Conoce Video-ControlNet Un nuevo modelo de difusión de texto a video que cambiará el juego y dará forma al futuro de la generación de video controlable.
Meet Video-ControlNet, a new text-to-video dissemination model that will change the game and shape the future of controllable video generation.


En los últimos años, ha habido un rápido desarrollo en la generación de contenido visual basado en texto. Entrenados con pares imagen-texto a gran escala, los modelos actuales de difusión de texto a imagen (T2I, por sus siglas en inglés) han demostrado una impresionante capacidad para generar imágenes de alta calidad basadas en las indicaciones de texto proporcionadas por el usuario. El éxito en la generación de imágenes también se ha extendido a la generación de videos. Algunos métodos aprovechan los modelos T2I para generar videos de manera one-shot o zero-shot, mientras que los videos generados a partir de estos modelos siguen siendo inconsistentes o carecen de variedad. Escalando los datos de video, los modelos de difusión de texto a video (T2V, por sus siglas en inglés) pueden crear videos consistentes con las indicaciones de texto. Sin embargo, estos modelos generan videos que carecen de control sobre el contenido generado.
Un estudio reciente propone un modelo de difusión T2V que permite mapas de profundidad como control. Sin embargo, se requiere un conjunto de datos a gran escala para lograr consistencia y alta calidad, lo que es antieconómico en cuanto a recursos. Además, todavía es un desafío para los modelos de difusión T2V generar videos de consistencia, longitud arbitraria y diversidad.
Se ha introducido Video-ControlNet, un modelo T2V controlable, para abordar estos problemas. Video-ControlNet ofrece las siguientes ventajas: mejora de la consistencia a través del uso de prioridades de movimiento y mapas de control, la capacidad de generar videos de longitud arbitraria mediante el empleo de una estrategia de condicionamiento del primer fotograma, generalización del dominio mediante la transferencia de conocimientos de imágenes a videos y eficiencia de recursos con una convergencia más rápida mediante un tamaño de lote limitado.
- Una comparación de algoritmos de aprendizaje automático en Python y R.
- Búsqueda de similitud, Parte 5 Hashing sensible a la localidad (LSH)
- Moldeando el Futuro de la IA Una Encuesta Exhaustiva sobre Modelos de Pre-Entrenamiento Visión-Lenguaje y su Papel en Tareas Uni-Modales y Multi-Modales.
La arquitectura de Video-ControlNet se muestra a continuación.
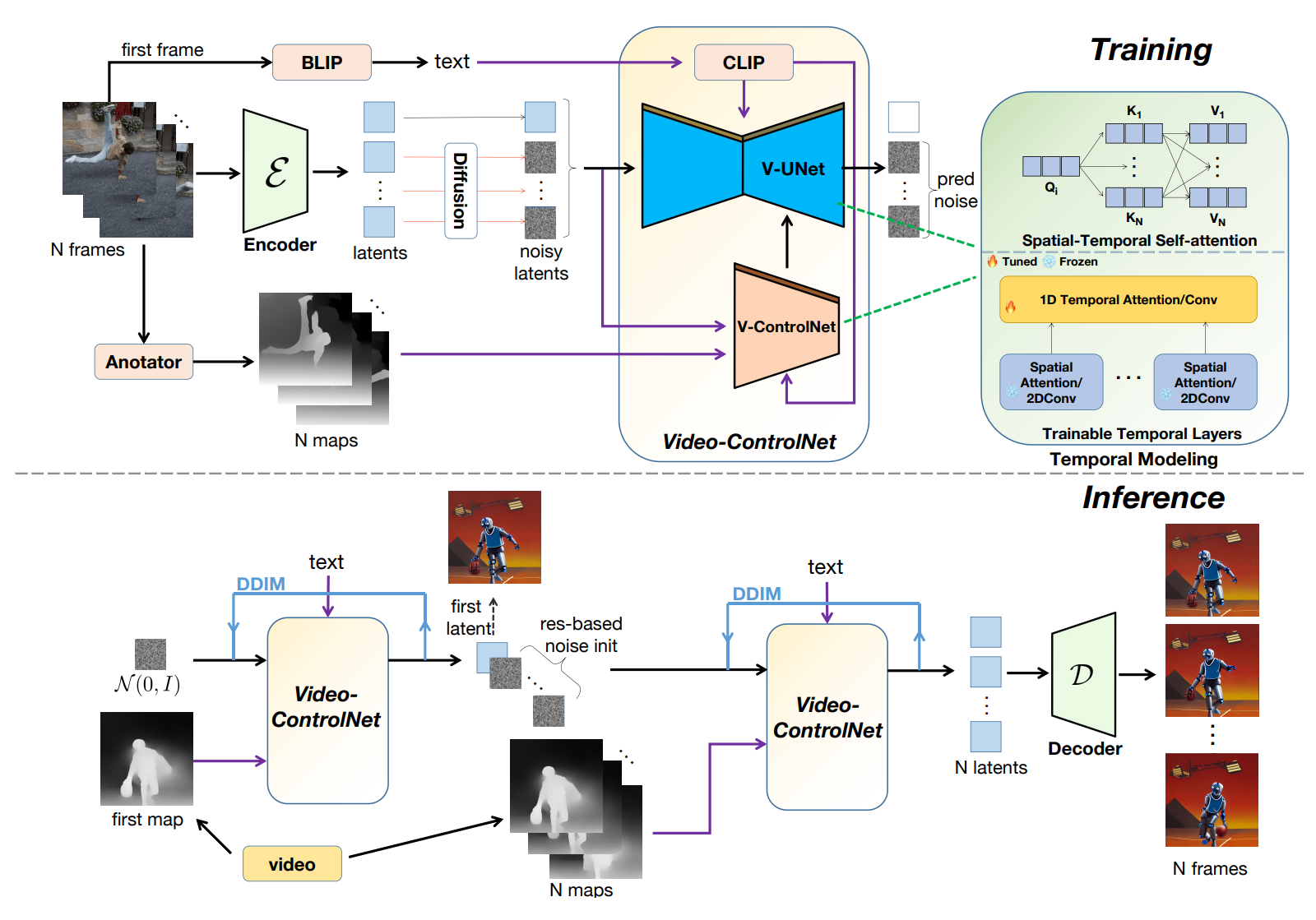

El objetivo es generar videos basados en texto y mapas de control de referencia. Por lo tanto, el modelo generativo se desarrolla mediante la reorganización de un modelo T2I controlable pre-entrenado, la incorporación de capas temporales adicionales entrenables y la presentación de un mecanismo de auto-atención espacial-temporal que facilita las interacciones detalladas entre los fotogramas. Este enfoque permite la creación de videos consistentes en contenido, incluso sin un extenso entrenamiento.
Para asegurar la consistencia de la estructura de video, los autores proponen un enfoque pionero que incorpora la prioridad de movimiento del video fuente en el proceso de desenfoque en la etapa de inicialización de ruido. Al aprovechar la prioridad de movimiento y los mapas de control, Video-ControlNet es capaz de producir videos que parpadean menos y se asemejan de cerca a los cambios de movimiento en el video de entrada, evitando así la propagación de errores en otros métodos basados en el movimiento debido a la naturaleza del proceso de desenfoque de múltiples pasos.
Además, en lugar de los métodos anteriores que entrenan modelos para generar directamente videos completos, se introduce un esquema de entrenamiento innovador en este trabajo, que produce videos basados en el fotograma inicial. Con una estrategia tan sencilla pero efectiva, se vuelve más manejable desentrañar el aprendizaje de contenido y temporal, ya que el primero se presenta en el primer fotograma y la indicación de texto.
El modelo solo necesita aprender a generar fotogramas posteriores, heredando capacidades generativas del dominio de la imagen y aliviando la demanda de datos de video. Durante la inferencia, se genera el primer fotograma condicionado al mapa de control del primer fotograma y una indicación de texto. Luego, se generan fotogramas posteriores, condicionados al primer fotograma, texto y mapas de control posteriores. Al mismo tiempo, otra ventaja de tal estrategia es que el modelo puede generar automáticamente un video de longitud infinita tratando el último fotograma de la iteración anterior como el fotograma inicial.
Así es como funciona. Echemos un vistazo a los resultados reportados por los autores. Se muestra un lote limitado de resultados de muestra y la comparación con enfoques de vanguardia en la figura a continuación.

Este fue el resumen de Video-ControlNet, un nuevo modelo de difusión para la generación de T2V con calidad y consistencia temporal de última generación. Si estás interesado, puedes aprender más sobre esta técnica en los siguientes enlaces.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Implemente un punto final de inferencia de ML sin servidor para modelos de lenguaje grandes utilizando FastAPI, AWS Lambda y AWS CDK.
- GPT vs BERT ¿Cuál es mejor?
- Inmersión teórica profunda en la Regresión Lineal
- Conoce BITE Un Nuevo Método Que Reconstruye la Forma y Poses 3D de un Perro a Partir de una Imagen, Incluso con Poses Desafiantes como Sentado y Acostado.
- Conoce Paella Un Nuevo Modelo de IA Similar a Difusión que Puede Generar Imágenes de Alta Calidad Mucho Más Rápido que Usando Difusión Estable.
- Usando ChatGPT para Debugging Eficiente
- Científicos mejoran la detección de delirio utilizando Inteligencia Artificial y electroencefalogramas de respuesta rápida.