Revelando el poder del ajuste de sesgo mejorando la precisión predictiva en conjuntos de datos desequilibrados
Maximizando la precisión en conjuntos de datos desequilibrados mediante ajuste de sesgo
Abordar el desequilibrio de clases es crucial para predicciones precisas en la ciencia de datos. Este artículo presenta el Ajuste de Sesgo para mejorar la precisión del modelo en medio del desequilibrio de clases. Explora cómo el Ajuste de Sesgo optimiza las predicciones y supera este desafío.
Introducción
En el ámbito de la ciencia de datos, gestionar de manera efectiva conjuntos de datos desequilibrados es crucial para predicciones precisas. Los conjuntos de datos desequilibrados, caracterizados por disparidades significativas entre clases, pueden llevar a modelos sesgados que favorecen a la clase mayoritaria y ofrecen un rendimiento deficiente para la clase minoritaria, especialmente en contextos críticos como la detección de fraudes y el diagnóstico de enfermedades.
Este artículo presenta un remedio pragmático conocido como Ajuste de Sesgo. Al ajustar el término de sesgo dentro del modelo, contrarresta el desequilibrio de clases, fortaleciendo la capacidad del modelo para hacer predicciones precisas tanto en las clases mayoritarias como en las minoritarias. El artículo describe algoritmos para la clasificación binaria y multiclase, seguido de una exploración de sus principios subyacentes. Especialmente, la sección de Explicación del Algoritmo y Principios Subyacentes establece rigurosamente un vínculo teórico entre mi algoritmo, el sobremuestreo y la ajuste de pesos de clase, mejorando la comprensión del lector.
Para demostrar la eficacia y la justificación, se realiza un estudio de simulación que examina la relación entre el Ajuste de Sesgo y el sobremuestreo. Además, se emplea una aplicación práctica para ilustrar la implementación y los beneficios tangibles del Ajuste de Sesgo en la detección de fraudes con tarjetas de crédito.
- Adobe Express mejora la experiencia del usuario con Firefly Generative AI
- Redes convolucionales de grafos Introducción a las GNN
- Los Conjuntos de Estímulos Hacen que los LLMs Sean Más Confiables
El Ajuste de Sesgo ofrece una vía directa e impactante para mejorar los resultados del modelado predictivo frente al desequilibrio de clases. Este artículo proporciona una comprensión completa del mecanismo, los principios y las implicaciones del mundo real del Ajuste de Sesgo, convirtiéndolo en una herramienta invaluable para los científicos de datos que buscan mejorar el rendimiento del modelo en conjuntos de datos desequilibrados.
Algoritmo
El algoritmo de Ajuste de Sesgo presenta una metodología para abordar el desequilibrio de clases en tareas de clasificación binaria y multiclase. Al recalibrar el término de sesgo en cada época, el algoritmo mejora la capacidad del modelo para manejar conjuntos de datos desequilibrados de manera efectiva. A través del ajuste del término de sesgo, el algoritmo sensibiliza el modelo ante instancias de clases minoritarias, mejorando así la precisión de la clasificación.
Modelo f(x) y su rol en las predicciones
En el núcleo de nuestro algoritmo de ajuste de sesgo se encuentra el concepto de f(x) —un factor crucial que guía nuestro enfoque para abordar el desequilibrio de clases. f(x) actúa como un enlace entre las características de entrada x y las predicciones finales. En la clasificación binaria, actúa como un mapeo que transforma las entradas en valores reales, alineados con la activación sigmoide para su interpretación como probabilidades. En la clasificación multiclase, f(x) se transforma en un conjunto de funciones, f_k(x), donde cada clase k tiene su propia función, trabajando en conjunto con la activación softmax. Esta distinción es fundamental en nuestro algoritmo de ajuste de sesgo, donde utilizamos f(x) para ajustar el(los) término(s) de sesgo y afinar la sensibilidad al desequilibrio de clases.
Breve descripción general del algoritmo
El concepto del algoritmo es sencillo: calcular el promedio de f_k(x) para cada clase k y representar este promedio como δk. Al restar δk de f_k(x), nos aseguramos de que el valor esperado de f_k(x) − δk sea 0 para cada clase k. En consecuencia, el modelo predice que cada clase tiene la misma probabilidad de ocurrir. Si bien esto brinda una visión concisa de la justificación del algoritmo, es importante destacar que este enfoque está respaldado por fundamentos teóricos y matemáticos, que se explorarán más adelante en las secciones siguientes de este artículo.
Algoritmo para clasificación binaria

Utilización para predicción: Para realizar predicciones, aplicar el último valor de δ calculado por el algoritmo. Este valor de δ refleja los ajustes acumulados realizados durante el entrenamiento y sirve como base para el término de sesgo final en la función de activación sigmoide durante la predicción.

Algoritmo para clasificación multiclase

Utilización para Predicción: La culminación del proceso de entrenamiento de nuestro algoritmo produce un elemento crucial: el último valor de δk calculado. Este valor de δk encapsula los ajustes acumulativos del término de sesgo que han sido meticulosamente orquestados durante el entrenamiento. Su importancia radica en su papel como parámetro fundamental para el término de sesgo final en la función de activación softmax durante la predicción.
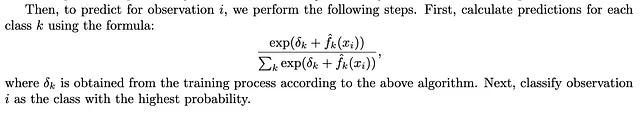
Explicación del Algoritmo y Principios Subyacentes
Desde el sobremuestreo hasta el ajuste del peso de clase, desde el ajuste del peso de clase hasta el nuevo algoritmo
En esta sección, nos embarcamos en una exploración de la Explicación del Algoritmo y los Principios Subyacentes. Nuestro objetivo es elucidar la mecánica y la fundamentación detrás de las operaciones del algoritmo, proporcionando información sobre su efectividad para abordar el desequilibrio de clase en tareas de clasificación.
Función de Pérdida y Desequilibrio
Comenzamos nuestro viaje adentrándonos en el corazón del algoritmo, la función de pérdida. Para nuestra exposición inicial, examinaremos la función de pérdida sin abordar directamente el problema del desequilibrio de clase. Consideremos un problema de clasificación binaria, donde la Clase 1 comprende el 90% de las observaciones y la Clase 0 constituye el 10% restante. Denotando el conjunto de observaciones de la Clase 1 como C1 y de la Clase 0 como C0, tomamos esto como nuestro punto de partida.
La función de pérdida, en ausencia de abordar el desequilibrio de clase, toma la siguiente forma:
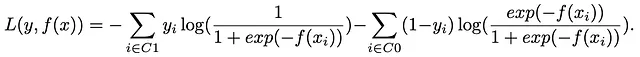
En la búsqueda de la estimación del modelo, nos esforzamos por minimizar esta función de pérdida:
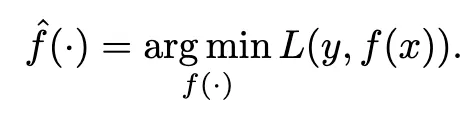
Mitigación del Desequilibrio: Sobremuestreo y Ajuste de Pesos de Clase
Sin embargo, la clave de nuestro esfuerzo radica en abordar el problema del desequilibrio de clase. Para superar este desafío, nos adentramos en el empleo de técnicas de sobremuestreo. Si bien existen diversos métodos de sobremuestreo, que abarcan desde el simple sobremuestreo hasta el sobremuestreo aleatorio, SMOTE y otros, nuestro enfoque, para mayor claridad presentacional, se limita al simple sobremuestreo, con un vistazo al sobremuestreo aleatorio.
Simple Sobremuestreo: Un enfoque fundamental en nuestro arsenal es el simple sobremuestreo, una técnica en la que duplicamos instancias de la clase minoritaria por un factor de ocho para igualar el tamaño de la clase mayoritaria. En nuestro ejemplo ilustrativo, donde la clase minoritaria constituye el 10% y la clase mayoritaria el 90% restante, duplicamos las observaciones de la clase minoritaria ocho veces, igualando efectivamente la distribución de clases. Denotando el conjunto de observaciones duplicadas como D0, este paso transforma nuestra función de pérdida de la siguiente manera:
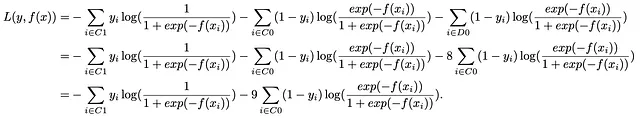
Esto revela una perspicaz idea: el principio fundamental del simple sobremuestreo se corresponde perfectamente con la noción de ajuste de pesos de clase. Duplicar la clase minoritaria ocho veces equivale efectivamente a aumentar el peso de la clase minoritaria en un factor de nueve. Significativamente, la técnica de sobremuestreo refleja el mecanismo de ajuste de pesos.
Sobremuestreo Aleatorio: Una breve contemplación sobre el sobremuestreo aleatorio resalta una observación paralela. El sobremuestreo aleatorio, al igual que su contraparte más simple, sirve como un equivalente al ajuste aleatorio de pesos de las observaciones.
Desde el Ajuste de Pesos de Clase hasta el Ajuste de Sesgo
Una revelación clave subraya el núcleo de nuestro enfoque: la equivalencia esencial entre el ajuste de sesgo, el sobremuestreo y el ajuste de pesos. Esta idea surge de
“Prentice y Pyke (1979) … han demostrado que, cuando el modelo contiene un término constante (intercepto) para cada categoría, estos términos constantes son los únicos coeficientes afectados por la probabilidad de selección desigual de Y” Scott & Wild (1986) [2]. Además, Manski y Lerman (1977) muestran el mismo resultado en un entorno softmax [1].
Desvelando la importancia: Traduciendo esta idea al ámbito del aprendizaje automático, el término constante (intercepto) es el término de sesgo. Esta observación fundamental revela que cuando recalibramos los pesos de clase o los pesos de observación, los cambios resultantes se manifiestan principalmente como ajustes al término de sesgo. En pocas palabras, el término de sesgo actúa como el elemento central que conecta nuestra estrategia para abordar el desequilibrio de clases.
Una Perspectiva Unificada
Esta comprensión proporciona una explicación clara de cómo nuestro algoritmo, el sobremuestreo y el ajuste de pesos son, en esencia, intercambiables y sustituibles. Esta unificación simplifica nuestro enfoque al tiempo que mantiene su eficacia para mitigar los desafíos del desequilibrio de clases.
Estudio de Simulación: Verificando la Influencia del Término de Sesgo a través del Sobremuestreo
Para solidificar nuestra afirmación de que el sobremuestreo afecta predominantemente al término de sesgo mientras mantiene intacto el núcleo funcional del modelo, nos adentramos en un estudio de simulación específico. Nuestro objetivo es demostrar empíricamente cómo las técnicas de sobremuestreo impactan únicamente en el término de sesgo, dejando inalterada la esencia del modelo.
La Configuración de la Simulación
Con este propósito ilustrativo, nos centramos en un escenario simplificado: regresión logística con una única característica. Nuestro modelo se define como:
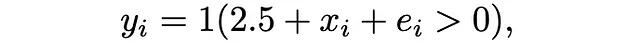
donde 1(.) denota la función indicadora, x_i se extrae de una distribución normal estándar y e_i sigue una distribución logística. En este contexto, establecemos f(x)=x.
Ejecutando la Simulación:
Utilizando esta configuración, examinamos meticulosamente el impacto de las técnicas de sobremuestreo en el término de sesgo, manteniendo constante el núcleo del modelo. Procedemos con tres métodos de sobremuestreo: sobremuestreo simple, SMOTE y muestreo aleatorio. Cada método se aplica meticulosamente y los resultados se registran cuidadosamente.
El fragmento de código Python a continuación describe el proceso de simulación:
# Cargar paquetesimport numpy as npimport statsmodels.api as smfrom imblearn.over_sampling import SMOTE, RandomOverSampler# Establecer semilla de aleatoriedadnp.random.seed(1)# Crear conjuntos de datos de simulaciónx = np.random.normal(size = 10000)y = (2.5 + x + np.random.logistic(size = 10000)) > 0# Se establece el término de sesgo en 2.5 y el coeficiente de x en 1# El tamaño de la clase 1 es 9005print(sum(y == 1))# El tamaño de la clase 0 es 995print(sum(y == 0))# Queremos igualar el tamaño de la clase 0 al de la clase 1# Método 0 No hacer nadax0 = xy0 = ymethod0 = sm.Logit(y0, sm.add_constant(x0)).fit()print(method0.summary()) # Término de sesgo de 2.54 y coeficiente de x3 de 0.97# Método 1 Sobremuestreo Simplex1 = np.concatenate((x, np.repeat(x[y == 0], 8)))y1 = np.concatenate((y, np.array([0] * (len(x1) - len(x)))))method1 = sm.Logit(y1, sm.add_constant(x1)).fit()print(method1.summary()) # Término de sesgo de 0.35 y coeficiente de x3 de 0.98# Método 2 SMOTEsmote = SMOTE(random_state = 1)x2, y2 = smote.fit_resample(x[:, np.newaxis], y)method2 = sm.Logit(y2, sm.add_constant(x2)).fit()print(method2.summary()) # Término de sesgo de 0.35 y coeficiente de x3 de 1# Método 3 Muestreo Aleatoriorandom_sampler = RandomOverSampler(random_state=1)x3, y3 = random_sampler.fit_resample(x[:, np.newaxis], y)method3 = sm.Logit(y3, sm.add_constant(x3)).fit()print(method3.summary()) # Término de sesgo de 0.35 y coeficiente de x3 de 0.99Resultados:
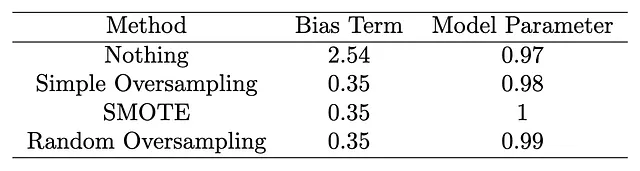
Observaciones Clave
Los resultados de nuestro estudio de simulación validan de manera concisa nuestra propuesta. A pesar de la aplicación de varios métodos de sobremuestreo, la función principal del modelo f(x)=x permanece inalterada. La idea crucial radica en la notable consistencia del componente del modelo en todas las técnicas de sobremuestreo. En cambio, el término de sesgo muestra variaciones notables, corroborando nuestra afirmación de que el sobremuestreo afecta principalmente al término de sesgo sin afectar la estructura subyacente del modelo.
Reforzando el Concepto Principal
Nuestro estudio de simulación subraya de manera innegable la equivalencia fundamental entre el sobremuestreo, el ajuste de peso y la modificación del término de sesgo. Al demostrar que el sobremuestreo altera exclusivamente el término de sesgo, fortalecemos el principio de que estas estrategias son herramientas intercambiables en el arsenal contra el desequilibrio de clases.
Aplicando el Algoritmo de Ajuste de Sesgo a la Detección de Fraude en Tarjetas de Crédito
Para demostrar la efectividad de nuestro algoritmo de ajuste de sesgo en abordar el desequilibrio de clases, utilizamos un conjunto de datos del mundo real de una competencia de Kaggle centrada en la detección de fraude en tarjetas de crédito. En este escenario, el desafío radica en predecir si una transacción con tarjeta de crédito es fraudulenta (etiquetada como 1) o no (etiquetada como 0), dada la rareza inherente de los casos de fraude.
Comenzamos cargando los paquetes esenciales y preparando el conjunto de datos:
import numpy as npimport pandas as pdimport tensorflow as tfimport tensorflow_addons as tfafrom sklearn.model_selection import train_test_splitfrom imblearn.over_sampling import SMOTE, RandomOverSampler# Cargar y preprocesar el conjunto de datosdf = pd.read_csv("/kaggle/input/playground-series-s3e4/train.csv")y, x = df.Class, df[df.columns[1:-1]]x = (x - x.min()) / (x.max() - x.min())x_train, x_valid, y_train, y_valid = train_test_split(x, y, test_size=0.3, random_state=1)batch_size = 256train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train)).shuffle(buffer_size=1024).batch(batch_size)valid_dataset = tf.data.Dataset.from_tensor_slices((x_valid, y_valid)).batch(batch_size)Luego definimos un modelo simple de aprendizaje profundo para clasificación binaria y configuramos el optimizador, la función de pérdida y la métrica de evaluación. Seguimos la evaluación de la competencia y elegimos el AUC como métrica de evaluación. Además, el modelo está simplificado intencionalmente ya que el enfoque de este artículo es mostrar cómo implementar el algoritmo de ajuste de sesgo, no destacar en la predicción:
model = tf.keras.Sequential([ tf.keras.layers.Normalization(), tf.keras.layers.Dense(32, activation='swish'), tf.keras.layers.Dense(32, activation='swish'), tf.keras.layers.Dense(1)])optimizer = tf.keras.optimizers.Adam()loss = tf.keras.losses.BinaryCrossentropy()val_metric = tf.keras.metrics.AUC()Dentro del núcleo de nuestro algoritmo de ajuste de sesgo se encuentran los pasos de entrenamiento y validación, donde abordamos meticulosamente el desequilibrio de clases. Para elucidar este proceso, indagamos en los mecanismos intrincados que equilibran las predicciones del modelo.
Paso de Entrenamiento con Acumulación de Valores Delta
En el paso de entrenamiento, nos embarcamos en el viaje de mejorar la sensibilidad del modelo al desequilibrio de clases. Aquí, calculamos y acumulamos la suma de las salidas del modelo para dos grupos distintos: delta0 y delta1. Estos grupos tienen una importancia significativa, ya que representan los valores predichos asociados a las clases 0 y 1, respectivamente.
# Definir la función del Paso de [email protected] train_step(x, y): delta0, delta1 = tf.constant(0, dtype = tf.float32), tf.constant(0, dtype = tf.float32) with tf.GradientTape() as tape: logits = model(x, training=True) y_pred = tf.keras.activations.sigmoid(logits) loss_value = loss(y, y_pred) # Calcular el nuevo término de sesgo para abordar el desequilibrio de clases if len(logits[y == 1]) == 0: delta0 -= (tf.reduce_sum(logits[y == 0])) elif len(logits[y == 0]) == 0: delta1 -= (tf.reduce_sum(logits[y == 1])) else: delta0 -= (tf.reduce_sum(logits[y == 0])) delta1 -= (tf.reduce_sum(logits[y == 1])) grads = tape.gradient(loss_value, model.trainable_weights) optimizer.apply_gradients(zip(grads, model.trainable_weights)) return loss_value, delta0, delta1Paso de validación: Resolución de desequilibrio con Delta
Los valores de delta normalizados, derivados del proceso de entrenamiento, toman protagonismo en el paso de validación. Armados con estos refinados indicadores de desequilibrio de clases, alineamos las predicciones del modelo de manera más precisa con la verdadera distribución de clases. La función test_step integra estos valores de delta para ajustar de forma adaptativa las predicciones, lo que finalmente lleva a una evaluación refinada.
@tf.functiondef test_step(x, y, delta): logits = model(x, training=False) y_pred = tf.keras.activations.sigmoid(logits + delta) # Ajustar las predicciones con delta val_metric.update_state(y, y_pred)Utilizando los valores de delta para la corrección del desequilibrio
A medida que avanza el entrenamiento, recopilamos conocimientos valiosos encapsulados en las sumas acumulativas de los clústeres delta0 y delta1. Estos valores acumulativos emergen como indicadores del sesgo inherente en las predicciones de nuestro modelo. Al finalizar cada época, llevamos a cabo una transformación vital. Dividiendo las sumas acumuladas de los clústeres por el número correspondiente de observaciones de cada clase, obtenemos valores de delta normalizados. Esta normalización actúa como un igualador crucial, encapsulando la esencia de nuestro enfoque de ajuste de sesgo.
E = 1000P = 10B = len(train_dataset)N_class0, N_class1 = sum(y_train == 0), sum(y_train == 1)early_stopping_patience = 0best_metric = 0for epoch in range(E): # inicializar delta delta0, delta1 = tf.constant(0, dtype = tf.float32), tf.constant(0, dtype = tf.float32) print("\nInicio de la época %d" % (epoch,)) # Iterar sobre los lotes del conjunto de datos. for step, (x_batch_train, y_batch_train) in enumerate(train_dataset): loss_value, step_delta0, step_delta1 = train_step(x_batch_train, y_batch_train) # Actualizar delta delta0 += step_delta0 delta1 += step_delta1 # Calcular el promedio de todos los valores de delta delta = (delta0/N_class0 + delta1/N_class1)/2 # Ejecutar un bucle de validación al final de cada época. for x_batch_val, y_batch_val in valid_dataset: test_step(x_batch_val, y_batch_val, delta) val_auc = val_metric.result() val_metric.reset_states() print("AUC de validación: %.4f" % (float(val_auc),)) if val_auc > best_metric: best_metric = val_auc early_stopping_patience = 0 else: early_stopping_patience += 1 if early_stopping_patience > P: print("Alcanzada la paciencia de detención temprana. Entrenamiento finalizado con AUC de validación: %.4f" % (float(best_metric),)) break;El resultado
En nuestra aplicación de detección de fraudes en tarjetas de crédito, la eficacia mejorada de nuestro algoritmo brilla. Con el ajuste de sesgo integrado de manera transparente en el proceso de entrenamiento, logramos una impresionante puntuación de AUC de 0.77. Esto contrasta claramente con la puntuación de AUC de 0.71 obtenida sin la guía del ajuste de sesgo. La mejora significativa en el rendimiento predictivo es un testimonio de la capacidad del algoritmo para navegar por las complejidades del desequilibrio de clases, trazando un camino hacia predicciones más precisas y confiables.
Referencias
[1] Manski, C. F., & Lerman, S. R. (1977). La estimación de las probabilidades de elección a partir de muestras basadas en elecciones. Econometrica: Journal of the Econometric Society, 1977–1988.
[2] Scott, A. J., & Wild, C. J. (1986). Ajuste de modelos logísticos bajo muestreo basado en casos o elecciones. Journal of the Royal Statistical Society Series B: Statistical Methodology, 48(2), 170–182.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Difusión Estable El AI de la Comunidad
- Cómo utilizar ChatGPT para convertir texto en una presentación de PowerPoint
- Aprovechando los LLM con Recuperación de Información Una Demostración Simple
- Cómo acelerar la inferencia hasta 9 veces en una CPU x86 con Pytorch
- Dentro de XGen-Imagen-1 Cómo Salesforce Research construyó, entrenó y evaluó un modelo masivo de texto a imagen.
- Anthropic recibe un impulso de $100 millones de SK Telecom para avanzar en la IA específica de las telecomunicaciones
- Bases de datos de vectores y índices de vectores en Python Arquitectura de aplicaciones LLM





