Más allá del VIF Análisis de la Colinealidad para Mitigación del Sesgo y Precisión Predictiva
Más allá del VIF Análisis de colinealidad para mitigar sesgo y mejorar precisión predictiva
En el aprendizaje automático, la colinealidad es un rompecabezas complejo tanto para profesionales experimentados como para principiantes. Los algoritmos de aprendizaje automático (ML) están optimizados para la precisión predictiva, no para la explicabilidad de los predictores en el objetivo. Además, la mayoría de las soluciones para abordar la colinealidad, como el ‘Puntaje de Inflación de Varianza’ y el ‘Análisis de correlación cruzada de Pearson’, pueden llevar a una pérdida masiva de información en el preprocesamiento.
La mayoría de los algoritmos de aprendizaje automático seleccionarán la mejor combinación posible de características para optimizar la precisión predictiva. Por lo tanto, incluso con colinealidad, siempre que las correlaciones observadas en el entrenamiento sigan siendo verdaderas en el mundo real, la colinealidad no es un problema en el aprendizaje automático. Sin embargo, para la explicabilidad de un modelo, los efectos no controlados de la colinealidad son una fuente potencial de sesgo.
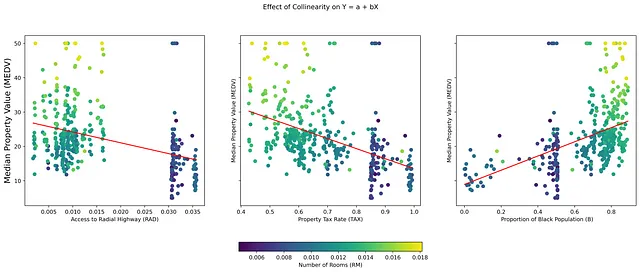
Colinealidad, que se refiere a una alta correlación entre variables independientes (IVs) en un conjunto de datos, a menudo presenta desafíos únicos en la interpretación de modelos de regresión. En particular, interfiere con la determinación de las verdaderas razones de las relaciones en los datos, lo que puede llevar a interpretaciones sesgadas y decisiones injustas. Por ejemplo, en la figura 1, las variables independientes (TAX), (B) y (RAD) son IVs colineales y también buenos predictores de la variable dependiente (MEDV). Si bien los algoritmos de ML seleccionarán la mejor combinación de predictores, pueden no tener en cuenta el efecto de agregar otra variable colineal (RM) a un modelo con cualquiera de estas tres variables.
Para fomentar que los aprendices de máquina tomen en serio el análisis de colinealidad como un paso de preprocesamiento, debe haber una forma de equilibrar el costo inflacionario de mantener variables colineales y el costo predictivo de eliminarlas.
- Ajuste fino de un modelo Llama-2 7B para la generación de código en Python
- Una Guía Completa para MLOps
- Tendencias principales de IA en marketing para observar en 2023
Comprendiendo la colinealidad
Para demostrar cómo la colinealidad no controlada conduce a sesgos no deseados, usemos la historia de advertencia de “Cómo no recopilar datos”: el conjunto de datos de viviendas de Boston. Este conjunto de datos ha sido desacreditado y retirado del uso público porque contiene una variable “B” “no invertible”. La relación colineal entre las variables independientes “B”, “RM” y “TAX” es un caso de estudio perfecto de cómo las correlaciones espurias pueden suprimir las verdaderas relaciones entre las IVs. La transformación “no invertible” en “B” (una IV binaria disfrazada de IV continua) introduce un sesgo moderador que puede no ser detectado por los algoritmos de ML.
Considera las 13 variables independientes (IVs) en el conjunto de datos de viviendas de Boston, con el valor mediano de las viviendas ocupadas por sus propietarios (MEDV) en una ciudad como la variable dependiente (DV). Ciertas características pueden parecer fuertes predictores del resultado, pero esta influencia radica en que su varianza está explicada en gran medida por otros predictores.
En una relación bivariada entre una variable independiente y una variable dependiente, hay una de cuatro posibilidades cuando se introduce una nueva variable independiente:
- Inflación espuria: La inclusión de la tercera IV aumenta significativamente la influencia de la primera IV en la DV.
- Mascarar o suprimir: La nueva IV oculta o suprime la influencia de la IV inicial en la variable dependiente.
- Modera o altera: La nueva variable cambia la dirección de la relación original para todas o algunas observaciones en la variable independiente.
- Sin efecto: La tercera IV no proporciona información nueva y no tiene efecto en la IV y la DV.
Para los aprendices de máquina, las soluciones predefinidas a la colinealidad a menudo resultan en pérdida de poder predictivo, modelos sobreajustados y sesgo. Por lo tanto, una solución que mitigue la pérdida de información es crucial.
Evaluando la Colinealidad
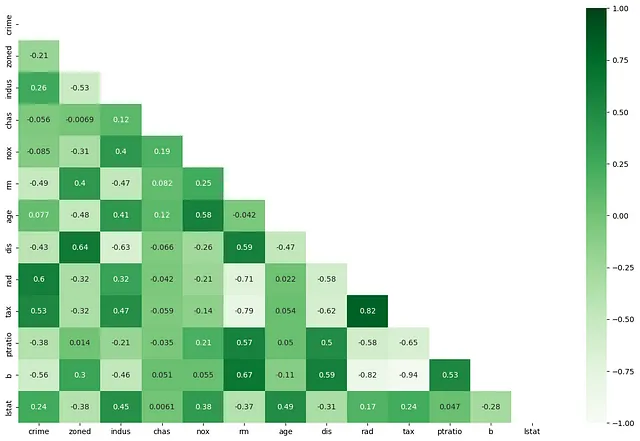
Si dos o más variables independientes están altamente correlacionadas (RAD y TAX), la intuición detrás de la colinealidad es que potencialmente proporcionan exactamente la misma información sobre la influencia de algún concepto “latente” (casas grandes en suburbios / apartamentos en la ciudad) en la variable dependiente (Valor de la Propiedad). En presencia de “Impuesto a la Propiedad”, la accesibilidad a las autopistas radiales no proporciona información nueva sobre el valor de la propiedad (o viceversa). Cuando las variables independientes están correlacionadas de manera significativa pero sin sentido, los coeficientes de un modelo de regresión se vuelven grandes, lo que a su vez conduce a inferencias sobreestimadas sobre los efectos de algunos factores en un resultado.
Actualmente, existen dos formas de lidiar con la colinealidad, ninguna de las cuales tiene en cuenta la variable dependiente.
- Correlación de pares: Cuántas variables independientes están “altamente” correlacionadas entre sí. El umbral para el coeficiente de correlación de características “altamente correlacionadas” es subjetivo. Sin embargo, existe un consenso general de que la colinealidad se convierte en un problema serio a un coeficiente de correlación de +/- 0,7.
def dropMultiCorrelated(cormat, threshold): ##Define threshold to remove pairs of features with #correlation coefficient greater than 0.7 or -0.7 threshold = 0.7 # Select upper triangle of correlation matrix upper = cormat.abs().where(np.triu(np.ones(cormat.shape), k=1).astype(np.bool)) # Find index of feature columns with correlation greater than threshold to_drop = [column for column in upper.columns if any(upper[column] > threshold)] for d in to_drop: print("Eliminando {}....".format(d)) return to_drop2. Inflación de Varianza: Si bien un coeficiente de correlación confirma un grado de cambio correspondiente entre dos variables independientes, nos dice poco acerca de la importancia de las variables independientes. Esto se debe a que las variables independientes, en una relación multivariante, no son verdaderamente independientes en su influencia en la variable dependiente (ver Figura 1) y la verdadera significancia de su influencia está en presencia de una combinación de otras variables independientes.
La puntuación de inflación de varianza es el tamaño de la influencia agregada a los coeficientes de las variables independientes debido a su dependencia de otras variables independientes. El VIF utiliza un enfoque de ‘dejar uno fuera’ en las variables independientes, tratando cada ‘dejar fuera’ como una variable dependiente y todas las ‘dejar dentro’ como variables independientes. Por lo tanto, todas las variables independientes se convierten en variables dependientes y cada modelo produce un valor de (R2). Este valor de R2 indica el porcentaje de varianza en la variable independiente ‘dejada fuera’ explicada por las variables independientes ‘dejadas dentro’. La puntuación de VIF se estima de la siguiente manera:
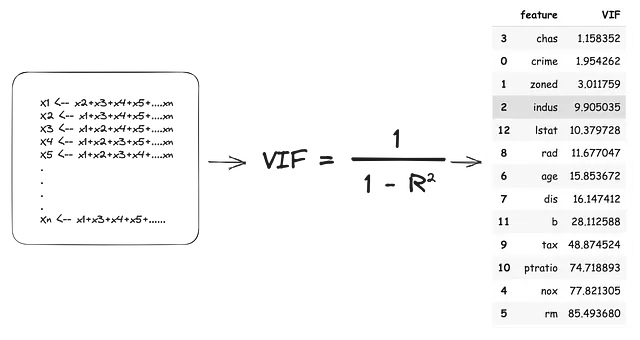
De acuerdo con las estimaciones de VIF anteriores, tendríamos que eliminar 11 de las 13 variables independientes para abordar completamente la colinealidad. Esto no solo llevaría a una pérdida masiva de información, sino que también podría generar modelos sobreajustados que funcionen mal en el mundo real.
En el aprendizaje automático, los puntajes de correlación múltiple entre pares y VIF no deben ser los únicos criterios para descartar o retener características.
Ciertas características aún pueden ofrecer un valor predictivo significativo o contribuir a la interpretación del modelo a pesar de una alta correlación y puntajes de VIF.
Costos Inflacionarios VS Predictivos para la Selección de Características Colineales
Para mitigar la pérdida de información, podemos comparar dos valores para medir el costo inflacionario de mantener características colineales y el costo predictivo de eliminarlas. Tenga en cuenta que el análisis de VIF se realiza de forma independiente de la variable de resultado, por lo que no tiene en cuenta completamente la influencia independiente de las variables independientes en la variable dependiente.
## Construye modelos de regresión lineal múltiple para evaluar la verdadera influencia independiente en el resultado
fs = []
for feature in X_train.columns:
model = sm.OLS(Y_train, sm.add_constant(X_train[feature])).fit()
fs.append((feature, model.params[feature]/ model.pvalues[feature]))
## Extrae y guarda los valores
c1 = pd.DataFrame(coefs, columns = ['Característica', 'VarianceEx']).sort_values("VarianceEx")
La primera medida es la influencia independiente de una variable independiente (IV) en la variable dependiente, es decir, la cantidad de varianza en la variable dependiente explicada independientemente por la IV (R_cuadrado). Para mayor consistencia, también estimaremos el puntaje VIF a partir de este valor de R_cuadrado y lo llamaremos VIF(IY) – Importancia Independiente. La segunda medida es la influencia de la variable independiente en la variable dependiente en presencia de todas las IV, es decir, el VIF estimado anteriormente. Llamaremos a esto VIF(IX) – Importancia Colectiva.
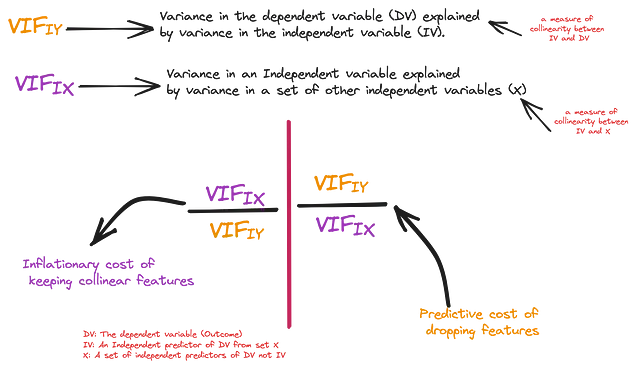
Ahora podemos estimar de manera confiable la verdadera cantidad de ‘sorpresa’ que estás dejando al eliminar una característica colineal. En el gráfico a continuación, el eje X representa la varianza en Y explicada por cada IV (una medida de ‘utilidad’ potencial para la predicción), mientras que el eje Y representa la varianza en la IV explicada por otras IV (una medida de ‘sesgo’ potencial para el modelo). El tamaño de la burbuja en el subgráfico 1 es el costo inflacionario de mantener estas variables en el modelo y en el subgráfico 2 es el costo predictivo de eliminarlas.
Dado que este es un paso de preprocesamiento, usemos límites muy amplios para el factor VIF(IX) de 20 (la línea roja) y VIF(IY) de 1.15 (la línea azul). De esta manera, las características por debajo de la línea roja están menos explicadas por otras IV y las características detrás de la línea azul no pueden predecir de forma independiente (Y).
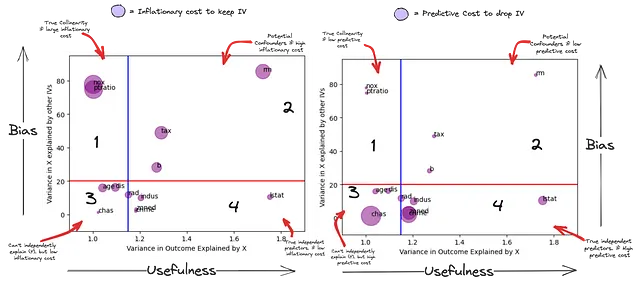
Este gráfico resume el poder predictivo independiente de una IV VS su potencial de sesgo.
- Cuadrante 1 – Colineales Potencialmente Verdaderos: Estas características (NOX, PTRATIO) están explicadas por alguna combinación lineal de IV en el modelo y no pueden predecir de forma independiente la variable dependiente (pueden depender de algún otro conjunto de IV para ser útiles). Además, cualquier poder predictivo que tengan puede ser cancelado por alguna combinación lineal de otras IV (subgráfico 2). Su influencia se ve significativamente suprimida por la adición de alguna otra IV(s).
- Cuadrante 2 – Sesgadores Potenciales: Estos están relacionados tanto con la variable dependiente como con otras variables independientes. Las características (RM, TAX, B) parecen ser predictivas de forma independiente de (Y), pero su varianza también está explicada por alguna otra combinación de variables independientes. Su supuesto poder predictivo independiente sobre (Y) no puede considerarse de forma aislada respecto a otras (IVs). Pueden ser predictores extremadamente poderosos del resultado o convertirse en una fuente de sesgo al interpretar su significancia para el resultado.
- Cuadrante 3 – Dependientes: Aunque no son predictivas de forma independiente de (Y), hay un alto costo predictivo al eliminar algunas de ellas. Esto se debe a que tienen información única que no está explicada por ninguna otra IV. La utilidad de esta información “única” para predecir (Y) solo se puede considerar en combinación con otras IV(s).
- Cuadrante 4 – Verdaderos Predictores Independientes: Estas variables son predictivas de forma independiente de (Y). Estas variables también tienen información única que no está explicada por ninguna otra IV (más que en el Cuadrante 3). La utilidad de esta información “única” para predecir (Y) es independiente de otras IV(s). Sin embargo, una combinación lineal de otras IVs puede tener un poder predictivo mayor que su poder predictivo independiente.
O = Y_train# Para estimar el efecto de la adición/eliminación de una característica C en la relación entre una característica independiente I y un resultado Oconf = []
for I in X_train.columns:
# Construye un modelo base para el efecto de I en O
model = sm.OLS(O, sm.add_constant(X_train[I])).fit()
IO_coef, IO_sig = model.params[I], model.pvalues[I]
## Accede al efecto de C
for C in X_train.columns:
if C != I:
# Construye un modelo auxiliar agregando C a la relación entre I y O
model2 = sm.OLS(O, sm.add_constant(X_train[[I, C]])).fit()
ico_preds = model2.predict()
ICO_coef, ICO_sig = model2.params[I], model2.pvalues[I]
# Construye un modelo base para el efecto de C en O
model3 = sm.OLS(O, sm.add_constant(X_train[C])).fit()
CO_coef, CO_sig = model3.params[C], model3.pvalues[C]
corr_IC, _ = pearsonr(X_train[I], X_train[C]) # CORR La independiente vs. el control
corr_IO, _ = pearsonr(X_train[I], O) # CORR La independiente vs. el resultado
corr_CO, _ = pearsonr(X_train[C], O) # CORR El control vs. el resultado
conf.append({"I_C":f"{I}_{C}",
"IO_coef":IO_coef, "IO_sig":IO_sig,
"CO_coef":CO_coef, "CO_sig":CO_sig,
"ICO_sig":ICO_sig, "ICO_coef": ICO_coef,
"corr_IC":corr_IC,
"corr_IO":corr_IO,
"corr_CO":corr_CO})
cc = pd.DataFrame(conf)
corr_ic = (cc['corr_IC'] > 0.5) | (cc['corr_IC'] < -0.5) # I está correlacionada con C
corr_co = (cc['corr_CO'] > 0.5) | (cc['corr_CO'] < -0.5) # C está correlacionada con O
corr_io = (cc['corr_IO'] > 0.5) | (cc['corr_IO'] < -0.5) # C está correlacionada con O
## C y O están correlacionadas de forma significativa
co_sig = (cc['CO_sig'] < 0.01) # C es predictiva de forma independiente de O
io_sig = (cc['IO_sig'] < 0.01)
cc[corr_ic & corr_io & corr_co & co_sig & io_sig]Las variables B, TAX y RM predicen significativamente entre sí y también predicen de forma independiente el resultado. Esto podría ser la combinación lineal de las variables independientes que mejor predicen la variable dependiente (MEDV). Alternativamente, la relevancia predictiva de cualquiera de estas dos variables independientes podría estar inflada o suprimida debido a la presencia de la tercera variable independiente. Para investigar esto, cada variable debería ser eliminada secuencialmente de un modelo base que comprenda todas las variables independientes.
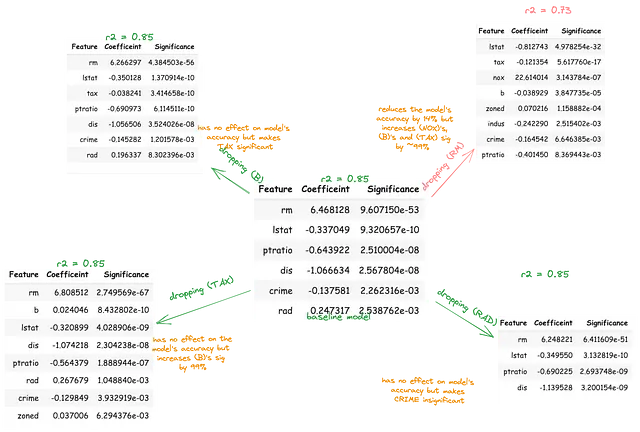
Posteriormente, el cambio correspondiente en la significancia de las variables restantes en el resultado debería ser cuantificado en términos de porcentaje. Este procedimiento ayudará a exponer las variables independientes explicadas por otras variables independientes, que fingen ser importantes.
Por encima de la línea roja, eliminando el sesgo colineal
Existen tres efectos principales (de preocupación) que las variables colineales por encima de la línea roja pueden tener en la relación entre otras variables independientes y la variable dependiente. Pueden mediar (suprimir), confundir (exagerar) o moderar (cambiar).
Los conceptos de moderadores, mediadores y confundidores realmente no se discuten en el Aprendizaje Automático. Estos conceptos suelen dejarse a los “científicos sociales”, después de todo, son ellos quienes necesitan “interpretar” sus coeficientes. Sin embargo, estos conceptos explican cómo la colinealidad puede introducir sesgo en los modelos de IA.
Tenga en cuenta que estos efectos no se pueden establecer realmente sin un análisis causal más profundo, pero para un paso de preprocesamiento de eliminación de sesgo, podemos usar definiciones simples de estos conceptos para filtrar estas relaciones.
Un mediador explica “cómo” están relacionadas la variable independiente y la variable dependiente, es decir, el proceso mediante el cual están relacionadas. Un mediador debe cumplir tres criterios:
a) Ser significativamente predictivo de la primera variable independiente, b) ser significativamente predictivo de la variable dependiente y c) ser significativamente predictivo de la variable dependiente en presencia de la primera variable independiente.
Actúa como “mediador” porque su inclusión no cambia la dirección de la relación entre la primera variable independiente y la variable dependiente. Si se elimina un mediador de un modelo, la fuerza de la relación entre la primera variable independiente y la variable dependiente debería volverse más fuerte porque el mediador realmente estaba explicando parte de ese efecto.
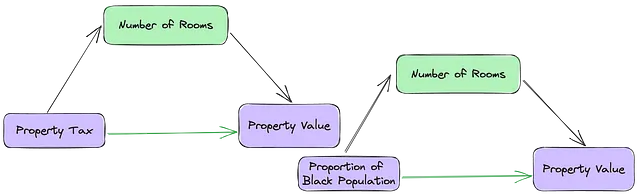
## finding mediatorscc = pd.DataFrame(conf)co_sig = (cc['CO_sig'] < 0.01) # La C predice de forma independiente a Yio_sig = (cc['IO_sig'] < 0.01) # La I predice de forma independiente a Yicoi_sig = (cc['ICO_I_sig'] < 0.01) # La I y la C predicen a Yicoc_sig = (cc['ICO_C_sig'] < 0.05) # La C predice de forma independiente a Y en presencia de Iicoci_sig = (cc['IO_sig'] > cc['ICO_I_sig']) # La relación directa entre I y O debería ser más fuerte sin CPor ejemplo, en la relación entre (RM), (TAX) y (MEDV), el número de habitaciones potencialmente explica cómo el impuesto a la propiedad está relacionado con el valor de la propiedad.
Los confundidores son escurridizos, ya que es difícil definirlos en términos de correlaciones y significancia. Una variable confundidora es una variable externa que se correlaciona tanto con la variable dependiente como con las variables independientes, lo que potencialmente distorsiona la relación percibida entre ellas. A diferencia de los mediadores, la relación entre la primera variable independiente y la variable dependiente no tiene sentido. Tampoco hay garantía de que eliminar el confundidor debilite o fortalezca la relación entre la primera variable independiente y la variable dependiente.
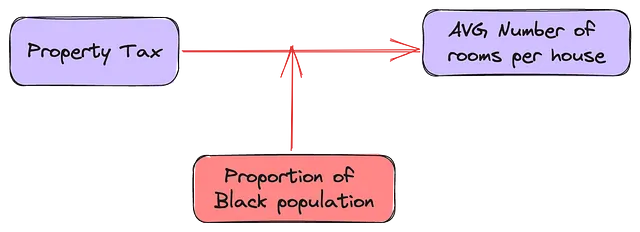
El número de habitaciones en una casa puede tanto mediar como confundir la relación entre la proporción de población negra y el valor de la propiedad. Bueno, según este artículo, esto depende de la relación entre (B) y (RM). Si la relación entre (RM <-> MEDV) y (RM <-> B) es en la misma dirección, eliminar (RM) debilitaría el efecto de (B) en (MEDV). Sin embargo, si la relación entre (RM <-> MEDV) y (RM <-> B) es en dirección opuesta, eliminar (RM) fortalecería (B).
(RM <—> MEDV) y (RM <-> B) están en la misma dirección (subgráfico 3 de la figura 1), sin embargo, al eliminar (RM) se refuerza el efecto de (B).
Pero vea la figura a continuación, donde hay un buen límite de decisión para una tercera VI en la relación entre la primera VI y la DV. Esto indica un tipo diferente de relación entre (RM) y (TAX) basado en el valor de (B).
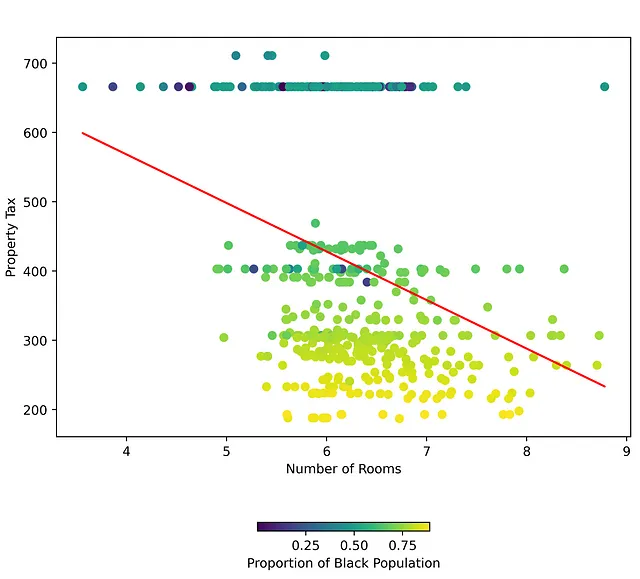
Con moderadores, la relación entre la primera VI y la variable dependiente es diferente según el valor del moderador. ¿Qué impuesto a la propiedad puede esperar pagar en una casa que cuesta $100,00? Bueno, depende de la proporción de población negra en la ciudad y el número de habitaciones en esa casa. De hecho, hay un conjunto de ciudades cuyo impuesto a la propiedad se mantiene constante, independientemente del número de habitaciones, siempre que (B) permanezca por debajo de un cierto umbral.
Los moderadores suelen ser características categóricas o grupos en los datos. Los pasos convencionales de preprocesamiento para los grupos crean variables ficticias para cada etiqueta de grupo. Esto aborda potencialmente cualquier efecto moderador de ese grupo en la variable dependiente. Sin embargo, las variables clasificadas o variables continuas con baja varianza (B) también pueden ser moderadores.
Conclusión
En conclusión, si bien la colinealidad es un problema desafiante en la modelización de regresión, su evaluación y gestión cuidadosas pueden mejorar el poder predictivo y la confiabilidad de los modelos de aprendizaje automático. La capacidad para tener en cuenta la pérdida de información proporciona un marco efectivo para la selección de características, permitiendo equilibrar la explicabilidad y la precisión predictiva.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Mejores Servidores Proxy 2023
- Clave maestra para la separación de fuentes de audio Presentamos AudioSep para separar cualquier cosa que describas
- 5 Cosas que Necesitas Saber al Construir Aplicaciones de Aprendizaje Automático
- Investigadores de la Universidad de Boston lanzan la familia Platypus de LLMs afinados para lograr un refinamiento económico, rápido y potente de los LLMs base.
- IBM y NASA se unen para crear Earth Science GPT Descifrando los misterios de nuestro planeta
- Reconocimiento del lenguaje hablado en Mozilla Common Voice Transformaciones de audio.
- Conoce a PUG una nueva investigación de IA de Meta AI sobre conjuntos de datos fotorrealistas y semánticamente controlables utilizando Unreal Engine para una evaluación de modelos robusta






