Conozca LLM-Blender Un Nuevo Marco de Ensamblado para Lograr un Rendimiento Constantemente Superior al Aprovechar las Diversas Fortalezas de Múltiples Modelos de Lenguaje de Código Abierto (LLMs) de Gran Tamaño.
LLM-Blender Nuevo marco de ensamblado de múltiples modelos de lenguaje de código abierto para un rendimiento superior.


Los modelos de lenguaje grandes han mostrado un rendimiento notable en una amplia gama de tareas. Desde producir contenido único y creativo y cuestionar respuestas hasta traducir idiomas y resumir párrafos de texto, los MLL han tenido éxito en imitar a los humanos. Algunos MLL bien conocidos como GPT, BERT y PaLM han estado en los titulares por seguir con precisión las instrucciones y acceder a grandes cantidades de datos de alta calidad. Modelos como GPT4 y PaLM no son de código abierto, lo que impide que cualquiera entienda sus arquitecturas y los datos de entrenamiento. Por otro lado, la naturaleza de código abierto de MLL como Pythia, LLaMA y Flan-T5 brinda una oportunidad a los investigadores para ajustar y mejorar los modelos en conjuntos de datos de instrucciones personalizadas. Esto permite el desarrollo de MLL más pequeños y eficientes como Alpaca, Vicuna, OpenAssistant y MPT.
No hay un único MLL de código abierto que lidere el mercado, y los mejores MLL para varios ejemplos pueden diferir significativamente entre sí. Por lo tanto, para producir continuamente respuestas mejoradas para cada entrada, es esencial ensamblar dinámicamente estos MLL. Los sesgos, errores e incertidumbres pueden reducirse mediante la integración de las contribuciones distintivas de varios MLL, lo que resulta en resultados que se acercan más a las preferencias humanas. Para abordar esto, investigadores del Instituto Allen de Inteligencia Artificial, la Universidad del Sur de California y la Universidad de Zhejiang han propuesto LLM-BLENDER, un marco de ensamblaje que obtiene consistentemente un rendimiento superior utilizando las muchas ventajas de varios modelos de lenguaje grandes de código abierto.
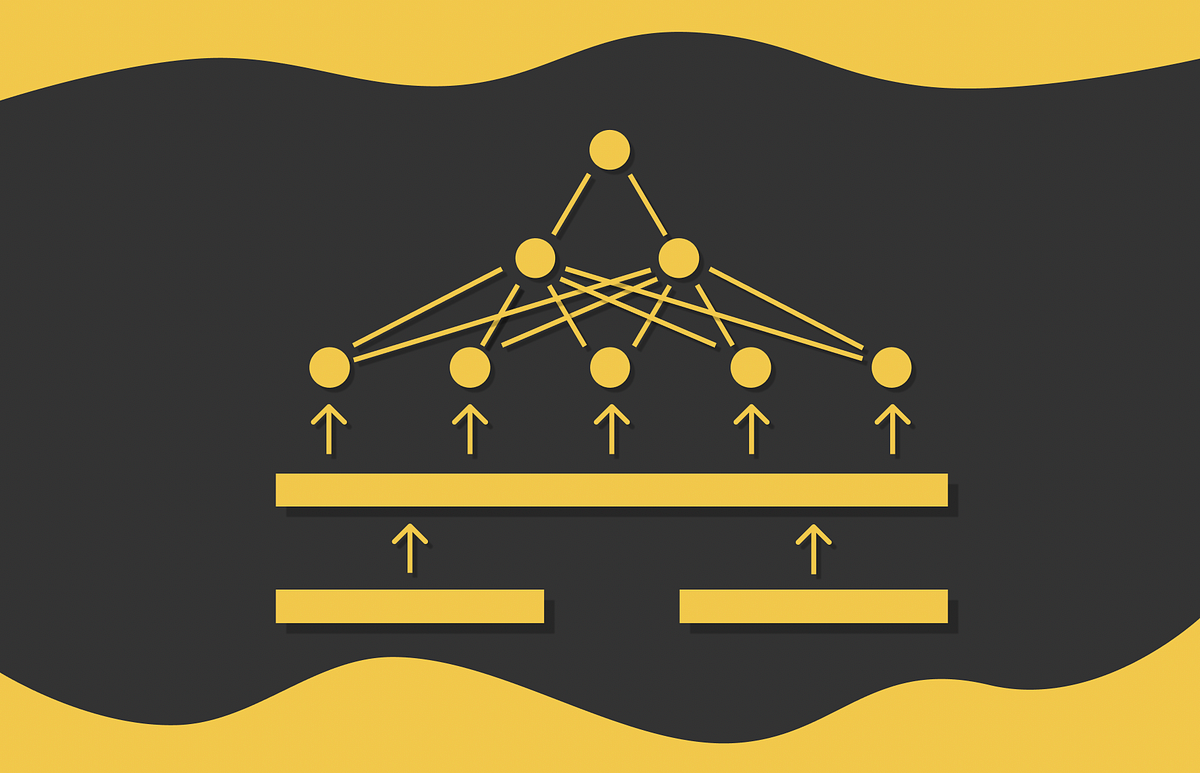
LLM-BLENDER consta de dos módulos: PAIRRANKER y GENFUSER. Estos módulos muestran que el MLL óptimo para diferentes ejemplos puede variar significativamente. PAIRRANKER, el primer módulo, se ha desarrollado para identificar pequeñas variaciones entre las salidas potenciales. Utiliza una técnica avanzada de comparación por pares en la que el texto original y dos salidas candidatas de varios MLL actúan como entradas. Para codificar conjuntamente la entrada y el par candidato, PAIRRANKER utiliza codificadores de atención cruzada como RoBERTa, donde la calidad de los dos candidatos puede ser determinada por PAIRRANKER utilizando esta codificación.
- Decodificando Glassdoor Ideas impulsadas por NLP para decisiones informadas
- La caja de voz de Meta la IA que habla todos los idiomas.
- Redes Neuronales con Paso de Mensajes Retrasado y Reconfiguración Dinámica
El segundo módulo, GENFUSER, se centra en fusionar los candidatos clasificados en los primeros puestos para generar una salida mejorada. Aprovecha al máximo las ventajas de los candidatos elegidos minimizando sus desventajas. GENFUSER tiene como objetivo desarrollar una salida que sea superior a la de cualquier MLL mediante la fusión de las salidas de varios MLL.
Para la evaluación, el equipo ha proporcionado un conjunto de datos de referencia llamado MixInstruct, que incorpora comparaciones de pares de Oracle y combina varios conjuntos de datos de instrucciones. Este conjunto de datos utiliza 11 MLL de código abierto populares para generar múltiples candidatos para cada entrada en varias tareas de seguimiento de instrucciones. Comprende ejemplos de entrenamiento, validación y prueba con comparaciones de Oracle para la evaluación automática. Estas comparaciones de Oracle se han utilizado para dar a las salidas candidatas una clasificación de verdad fundamental, lo que permite evaluar el rendimiento de LLM-BLENDER y otras técnicas de referencia.
Los hallazgos experimentales han demostrado que LLM-BLENDER funciona mucho mejor en una variedad de parámetros de evaluación que los MLL individuales y las técnicas de referencia. Establece una brecha de rendimiento considerable y muestra que el empleo de la metodología de ensamblaje LLM-BLENDER resulta en una salida de mayor calidad en comparación con el uso de un solo MLL o método de referencia. Las selecciones de PAIRRANKER han superado a los modelos de MLL individuales debido a su mejor rendimiento en métricas basadas en referencia y GPT-Rank. A través de una fusión eficiente, GENFUSER mejora significativamente la calidad de la respuesta utilizando las mejores selecciones de PAIRRANKER.
LLM-BLENDER también ha superado a los MLL individuales, como Vicuna, y ha demostrado un gran potencial para mejorar la implementación y la investigación de MLL mediante el aprendizaje de conjunto.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Calcular la Eficiencia Computacional de los Modelos de Aprendizaje Profundo con FLOPs y MACs
- Revolucionando la eficiencia de la IA El SqueezeLLM de UC Berkeley presenta la cuantificación densa y dispersa, uniendo la calidad y la velocidad en la entrega de modelos de lenguaje grandes.
- Meta AI presenta I-JEPA revolucionario Un gran salto innovador en la visión por computadora que emula el aprendizaje y el razonamiento humano y animal.
- Meta AI presenta MusicGen un modelo de generación de música simple y controlable impulsado tanto por texto como por melodía.
- Aprendizaje Automático en un Espacio No Euclidiano
- Una Guía Completa sobre Redes Neuronales Convolucionales
- Búsqueda de similitud, Parte 4 Hierarchical Navigable Small World (HNSW)