiqueta SQL con esquema.
Rendimiento
NSQL fue evaluado en dos benchmarks estándar de texto-etiqueta SQL:
The Spider
El benchmark The Spider contiene preguntas de más de 200 bases de datos diversas que abarcan desde actores hasta vehículos. Lee más al respecto aquí https://yale-lily.github.io/spider .
Geoquery
Geoquery se enfoca en preguntas sobre geografía de Estados Unidos. Lee más sobre GeoQuery aquí
Veredicto
La versión 6B de NSQL tiene un mejor rendimiento que todos los modelos de código abierto existentes en hasta 6 puntos en el benchmark de Precisión de Ejecución de Spider.

En comparación con los modelos de código cerrado, la versión 6B muestra resultados aún mejores con una ventaja saludable de 9 puntos en el benchmark de Precisión de Ejecución de Spider (en comparación con ChatGPT) también. En comparación con el modelo CodeGen de Salesforce, tanto NSQL pre-entrenado (no ajustado fino) tiene un mejor rendimiento en un 35-60%, mientras que el modelo NSQL instruct (ajustado fino) tiene un rendimiento 100 al 400% mejor.

Análisis cualitativo:
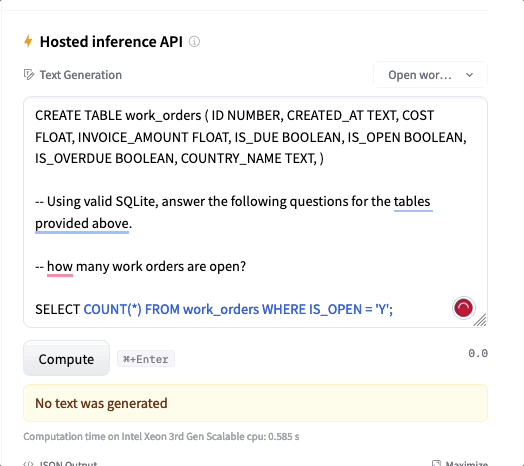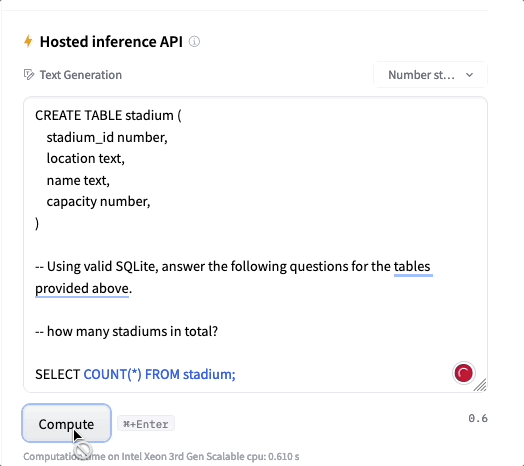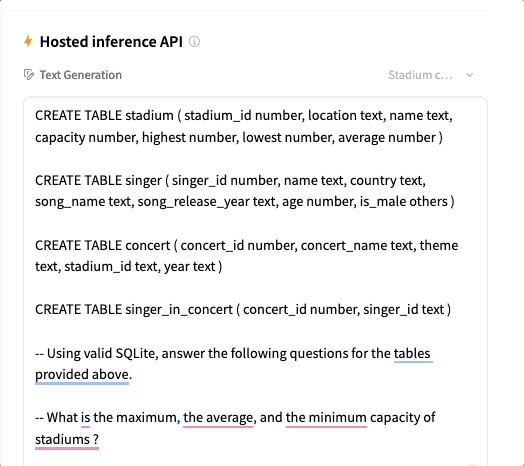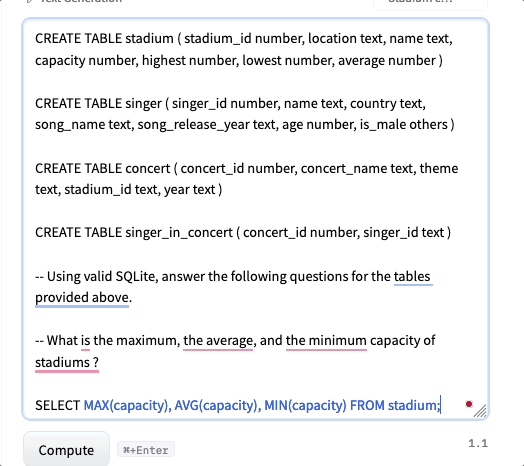
Los investigadores también realizaron la evaluación del modelo utilizando métodos cualitativos. El resultado de dicha evaluación fue que el modelo NSQL podía seguir instrucciones mejor, y además, alucinaba menos que cualquier modelo existente. Esto es especialmente cierto cuando se proporciona el esquema como contexto. El modelo NSQL funciona mejor si las instrucciones son explícitas. Aquí hay un ejemplo de casos en los que el modelo tuvo un buen desempeño y algunos (5,6) en los que el modelo falló bastante debido a que los ingresos en el contexto no estaban definidos.
Código de creación de esquema —

Evaluación cualitativa.

¿Qué significa esto?
Hace unos días alguien se acercó a mí diciendo: “Hola, trabajo en el sector de la salud y no podemos enviar los datos a ninguna otra entidad. Nos gustaría generar consultas basadas en la entrada del usuario. Estaba seguro de que podría hacerlo utilizando modelos disponibles, pero ahora estoy seguro de que podré hacerlo.”
Tal vez el rendimiento de este modelo pre-entrenado sea menor de lo que espero, pero podría ajustarlo utilizando los datos de la empresa o simplemente proporcionar capacitación a los empleados para que puedan utilizar la herramienta de la manera correcta.
Todos los créditos van a NnumbersStation.ai por poner el poder de NSQL al alcance de las personas. Esta versión es completamente gratuita tanto para trabajos académicos como comerciales, lo que la convierte en un modelo increíblemente flexible para comenzar a trabajar. Además, no olvidemos el poder de las personas. ¡Cuando los pesos de LLaMa se filtraron, obtuvimos todos los modelos de animales del Reino Mammalia! Creo que ahora debemos esperar una gran cantidad de modelos derivados de esta versión de NSQL.
¿Dónde puedo jugar con el modelo?
Los modelos NSQL-350M, NSQL-2B y NSQL-6B están disponibles en HuggingFace, incluyendo los pesos del modelo. Puedes usar el entorno de prueba con el modelo 350M (los demás modelos son demasiado grandes para ser cargados en la API de inferencia)
NumbersStation (NumbersStation)
Perfil de NumbersStation en Hugging Face, la comunidad de IA construyendo el futuro.
huggingface.co
¿Dónde puedo encontrar el código inicial?
En GitHub, puedes encontrar cuadernos que te guiarán a través de la configuración y el trabajo con los sabores de SQL de Postgres y Sqlite. El repositorio y los ejemplos no están bien configurados, así que espera contratiempos como que el paquete del manifiesto se haya indicado con la versión 0.1.9 en los requisitos, pero solo están disponibles las versiones hasta 0.1.8. Haz los ajustes necesarios antes de ejecutarlo localmente utilizando SQLite (recomiendo SQLite, ya que no requerirá que crees una base de datos y un usuario de Postgres solo para empezar.
¡Buena suerte! Y diviértete con ello.
Si has llegado hasta este punto — ¡Gracias! ¡Eres un héroe! Lamento el artículo corto y posiblemente apresurado esta vez. Intento mantener a mis lectores al día con “eventos interesantes en el mundo de la IA”, así que por favor 🔔 aplaude | sigue | subscríbete
Conviértete en miembro utilizando mi referencia: https://ithinkbot.com/membership
Encuéntrame en Linkedin https://www.linkedin.com/in/mandarkarhade/
GPT-4: 8 Modelos en Uno ; El Secreto ha Sido Revelado
GPT4 mantuvo el modelo en secreto para evitar la competencia, ¡ahora el secreto ha sido revelado!
pub.towardsai.net
Conoce el Modelo de Fundación Completamente de Código Abierto de Salesforce XGen-7B
Este modelo permite secuencias largas de hasta 8K tokens completamente gratis
pub.towardsai.net
Conoce MPT-30B: Un LLM Completamente de Código Abierto que Supera a GPT-3
Lanzando dos variantes ajustadas, MPT-30B-Instruct y MPT-30B-Chat, que se construyen sobre MPT-30B
pub.towardsai.net
¡Olvida el stack LAMP: ¡Aquí está el stack LLM!
Huggingface se ha posicionado como el nuevo stack estándar en el ecosistema NLP/LLM. Ahora las empresas lo están solicitando…
pub.towardsai.net
Conoce a Gorilla: Un LLM completamente de código abierto ajustado para llamadas a API
Menos alucinaciones y mejor que GPT-4 en la escritura de llamadas a API
pub.towardsai.net
Ajusta finamente el modo GPT utilizando Lit-Parrot de Lightening-AI
¡BYOD Trae tus datos! y Entrenemos en tu GPU
pub.towardsai.net
WizardLM: Generador de datos de instrucciones automatizado completamente de código abierto
Automatiza los pasos tediosos de la generación de datos de entrenamiento basados en instrucciones
pub.towardsai.net
Falcon-40B: Un LLM de Fundación completamente de código abierto
Cada Contribuyente otorga a ti una licencia perpetua, mundial, no exclusiva, irrevocable de derechos de autor para…
pub.towardsai.net
H2Oai lanza GPT completamente de código abierto
Se han lanzado los modelos h2oGPT-20B, h2oGPT-12B v1 y h2oGPT-12B v2 con licencia Apache 2.0 (Completamente gratuito para…
pub.towardsai.net

We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Desbloqueando el poder de Pandas Una inmersión profunda en .loc y .iloc
- Cuándo y cuándo no utilizar el Aprendizaje Automático en tu estrategia empresarial
- Análisis de Sentimientos en Python utilizando Flair
- Búsqueda de empleo en Ciencia de Datos 5 libros que guiaron mi camino hacia el empleo
- Posibles restricciones de exportación de chips de inteligencia artificial en Estados Unidos sacuden el mercado tecnológico.
- Bailey Kacsmar, estudiante de doctorado en la Universidad de Waterloo – Serie de entrevistas
- Inflection AI asegura una financiación de $1.3 mil millones liderada por titanes tecnológicos y gigantes de la industria.





