Búsqueda de similitud, Parte 5 Hashing sensible a la localidad (LSH)
LSH (Local Sensitive Hashing) for Similarity Search, Part 5.
Explorar cómo se puede incorporar la información de similitud en una función hash
La búsqueda de similitud es un problema donde, dado una consulta, el objetivo es encontrar los documentos más similares a ella entre todos los documentos de la base de datos.
Introducción
En la ciencia de datos, la búsqueda de similitud a menudo aparece en el dominio de NLP, los motores de búsqueda o los sistemas de recomendación donde se necesitan recuperar los documentos o elementos más relevantes para una consulta. Existe una gran variedad de formas diferentes de mejorar el rendimiento de búsqueda en grandes volúmenes de datos.
En partes anteriores de esta serie de artículos, discutimos el índice de archivos invertidos, la cuantificación de productos y HNSW y cómo se pueden usar juntos para mejorar la calidad de búsqueda. En este capítulo, vamos a ver un enfoque principalmentre diferente que mantiene tanto una alta velocidad de búsqueda como calidad.
- Moldeando el Futuro de la IA Una Encuesta Exhaustiva sobre Modelos de Pre-Entrenamiento Visión-Lenguaje y su Papel en Tareas Uni-Modales y Multi-Modales.
- Implemente un punto final de inferencia de ML sin servidor para modelos de lenguaje grandes utilizando FastAPI, AWS Lambda y AWS CDK.
- GPT vs BERT ¿Cuál es mejor?
Búsqueda de similitud, Parte 3: Mezcla del índice de archivos invertidos y la cuantificación de productos
En las dos primeras partes de esta serie hemos discutido dos algoritmos fundamentales en la recuperación de información: invertido…
towardsdatascience.com
Búsqueda de similitud, Parte 4: Mundo pequeño navegable jerárquico (HNSW)
Mundo pequeño navegable jerárquico (HNSW) es un algoritmo de última generación utilizado para una búsqueda aproximada de los más cercanos…
towardsdatascience.com
Local Sensitive Hashing (LSH) es un conjunto de métodos que se utilizan para reducir el alcance de búsqueda mediante la transformación de vectores de datos en valores hash mientras se preserva la información sobre su similitud.
Vamos a discutir el enfoque tradicional que consta de tres pasos:
- Shingling: codificación de textos originales en vectores.
- MinHashing: transformación de vectores en una representación especial llamada firma que se puede usar para comparar la similitud entre ellos.
- Función LSH: hashing de bloques de firma en diferentes cubetas. Si las firmas de un par de vectores caen en la misma cubeta al menos una vez, se consideran candidatos.
Vamos a profundizar gradualmente en los detalles a lo largo del artículo de cada uno de estos pasos.
Shingling
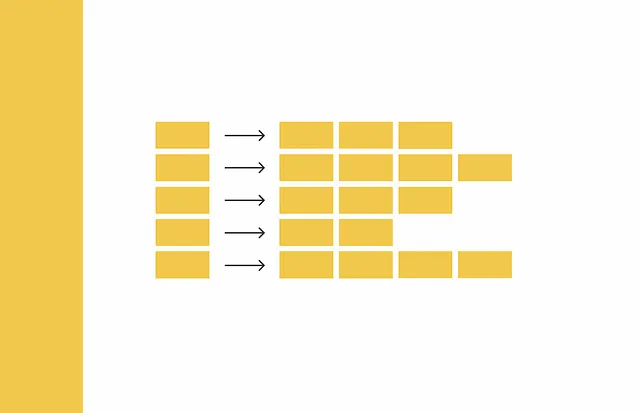
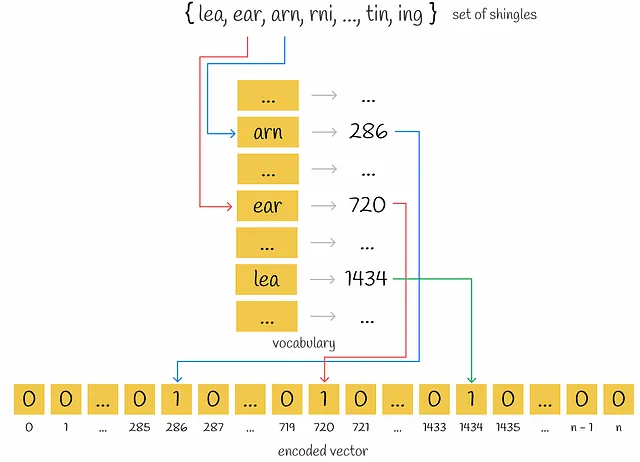
Shingling es el proceso de recolectar k-gramos en textos dados. k-gramo es un grupo de tokens secuenciales k. Dependiendo del contexto, los tokens pueden ser palabras o símbolos. El objetivo final del shingling es codificar cada documento utilizando los k-gramos recolectados. Utilizaremos la codificación one-hot para esto. Sin embargo, también se pueden aplicar otros métodos de codificación.
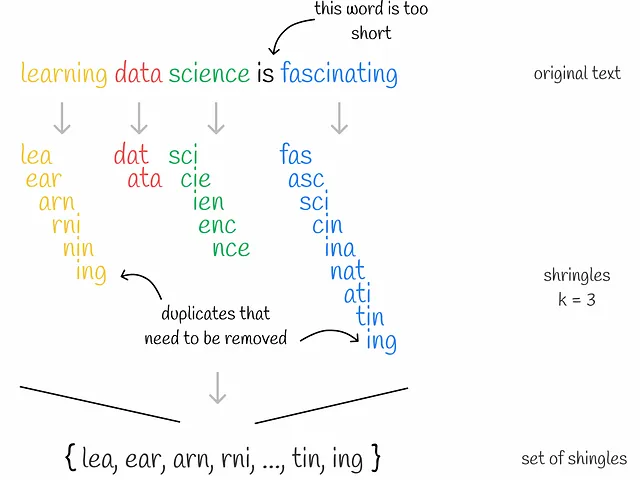
En primer lugar, se recogen k-gramos únicos para cada documento. En segundo lugar, se necesita un vocabulario para codificar cada documento que represente un conjunto de k-gramos únicos en todos los documentos. Luego, para cada documento, se crea un vector de ceros con una longitud igual al tamaño del vocabulario. Para cada k-gramo que aparece en el documento, se identifica su posición en el vocabulario y se coloca un “1” en la posición correspondiente del vector del documento. Incluso si el mismo k-gramo aparece varias veces en un documento, no importa: el valor en el vector siempre será 1.
MinHashing
En esta etapa, los textos iniciales han sido vectorizados. La similitud de los vectores se puede comparar mediante el índice de Jaccard. Recuerda que el índice de Jaccard de dos conjuntos se define como el número de elementos comunes en ambos conjuntos dividido por la longitud de todos los elementos.
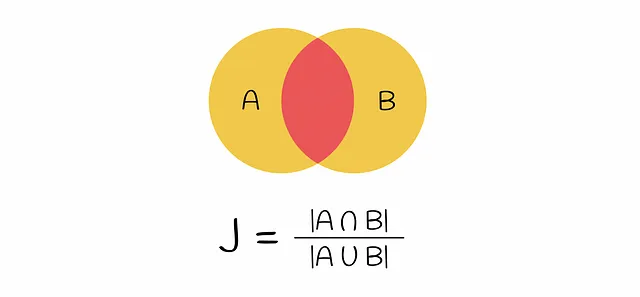
Si se toma un par de vectores codificados, la intersección en la fórmula para el índice de Jaccard es el número de filas que contienen ambos números 1 (es decir, el k-gramo aparece en ambos vectores) y la unión es el número de filas con al menos un 1 (el k-gramo está presente al menos en uno de los vectores).
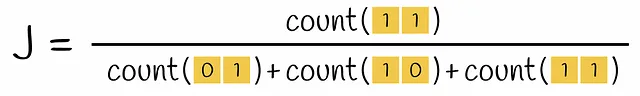
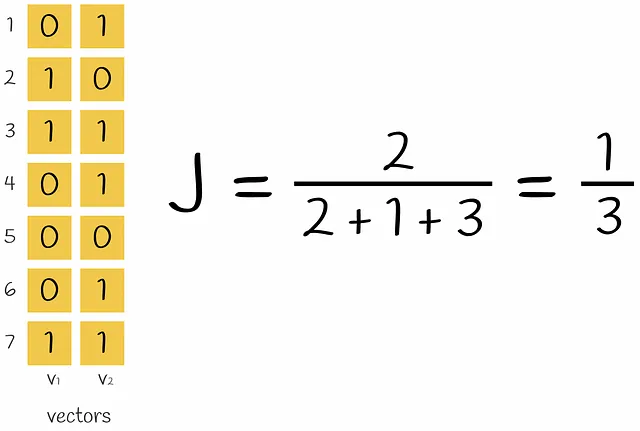
El problema actual es la dispersión de los vectores codificados. Calcular una puntuación de similitud entre dos vectores codificados con uno es muy lento. Convertirlos en un formato denso los haría más eficientes para operar con ellos más tarde. En última instancia, el objetivo es diseñar una función que transforme estos vectores a una dimensión más pequeña preservando la información sobre su similitud. El método que construye tal función se llama MinHashing.
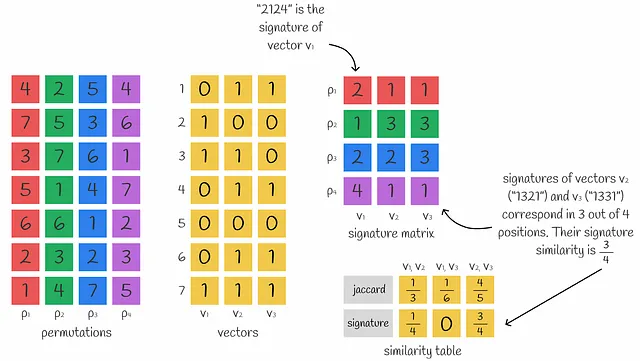
MinHashing es una función de hash que permuta los componentes de un vector de entrada y luego devuelve el primer índice donde el componente del vector permutado es igual a 1.
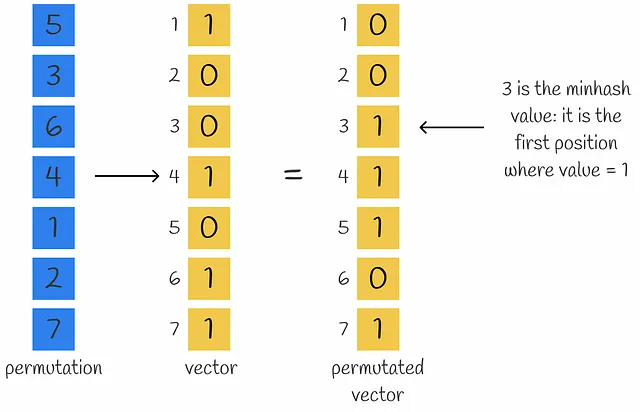
Para obtener una representación densa de un vector que consta de n números, se pueden utilizar n funciones de minhash para obtener n valores de minhash que forman una firma.
Puede que no parezca obvio al principio, pero varios valores de minhash se pueden usar para aproximar la similitud de Jaccard entre vectores. De hecho, cuanto más valores de minhash se usen, más precisa será la aproximación.
Esto es solo una observación útil. Resulta que hay todo un teorema detrás de las escenas. Veamos por qué se puede calcular el índice de Jaccard usando firmas.
Demostración de la afirmación
Supongamos que un par dado de vectores contiene solo filas de tipo 01, 10 y 11. Luego se realiza una permutación aleatoria en estos vectores. Dado que existe al menos un 1 en todas las filas, entonces al calcular ambos valores hash, al menos uno de estos dos procesos de cálculo de valores hash se detendrá en la primera fila de un vector con el valor hash correspondiente igual a 1.

¿Cuál es la probabilidad de que el segundo valor hash sea igual al primero? Obviamente, esto solo sucederá si el segundo valor hash también es igual a 1. Esto significa que la primera fila tiene que ser del tipo 11. Dado que la permutación se tomó al azar, la probabilidad de tal evento es igual a P = count(11) / (count(01) + count(10) + count(11)). Esta expresión es absolutamente la misma que la fórmula del índice de Jaccard. Por lo tanto:
La probabilidad de obtener valores hash iguales para dos vectores binarios basados en una permutación aleatoria de filas es igual al índice de Jaccard.
Sin embargo, al probar la afirmación anterior, asumimos que los vectores iniciales no contenían filas del tipo 00. Es evidente que las filas del tipo 00 no cambian el valor del índice de Jaccard. De manera similar, la probabilidad de obtener los mismos valores hash con filas de tipo 00 incluidas no lo afecta. Por ejemplo, si la primera fila permutada es 00, el algoritmo minhash simplemente la ignora y pasa a la siguiente fila hasta que exista al menos un 1 en una fila. Por supuesto, las filas del tipo 00 pueden resultar en diferentes valores hash que sin ellas, pero la probabilidad de obtener los mismos valores hash sigue siendo la misma.

Hemos demostrado una afirmación importante. Pero, ¿cómo se puede estimar la probabilidad de obtener los mismos valores minhash? Definitivamente, es posible generar todas las permutaciones posibles para los vectores y luego calcular todos los valores minhash para encontrar la probabilidad deseada. Por razones obvias, esto no es eficiente porque el número de permutaciones posibles para un vector de tamaño n es igual a n!. Sin embargo, la probabilidad puede evaluarse aproximadamente: usemos muchas funciones de hash para generar esa cantidad de valores hash.
El índice de Jaccard de dos vectores binarios es aproximadamente igual al número de valores correspondientes en sus firmas.
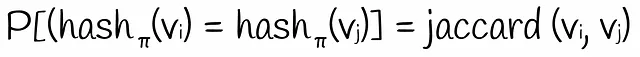
Es fácil notar que tomar firmas más largas resulta en cálculos más precisos.
Función LSH
En este momento, podemos transformar textos en firmas densas de igual longitud preservando la información sobre la similitud. Sin embargo, en la práctica, dichas firmas aún suelen tener dimensiones altas y sería ineficiente compararlas directamente.
Tenemos n = 10⁶ documentos con sus firmas de longitud 100. Suponiendo que un solo número de una firma requiere 4 bytes para almacenar, entonces toda la firma requeriría 400 bytes. Para almacenar n = 10⁶ documentos, se necesitan 400 MB de espacio, lo cual es factible en la realidad. Pero comparar cada documento con cada uno en una manera de fuerza bruta requeriría aproximadamente 5 * 10¹¹ comparaciones, lo cual es demasiado, especialmente cuando n es aún mayor.

Para evitar el problema, es posible construir una tabla hash para acelerar el rendimiento de búsqueda, pero incluso si dos firmas son muy similares y difieren solo en 1 posición, todavía es probable que tengan un hash diferente (porque los restos de vector son probablemente diferentes). Sin embargo, normalmente queremos que caigan en el mismo bucket. Aquí es donde LSH viene al rescate.
El mecanismo LSH construye una tabla hash que consiste en varias partes que colocan un par de firmas en el mismo bucket si tienen al menos una parte correspondiente.
LSH toma una matriz de firmas y la divide horizontalmente en b partes iguales llamadas bandas, cada una conteniendo r filas. En lugar de enchufar toda la firma en una sola función hash, la firma se divide en b partes y cada subsignatura se procesa de forma independiente por una función hash. Como consecuencia, cada una de las subsignaturas cae en buckets separados.
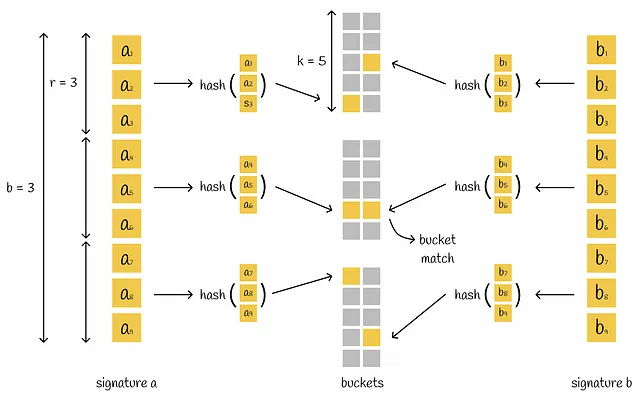
Si hay al menos una colisión entre subvectores correspondientes de dos firmas diferentes, se consideran candidatas. Como podemos ver, esta condición es más flexible ya que para considerar vectores como candidatos no necesitan ser absolutamente iguales. Sin embargo, esto aumenta el número de falsos positivos: un par de firmas diferentes pueden tener una sola parte correspondiente pero en general ser completamente diferentes. Dependiendo del problema, siempre es mejor optimizar los parámetros b, r y k.
Tasa de error
Con LSH, es posible estimar la probabilidad de que dos firmas con una similitud s sean consideradas candidatas, dadas un número de bandas b y un número de filas r en cada banda. Encontremos la fórmula para ello en varios pasos.
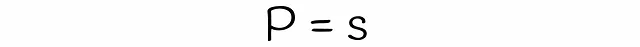
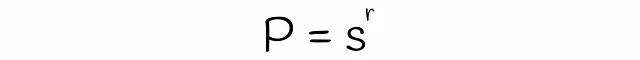
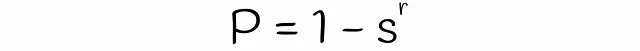
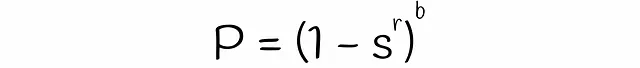
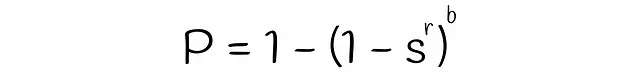
Se debe tener en cuenta que la fórmula no tiene en cuenta las colisiones cuando diferentes subvectores se hashan accidentalmente en el mismo cubo. Debido a esto, la probabilidad real de que las firmas sean candidatas podría diferir insignificativamente.
Ejemplo
Para tener una mejor idea de la fórmula que acabamos de obtener, consideremos un ejemplo sencillo. Consideremos dos firmas con una longitud de 35 símbolos que se dividen por igual en 5 bandas con 7 filas cada una. Aquí está la tabla que representa la probabilidad de tener al menos una banda igual basada en su similitud Jaccard:

Observamos que si dos firmas similares tienen una similitud de Jaccard del 80%, entonces tienen una banda correspondiente en el 93,8% de los casos (verdaderos positivos). En el resto del 6,2% de los escenarios, tal par de firmas es un falso negativo.
Ahora tomemos dos firmas diferentes. Por ejemplo, solo son similares en un 20%. Por lo tanto, son candidatas falsas positivas en el 0,224% de los casos. En otros 99,776% de los casos, no tienen una banda similar, por lo que son verdaderos negativos.
Visualización
Ahora visualicemos la conexión entre la similitud s y la probabilidad P de que dos firmas se conviertan en candidatas. Normalmente, con una similitud de firma más alta s, las firmas deberían tener una mayor probabilidad de ser candidatas. Idealmente, se vería así:
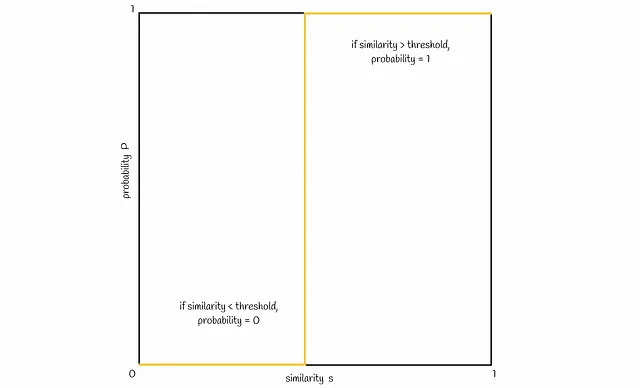
Basado en la fórmula de probabilidad obtenida anteriormente, una línea típica se vería como en la figura siguiente:
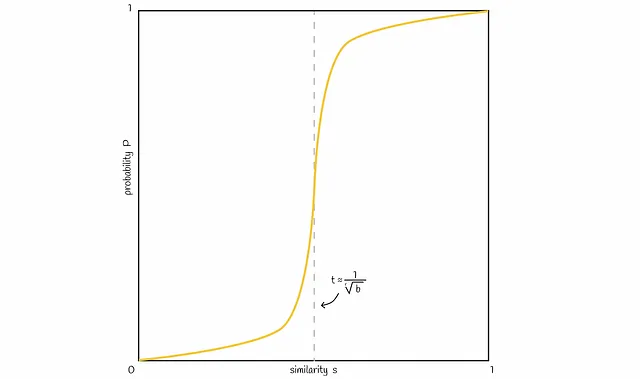
Es posible variar el número de bandas b para desplazar la línea en la figura hacia la izquierda o hacia la derecha. Aumentar b mueve la línea hacia la izquierda y resulta en más FP , disminuirlo la desplaza hacia la derecha y lleva a más FN . Es importante encontrar un buen equilibrio, dependiendo del problema.
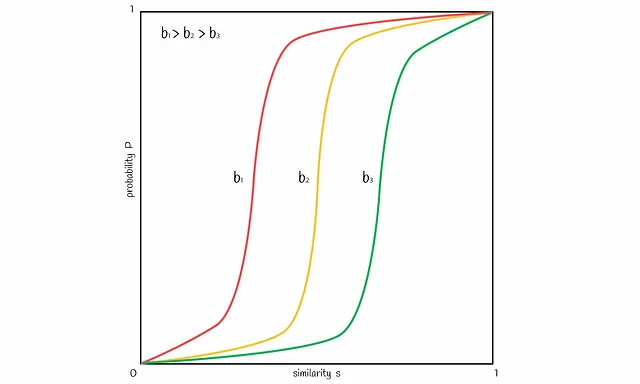
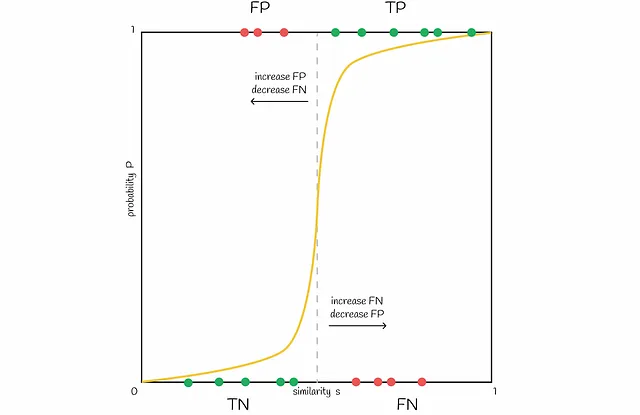
Experimentos con diferentes números de bandas y filas
A continuación se construyen varias gráficas de línea para diferentes valores de b y r . Siempre es mejor ajustar estos parámetros en función de la tarea específica para recuperar con éxito todos los pares de documentos similares e ignorar aquellos con firmas diferentes.
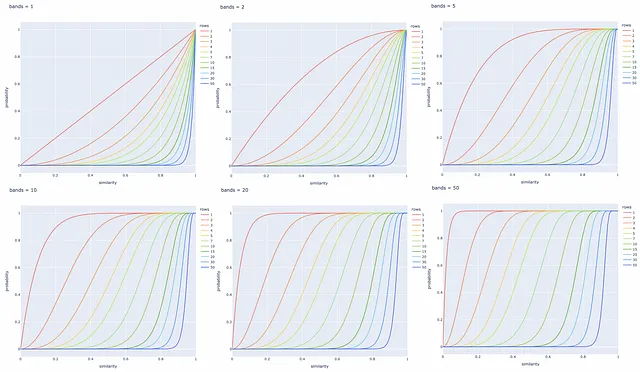
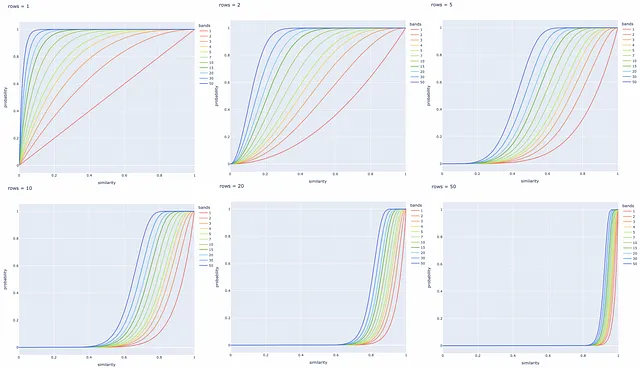
Conclusión
Hemos recorrido una implementación clásica del método LSH. LSH optimiza significativamente la velocidad de búsqueda utilizando representaciones de firma de dimensiones más bajas y un mecanismo de hashing rápido para reducir el alcance de búsqueda de los candidatos. Al mismo tiempo, esto tiene un costo en la precisión de la búsqueda, pero en la práctica, la diferencia suele ser insignificante.
Sin embargo, LSH es vulnerable a datos de alta dimensión: más dimensiones requieren longitudes de firma más largas y más cálculos para mantener una buena calidad de búsqueda. En tales casos, se recomienda utilizar otro índice.
De hecho, existen diferentes implementaciones de LSH, pero todas están basadas en el mismo paradigma de transformar vectores de entrada en valores de hash mientras se preserva información sobre su similitud. Básicamente, otros algoritmos simplemente definen otras formas de obtener estos valores de hash.
Las proyecciones aleatorias son otro método de LSH que se cubrirá en el próximo capítulo y que se implementa como un índice LSH en la biblioteca Faiss para la búsqueda de similitud.
Recursos
- Locality Sensitive Hashing | Andrew Wylie | 2 de diciembre de 2013
- Data Mining | Locality Sensitive Hashing | Universidad de Szeged
- Repositorio Faiss
Todas las imágenes, a menos que se indique lo contrario, son del autor.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Inmersión teórica profunda en la Regresión Lineal
- Conoce BITE Un Nuevo Método Que Reconstruye la Forma y Poses 3D de un Perro a Partir de una Imagen, Incluso con Poses Desafiantes como Sentado y Acostado.
- Conoce Paella Un Nuevo Modelo de IA Similar a Difusión que Puede Generar Imágenes de Alta Calidad Mucho Más Rápido que Usando Difusión Estable.
- Usando ChatGPT para Debugging Eficiente
- Científicos mejoran la detección de delirio utilizando Inteligencia Artificial y electroencefalogramas de respuesta rápida.
- Cómo Light & Wonder construyó una solución de mantenimiento predictivo para máquinas de juego en AWS.
- Revolucionando el descubrimiento de medicamentos modelo de aprendizaje automático identifica compuestos potenciales antienvejecimiento y allana el camino para futuros tratamientos de enfermedades complejas.