Gestionando los costos de almacenamiento en la nube de aplicaciones de Big Data
Managing cloud storage costs for Big Data applications.
Consejos para reducir el gasto en el uso de almacenamiento basado en la nube

Con la creciente dependencia de cantidades cada vez mayores de datos, las empresas modernas dependen más que nunca de soluciones de almacenamiento de datos de alta capacidad y altamente escalables. Para muchas empresas, esta solución se presenta en forma de servicio de almacenamiento basado en la nube, como Amazon S3, Google Cloud Storage y Azure Blob Storage, cada uno de los cuales viene con un conjunto completo de API y características (por ejemplo, almacenamiento de varios niveles) que admiten una amplia variedad de diseños de almacenamiento de datos. Por supuesto, los servicios de almacenamiento en la nube también tienen un costo asociado. Este costo generalmente está compuesto por varios componentes, incluido el tamaño general del espacio de almacenamiento que usa, así como actividades como la transferencia de datos hacia, desde o dentro del almacenamiento en la nube. El precio de Amazon S3, por ejemplo, incluye (a partir de la fecha de esta publicación) seis componentes de costo, cada uno de los cuales debe tenerse en cuenta. Es fácil ver cómo la gestión del costo del almacenamiento en la nube puede volverse complicada, y se han desarrollado calculadoras designadas (por ejemplo, aquí) para ayudar con esto.
En una publicación reciente, ampliamos la importancia de diseñar sus datos y su uso de datos para reducir los costos asociados con el almacenamiento de datos. Nuestro enfoque allí fue el uso de la compresión de datos como una forma de reducir el tamaño general de sus datos. En esta publicación, nos enfocamos en un componente de costo a veces pasado por alto del almacenamiento en la nube: el costo de las solicitudes de API realizadas contra sus contenedores de almacenamiento en la nube y objetos de datos. Demostraremos, mediante un ejemplo, por qué este componente a menudo se subestima y cómo puede convertirse en una parte significativa del costo de su aplicación de big data si no se administra correctamente. Luego discutiremos un par de formas simples de mantener este costo bajo control.
Renuncias
Aunque nuestras demostraciones utilizarán Amazon S3, el contenido de esta publicación es igualmente aplicable a cualquier otro servicio de almacenamiento en la nube. Por favor, no interprete nuestra elección de Amazon S3 o cualquier otra herramienta, servicio o biblioteca que mencionemos, como un respaldo para su uso. La mejor opción para usted dependerá de los detalles únicos de su propio proyecto. Además, tenga en cuenta que cualquier elección de diseño con respecto a cómo almacena y utiliza sus datos tendrá sus pros y sus contras que deben ser evaluados cuidadosamente en función de los detalles de su propio proyecto.
Esta publicación incluirá una serie de experimentos que se ejecutaron en una instancia Amazon EC2 c5.4xlarge (con 16 vCPUs y “hasta 10 Gbps” de ancho de banda de red). Compartiremos sus resultados como ejemplos de los resultados comparativos que podría ver. Tenga en cuenta que los resultados pueden variar mucho según el entorno en el que se ejecuten los experimentos. Por favor, no confíe en los resultados presentados aquí para sus propias decisiones de diseño. Le recomendamos encarecidamente que realice estos experimentos, así como experimentos adicionales antes de decidir qué es lo mejor para sus propios proyectos.
- Cómo utilizar el método loc de Pandas para trabajar eficientemente con su DataFrame.
- Cómo crear gráficos de violín con estilo Cyberpunk utilizando Seaborn con un mínimo de código Python.
- ¿Qué es la Gestión de Datos y por qué es importante?
Un simple experimento mental
Supongamos que tiene una aplicación de transformación de datos que actúa en muestras de datos de 1 MB de S3 y produce salidas de datos de 1 MB que se cargan en S3. Supongamos que se le asigna la tarea de transformar 1 mil millones de muestras de datos ejecutando su aplicación en una instancia de Amazon EC2 apropiada (en la misma región que su contenedor S3 para evitar costos de transferencia de datos). Ahora supongamos que Amazon S3 cobra $0.0004 por cada 1000 operaciones GET y $0.005 por cada 1000 operaciones PUT (a partir de la fecha de esta publicación). A primera vista, estos costos podrían parecer tan bajos que serían despreciables en comparación con otros costos relacionados con la transformación de datos. Sin embargo, un cálculo simple muestra que nuestras llamadas a la API de Amazon S3 solas acumularán una factura de $5,400!! Esto puede ser fácilmente el factor de costo más dominante de su proyecto, incluso más que el costo de la instancia de cómputo. Volveremos a este experimento mental al final de la publicación.
Agrupe datos en archivos grandes
La forma obvia de reducir los costos de las llamadas a la API es agrupar las muestras juntas en archivos de un tamaño mayor y ejecutar la transformación en lotes de muestras. Denotando nuestro tamaño de lote por N, esta estrategia podría reducir nuestro costo potencialmente por un factor de N (suponiendo que no se utiliza la transferencia de archivos de varias partes, consulte a continuación). Esta técnica ahorraría dinero no solo en las llamadas PUT y GET, sino en todos los componentes de costo de Amazon S3 que dependen del número de archivos de objeto en lugar del tamaño general de los datos (por ejemplo, solicitudes de transición de ciclo de vida).
Existen varias desventajas al agrupar muestras juntas. Por ejemplo, cuando almacenas muestras de forma individual, puedes acceder libremente a cualquiera de ellas cuando lo desees. Esto se vuelve más difícil cuando las muestras se agrupan. (Ver esta publicación para obtener más información sobre los pros y los contras de agrupar muestras en archivos grandes). Si optas por agrupar muestras, la gran pregunta es cómo elegir el tamaño N. Un N más grande podría reducir los costos de almacenamiento, pero podría introducir latencia, aumentar el tiempo de cálculo y, por extensión, aumentar los costos de cálculo. Encontrar el número óptimo puede requerir cierta experimentación que tenga en cuenta estas y otras consideraciones adicionales.
Pero no nos engañemos. Hacer este tipo de cambio no será fácil. Tus datos pueden tener muchos consumidores (tanto humanos como artificiales), cada uno con su propio conjunto particular de demandas y restricciones. Almacenar tus muestras en archivos separados puede hacer que sea más fácil mantener a todos contentos. Encontrar una estrategia de agrupamiento que satisfaga a todos será difícil.
Posible compromiso: Puts agrupados, Gets individuales
Un compromiso que podrías considerar es subir archivos grandes con muestras agrupadas mientras se habilita el acceso a muestras individuales. Una forma de hacer esto es mantener un archivo de índice con las ubicaciones de cada muestra (el archivo en el que está agrupado, el desplazamiento de inicio y el desplazamiento final) y exponer una capa API delgada a cada consumidor que les permita descargar libremente muestras individuales. La API se implementaría utilizando el archivo de índice y una API de S3 que permita extraer rangos específicos de archivos de objetos (por ejemplo, la función get_object de Boto3). Si bien este tipo de solución no ahorraría dinero en las llamadas GET (ya que todavía estamos extrayendo el mismo número de muestras individuales), las llamadas PUT más caras se reducirían ya que cargaríamos un menor número de archivos grandes. Ten en cuenta que este tipo de solución plantea algunas limitaciones en la biblioteca que usamos para interactuar con S3, ya que depende de una API que permite extraer fragmentos parciales de los objetos de archivo grandes. En publicaciones anteriores (por ejemplo, aquí) hemos discutido las diferentes formas de interactuar con S3, muchas de las cuales no admiten esta función.
El bloque de código a continuación demuestra cómo implementar un conjunto de datos simple de PyTorch (con la versión 1.13 de PyTorch) que utiliza la API get_object de Boto3 para extraer muestras individuales de 1 MB de archivos grandes de muestras agrupadas. Comparamos la velocidad de iteración de los datos de esta manera con la iteración de las muestras almacenadas en archivos individuales.
import os, boto3, time, numpy as npimport torchfrom torch.utils.data import Datasetfrom statistics import mean, varianceKB = 1024MB = KB * KBGB = KB ** 3sample_size = MBnum_samples = 100000# modificar para variar el tamaño de los archivosmuestras_por_archivo = 2000 # para archivos de 2 GBnum_archivos = num_samples//samples_per_filebucket = '<nombre del bucket s3>'ruta_muestra_individual = '<ruta en s3>'ruta_archivo_grande = '<ruta en s3>'class SingleSampleDataset(Dataset): def __init__(self): super().__init__() self.bucket = bucket self.path = single_sample_path self.client = boto3.client("s3") def __len__(self): return num_samples def get_bytes(self, key): response = self.client.get_object( Bucket=self.bucket, Key=key ) return response['Body'].read() def __getitem__(self, index: int): key = f'{self.path}/{index}.image' image = np.frombuffer(self.get_bytes(key),np.uint8) return {"image": image}class LargeFileDataset(Dataset): def __init__(self): super().__init__() self.bucket = bucket self.path = large_file_path self.client = boto3.client("s3") def __len__(self): return num_samples def get_bytes(self, file_index, sample_index): response = self.client.get_object( Bucket=self.bucket, Key=f'{self.path}/{file_index}.bin', Range=f'bytes={sample_index*MB}-{(sample_index+1)*MB-1}' ) return response['Body'].read() def __getitem__(self, index: int): file_index = index // num_files sample_index = index % samples_per_file image = np.frombuffer(self.get_bytes(file_index, sample_index), np.uint8) return {"image": image}# alternar entre archivos de muestras individuales y archivos grandesusar_muestras_agrupadas = Trueif usar_muestras_agrupadas: dataset = LargeFileDataset()else: dataset = SingleSampleDataset()# establecer el número de trabajadores paralelos según el número de vCPUsdl = torch.utils.data.DataLoader(dataset, shuffle=True, batch_size=4, num_workers=16)stats_lst = []t0 = time.perf_counter()for batch_idx, batch in enumerate(dl, start=1): if batch_idx % 100 == 0: t = time.perf_counter() - t0 stats_lst.append(t) t0 = time.perf_counter()mean_calc = mean(stats_lst)var_calc = variance(stats_lst)print(f'media {mean_calc} varianza {var_calc}')La tabla a continuación resume la velocidad de recorrido de datos para diferentes opciones de tamaño de agrupamiento de muestra, N.
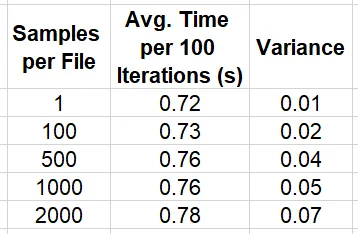
Es importante tener en cuenta que, aunque estos resultados implican fuertemente que agrupar muestras en archivos grandes tiene un impacto relativamente pequeño en el rendimiento de su extracción individual, hemos descubierto que los resultados comparativos varían según el tamaño de la muestra, tamaño de archivo, valores de desplazamiento de archivo, el número de lecturas concurrentes desde el mismo archivo, etc. No es sorprendente que consideraciones como el tamaño de memoria, la alineación de memoria y el estrangulamiento afecten el rendimiento, aunque no tenemos conocimiento del trabajo interno del servicio Amazon S3. Encontrar la configuración óptima para sus datos probablemente requerirá un poco de experimentación.
Un factor significativo que podría interferir con la estrategia de agrupamiento de ahorro de dinero descrita aquí es el uso de descarga y carga multipartes, que discutiremos en la siguiente sección.
Utilice herramientas que permitan el control sobre la transferencia de datos multipartes
Muchos proveedores de servicios de almacenamiento en la nube admiten la opción de carga y descarga multipartes de archivos de objetos. En la transferencia de datos multipartes, los archivos que son más grandes que un cierto umbral se dividen en varias partes que se transfieren simultáneamente. Esta es una característica crítica si desea acelerar la transferencia de datos de archivos grandes. AWS recomienda el uso de carga multipartes para archivos mayores de 100 MB. En el siguiente ejemplo simple, comparamos el tiempo de descarga de un archivo de 2 GB con el umbral multipartes y el tamaño de fragmento configurados con diferentes valores:
import boto3, timeKB = 1024MB = KB * KBGB = KB ** 3s3 = boto3.client('s3')bucket = '<nombre del bucket>'key = '<clave del archivo de 2 GB>'local_path = '/tmp/2GB.bin'num_trials = 10for size in [8*MB, 100*MB, 500*MB, 2*GB]: print(f'tamaño multipartes: {size}') stats = [] for i in range(num_trials): config = boto3.s3.transfer.TransferConfig(multipart_threshold=size, multipart_chunksize=size) t0 = time.time() s3.download_file(bucket, key, local_path, Config=config) stats.append(time.time()-t0) print(f'tamaño multipartes {size} media {mean(stats)}')Los resultados de este experimento se resumen en la tabla a continuación:
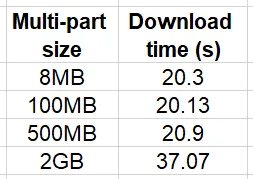
Tenga en cuenta que la comparación relativa dependerá en gran medida del entorno de prueba y específicamente de la velocidad y el ancho de banda de la comunicación entre la instancia y el bucket S3. Nuestro experimento se ejecutó en una instancia que estaba en la misma región que el bucket. Sin embargo, a medida que aumenta la distancia, también aumentará el impacto de usar la descarga multipartes.
Con respecto al tema de nuestra discusión, es importante tener en cuenta las implicaciones de costos de la transferencia de datos multipartes. Específicamente, cuando usa la transferencia de datos multipartes, se le cobra por la operación de API de cada una de las partes del archivo. En consecuencia, el uso de carga/descarga multipartes limitará el potencial de ahorro de costos de agrupar muestras de datos en archivos grandes.
Muchas API utilizan descarga multipartes por defecto. Esto es excelente si su interés principal es reducir la latencia de su interacción con S3. Pero si su preocupación es limitar los costos, este comportamiento predeterminado no funciona a su favor. Boto3, por ejemplo, es una API popular de Python para cargar y descargar archivos desde S3. Si no se especifica, las API de S3 de boto3, como upload_file y download_file, utilizarán una TransferConfig predeterminada, que aplica la carga/descarga multipartes con un tamaño de fragmento de 8 MB a cualquier archivo mayor de 8 MB. Si es responsable de controlar los costos en la nube en su organización, es posible que se sorprenda al descubrir que estas API se están utilizando ampliamente con sus configuraciones predeterminadas. En muchos casos, puede encontrar que estas configuraciones son injustificadas y que aumentar los valores de umbral y tamaño de fragmento multipartes, o desactivar por completo la transferencia de datos multipartes, tendrá poco impacto en el rendimiento de su aplicación.
Ejemplo – Impacto del tamaño de transferencia de archivos multipartes en velocidad y costo
En el bloque de código a continuación, creamos una función de transformación multiproceso simple y medimos el impacto del tamaño de fragmento multipartes en su rendimiento y costo:
import os, boto3, time, mathfrom multiprocessing import Poolfrom statistics import mean, varianceKB = 1024MB = KB * KBsample_size = MBnum_files = 64samples_per_file = 500file_size = sample_size*samples_per_filenum_processes = 16bucket = '<s3 bucket>'large_file_path = '<path in s3>'local_path = '/tmp'num_trials = 5cost_per_get = 4e-7cost_per_put = 5e-6for multipart_chunksize in [1*MB, 8*MB, 100*MB, 200*MB, 500*MB]: def empty_transform(file_index): s3 = boto3.client('s3') config = boto3.s3.transfer.TransferConfig( multipart_threshold=multipart_chunksize, multipart_chunksize=multipart_chunksize ) s3.download_file(bucket, f'{large_file_path}/{file_index}.bin', f'{local_path}/{file_index}.bin', Config=config) s3.upload_file(f'{local_path}/{file_index}.bin', bucket, f'{large_file_path}/{file_index}.out.bin', Config=config) stats = [] for i in range(num_trials): with Pool(processes=num_processes) as pool: t0 = time.perf_counter() pool.map(empty_transform, range(num_files)) transform_time = time.perf_counter() - t0 stats.append(transform_time) num_chunks = math.ceil(file_size/multipart_chunksize) num_operations = num_files*num_chunks transform_cost = num_operations * (cost_per_get + cost_per_put) if num_chunks > 1: # si se utiliza multipartes, agregar el costo de # las llamadas a la API CreateMultipartUpload y CompleteMultipartUpload transform_cost += 2 * num_files * cost_per_put print(f'tamaño de fragmentos {multipart_chunksize}') print(f'tiempo de transformación {mean(stats)} varianza {variance(stats)} print(f'costo de llamadas API {transform_cost}')En este ejemplo, hemos fijado el tamaño del archivo en 500 MB y aplicado la misma configuración multipartes tanto para la descarga como para la carga. Un análisis más completo variaría el tamaño de los archivos de datos y la configuración multipartes.
En la tabla siguiente resumimos los resultados del experimento.
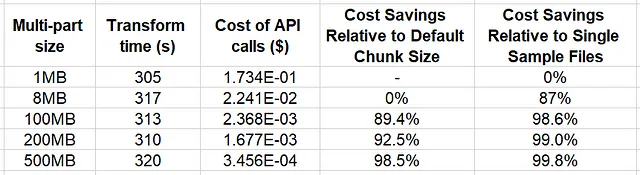
Los resultados indican que hasta un tamaño de fragmento multipartes de 500 MB (el tamaño de nuestros archivos), el impacto en el tiempo de transformación de datos es mínimo. Por otro lado, el potencial de ahorro en los costos de la API de almacenamiento en la nube es significativo, hasta un 98,4% en comparación con el tamaño de fragmento predeterminado de Boto3 (8 MB). Este ejemplo demuestra no solo el beneficio económico de agrupar las muestras, sino que también implica una oportunidad adicional de ahorro a través de la configuración adecuada de la transferencia de datos multipartes.
Conclusión
Aplicaremos los resultados de nuestro último ejemplo al experimento mental que presentamos al comienzo de esta publicación. Mostramos que aplicar una transformación simple a 1.000 millones de muestras de datos costaría $5.400 si las muestras se almacenaran en archivos individuales. Si agrupáramos las muestras en 2 millones de archivos, cada uno con 500 muestras, y aplicáramos la transformación sin transferencia de datos multipartes (como en la última prueba del ejemplo anterior), ¡el costo de las llamadas API se reduciría a $10.8! Al mismo tiempo, suponiendo el mismo entorno de prueba, el impacto que esperaríamos (basado en nuestros experimentos) en el tiempo de ejecución total sería relativamente bajo. Yo lo llamaría un buen trato. ¿No te parece?
Resumen
Cuando desarrollamos aplicaciones de big data en la nube, es vital que estemos completamente familiarizados con todos los detalles de los costos de nuestras actividades. En esta publicación nos enfocamos en el componente de “Solicitudes y recuperación de datos” de la estrategia de precios de Amazon S3. Demostramos cómo este componente puede convertirse en una parte importante del costo total de una aplicación de big data. Discutimos dos de los factores que pueden afectar este costo: la forma en que se agrupan las muestras de datos y la forma en que se utiliza la transferencia de datos multipartes.
Naturalmente, optimizar sólo un componente de coste probablemente aumentará otros componentes de manera que elevará el costo global. Un diseño adecuado para su almacenamiento de datos deberá tener en cuenta todos los posibles factores de coste y dependerá en gran medida de sus necesidades específicas de datos y patrones de uso.
Como siempre, no dude en ponerse en contacto con comentarios y correcciones.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Más allá de la precisión Abrazando la serendipia y la novedad en recomendaciones para la retención a largo plazo del usuario.
- Ingrese sus innovaciones de síntesis de datos para reformar la policía y ganar dinero.
- Cercanía y Comunidades Analizando Redes Sociales con Python y NetworkX – Parte 3
- Cómo preparar tus datos para visualizaciones
- Aprendizaje Profundo en Sistemas de Recomendación Una introducción.
- ¿Reemplazará la inteligencia artificial a los humanos?
- ¿Quiénes son los Científicos de Datos Ciudadanos y qué hacen?





