Investigadores del Max Plank proponen MIME un modelo de IA generativo que toma capturas de movimiento humano en 3D y genera escenas en 3D plausibles que son consistentes con el movimiento.
Max Plank researchers propose MIME, a generative AI model that takes 3D human motion captures and generates plausible 3D scenes consistent with the motion.


Los seres humanos siempre están interactuando con su entorno. Se mueven por un espacio, tocan cosas, se sientan en sillas o duermen en camas. Estas interacciones detallan cómo se configura la escena y dónde están los objetos. Un mimo es un artista que utiliza su comprensión de estas relaciones para crear un entorno imaginativo en 3D con nada más que los movimientos de su cuerpo. ¿Pueden enseñar a una computadora a imitar las acciones humanas y crear la escena 3D adecuada? Numerosos campos, como la arquitectura, los videojuegos, la realidad virtual y la síntesis de datos sintéticos, podrían beneficiarse de esta técnica. Por ejemplo, existen conjuntos de datos sustanciales de movimiento humano en 3D, como AMASS, pero estos conjuntos de datos rara vez incluyen detalles sobre el entorno 3D en el que se recopilaron.
¿Podrían crear escenarios 3D creíbles para todos los movimientos utilizando AMASS? Si es así, podrían crear datos de entrenamiento con interacción humano-escena realista utilizando AMASS. Desarrollaron una técnica novedosa llamada MIME (Mining Interaction and Movement to infer 3D Environments), que crea escenarios 3D interiores creíbles basados en el movimiento humano en 3D para responder a estas preguntas. ¿Qué lo hace posible? Las suposiciones fundamentales son las siguientes: (1) El movimiento humano a través del espacio denota la ausencia de objetos, definiendo esencialmente áreas de la imagen desprovistas de muebles. Además, esto limita el tipo y la ubicación de objetos 3D cuando se está en contacto con la escena; por ejemplo, una persona sentada debe estar sentada en una silla, sofá, cama, etc.
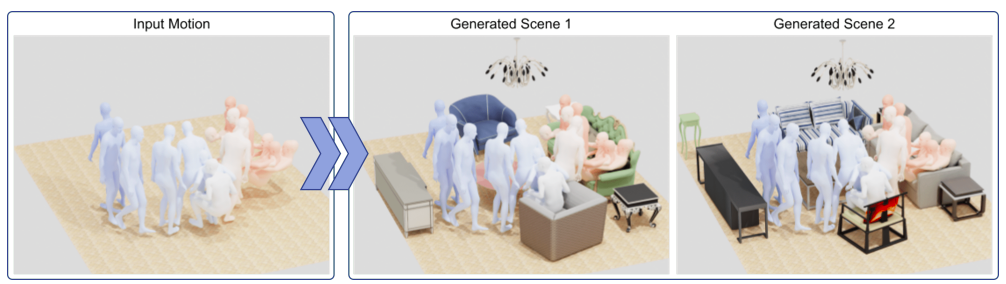
Investigadores del Instituto Max Planck para Sistemas Inteligentes en Alemania y Adobe crearon MIME, una técnica de generación de escenas 3D auto-regresiva basada en transformadores, para dar una forma tangible a estas intuiciones. Dado un plano de planta vacío y una secuencia de movimiento humano, MIME predice los muebles que entrarán en contacto con el ser humano. Además, prevé objetos creíbles que no entran en contacto con las personas pero encajan con otros objetos y se adhieren a las restricciones de espacio libre impuestas por los movimientos de las personas. Dividen el movimiento en fragmentos de contacto y no contacto para condicionar la creación de la escena 3D para el movimiento humano. Estiman las posturas de contacto potenciales utilizando POSA. Las posturas no contacto proyectan los vértices del pie sobre el plano del suelo para establecer el espacio libre de la habitación, que registran como mapas de piso 2D.
- Investigadores de inteligencia artificial de Salesforce presentan OVIS sin máscaras un generador de máscaras de segmentación de instancia de vocabulario abierto.
- Cómo rejuvenecer usando IA Descubierto nuevo medicamento contra el envejecimiento.
- Investigadores de UC San Diego y Qualcomm lanzan Natural Program una herramienta poderosa para la verificación sin esfuerzo de cadenas de razonamiento rigurosas en lenguaje natural – Un cambio de juego en inteligencia artificial.
Los vértices de contacto predichos por POSA crean cajas delimitadoras en 3D que reflejan las posturas de contacto y los modelos de cuerpo humano en 3D asociados. Los objetos que satisfacen los criterios de contacto y espacio libre se esperan autoregresivamente para utilizar estos datos como entrada al transformador; ver Fig. 1. Ampliaron el conjunto de datos sintéticos de escenarios a gran escala 3D-FRONT para crear un nuevo conjunto de datos llamado 3D-FRONT HUMAN para entrenar a MIME. Añaden automáticamente personas a los escenarios 3D, incluyendo personas no contacto (una serie de movimientos de caminar y personas de pie) y personas de contacto (personas sentadas, tocando y acostadas). Para ello, utilizan posturas de contacto estáticas de escaneos de RenderPeople y secuencias de movimiento de AMASS.
MIME crea un diseño de escena 3D realista para el movimiento de entrada en tiempo de inferencia, representado como cajas delimitadoras en 3D. Eligen modelos 3D de la colección 3D-FUTURE en función de esta disposición; luego, ajustan finamente su colocación en 3D en función de las restricciones geométricas entre las posiciones humanas y la escena. Su método produce un conjunto 3D que admite el tacto y el movimiento humano al colocar objetos convincentes en el espacio libre, a diferencia de los sistemas de creación de escenas 3D puros como ATISS. Su enfoque permite el desarrollo de objetos que no están en contacto con la persona, anticipando la escena completa en lugar de objetos individuales, a diferencia de Pose2Room, un modelo generativo condicionado por pose reciente. Demuestran que su enfoque funciona sin ajustes en secuencias de movimiento genuinas que se han grabado, como PROX-D.
En conclusión, contribuyen lo siguiente:
• Un nuevo modelo generativo condicionado por movimiento para escenas de habitaciones en 3D que crea auto-regresivamente objetos que entran en contacto con las personas mientras evita ocupar espacios vacíos definidos por el movimiento.
• Se creó un nuevo conjunto de datos de escenas en 3D compuesto por personas interactuando y personas en espacios libres, llenando 3D FRONT con datos de movimiento de AMASS y poses estáticas de contacto/parado de RenderPeople.
El código está disponible en GitHub junto con una demostración en video. También tienen una explicación en video de su enfoque.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Revolutionizando la Navegación Investigadores del MIT Presentan un Nuevo Enfoque de Aprendizaje Automático para la Estabilización y Evitación de Obstáculos en Vehículos Autónomos.
- NVIDIA Research gana el desafío de conducción autónoma y el premio a la innovación en CVPR.
- Generación de columnas en programación lineal y el problema de corte de stock.
- Sensor de alcohol móvil para la muñeca podría impulsar la investigación sobre el consumo de alcohol.
- Una forma más efectiva de entrenar máquinas para situaciones inciertas del mundo real.
- NYU y NVIDIA colaboran en un gran modelo de lenguaje para predecir la readmisión de pacientes.
- Imágenes detalladas desde el espacio ofrecen una imagen más clara de los efectos de la sequía en las plantas.





