Aprendiendo a hacer crecer modelos de aprendizaje automático
'Learning to grow machine learning models'
La nueva técnica LiGO acelera el entrenamiento de modelos de aprendizaje automático grandes, reduciendo el costo monetario y ambiental de desarrollar aplicaciones de inteligencia artificial.
No es ningún secreto que el ChatGPT de OpenAI tiene capacidades increíbles, por ejemplo, el chatbot puede escribir poesía que se asemeja a los sonetos de Shakespeare o depurar el código de un programa informático. Estas habilidades son posibles gracias al modelo de aprendizaje automático masivo en el que se basa ChatGPT. Los investigadores han descubierto que cuando estos modelos son lo suficientemente grandes, surgen capacidades extraordinarias.
- Uniéndose a la lucha contra el sesgo en la atención médica
- Los investigadores del MIT hacen que los modelos de lenguaje sean autoaprendices escalables.
- La IA se está comiendo la Ciencia de Datos.
Pero los modelos más grandes también requieren más tiempo y dinero para entrenarse. El proceso de entrenamiento implica mostrar cientos de miles de millones de ejemplos a un modelo. La recopilación de tanta información es en sí misma un proceso complicado. Luego vienen los costos monetarios y ambientales de ejecutar muchas computadoras potentes durante días o semanas para entrenar un modelo que puede tener miles de millones de parámetros.
“Se estima que entrenar modelos del tamaño en el que se supone que se ejecutará ChatGPT podría costar millones de dólares, solo para una ejecución de entrenamiento. ¿Podemos mejorar la eficiencia de estos métodos de entrenamiento para obtener buenos modelos en menos tiempo y por menos dinero? Proponemos hacer esto aprovechando modelos de lenguaje más pequeños que ya han sido entrenados anteriormente”, dice Yoon Kim, profesor asistente en el Departamento de Ingeniería Eléctrica y Ciencias de la Computación del MIT y miembro del Laboratorio de Ciencias de la Computación e Inteligencia Artificial (CSAIL).
En lugar de descartar una versión anterior de un modelo, Kim y sus colaboradores lo utilizan como bloques de construcción para un nuevo modelo. Utilizando el aprendizaje automático, su método aprende a “hacer crecer” un modelo más grande a partir de un modelo más pequeño de tal manera que codifica el conocimiento que el modelo más pequeño ya ha adquirido. Esto permite un entrenamiento más rápido del modelo más grande.
Su técnica ahorra aproximadamente el 50 por ciento del costo computacional requerido para entrenar un modelo grande, en comparación con los métodos que entrenan un nuevo modelo desde cero. Además, los modelos entrenados utilizando el método del MIT funcionaron tan bien o mejor que los modelos entrenados con otras técnicas que también utilizan modelos más pequeños para permitir un entrenamiento más rápido de modelos más grandes.
Reducir el tiempo necesario para entrenar modelos enormes podría ayudar a los investigadores a avanzar más rápido con menos gastos, al tiempo que reduce las emisiones de carbono generadas durante el proceso de entrenamiento. También podría permitir que grupos de investigación más pequeños trabajen con estos modelos masivos, lo que podría abrir la puerta a muchos nuevos avances.
“A medida que buscamos democratizar este tipo de tecnologías, hacer que el entrenamiento sea más rápido y menos costoso será cada vez más importante”, dice Kim, autor principal de un artículo sobre esta técnica.
Kim y su estudiante graduado Lucas Torroba Hennigen escribieron el artículo con el autor principal Peihao Wang, un estudiante graduado de la Universidad de Texas en Austin, así como otros en el Laboratorio de AI MIT-IBM Watson y la Universidad de Columbia. La investigación se presentará en la Conferencia Internacional sobre Representaciones de Aprendizaje.
Cuanto más grande, mejor
Los modelos de lenguaje grandes como GPT-3, que es el núcleo de ChatGPT, se construyen utilizando una arquitectura de red neuronal llamada transformador. Una red neuronal, basada vagamente en el cerebro humano, está compuesta por capas de nodos interconectados, o “neuronas”. Cada neurona contiene parámetros, que son variables aprendidas durante el proceso de entrenamiento que la neurona utiliza para procesar datos.
Las arquitecturas de transformador son únicas porque, a medida que estos tipos de modelos de red neuronal se hacen más grandes, obtienen resultados mucho mejores.
“Esto ha llevado a una carrera armamentística de empresas que intentan entrenar transformadores cada vez más grandes en conjuntos de datos cada vez más grandes. Más que otras arquitecturas, parece que las redes de transformador mejoran mucho con la escala. Simplemente no estamos exactamente seguros de por qué es así”, dice Kim.
Estos modelos a menudo tienen cientos de millones o miles de millones de parámetros aprendibles. Entrenar todos estos parámetros desde cero es costoso, por lo que los investigadores buscan acelerar el proceso.
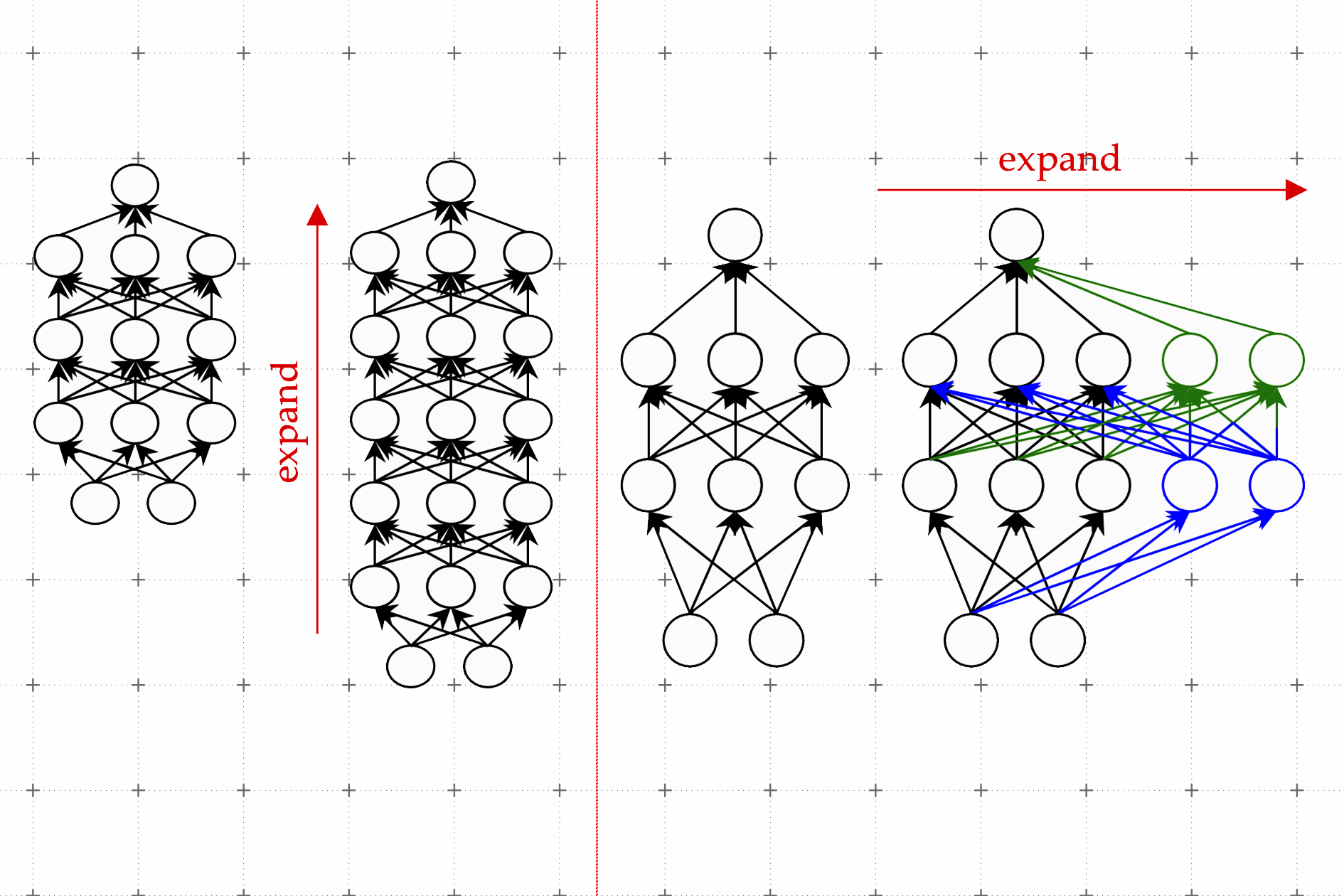
Una técnica efectiva se conoce como crecimiento del modelo. Usando el método de crecimiento del modelo, los investigadores pueden aumentar el tamaño de un transformador copiando neuronas o incluso capas enteras de una versión anterior de la red y luego apilándolas encima. Pueden hacer que una red sea más ancha agregando nuevas neuronas a una capa o hacerla más profunda agregando capas adicionales de neuronas.
En contraste con los enfoques anteriores para el crecimiento del modelo, los parámetros asociados con las nuevas neuronas en el transformador expandido no son solo copias de los parámetros de la red más pequeña, explica Kim. En cambio, son combinaciones aprendidas de los parámetros del modelo más pequeño.
Aprendiendo a crecer
Kim y sus colaboradores utilizan el aprendizaje automático para aprender un mapeo lineal de los parámetros del modelo más pequeño. Este mapa lineal es una operación matemática que transforma un conjunto de valores de entrada, en este caso los parámetros del modelo más pequeño, en un conjunto de valores de salida, en este caso los parámetros del modelo más grande.
Su método, que llaman Operador de Crecimiento Lineal Aprendido (LiGO), aprende a expandir la anchura y profundidad de una red más grande a partir de los parámetros de una red más pequeña de manera basada en datos.
Pero el modelo más pequeño puede ser en realidad bastante grande, tal vez tenga cien millones de parámetros, y los investigadores podrían querer hacer un modelo con mil millones de parámetros. Por lo tanto, la técnica LiGO descompone el mapa lineal en piezas más pequeñas que un algoritmo de aprendizaje automático puede manejar.
LiGO también expande la anchura y profundidad simultáneamente, lo que lo hace más eficiente que otros métodos. Un usuario puede ajustar la anchura y profundidad que desea que tenga el modelo más grande cuando ingresa el modelo más pequeño y sus parámetros, explica Kim.
Cuando compararon su técnica con el proceso de entrenar un nuevo modelo desde cero, así como con los métodos de crecimiento del modelo, fue más rápido que todos los puntos de referencia. Su método ahorra alrededor del 50 por ciento de los costos computacionales requeridos para entrenar modelos de visión y lenguaje, mientras que a menudo mejora el rendimiento.
Los investigadores también descubrieron que podían usar LiGO para acelerar el entrenamiento de transformadores incluso cuando no tenían acceso a un modelo pre-entrenado más pequeño.
“Me sorprendió cuánto mejor todos los métodos, incluido el nuestro, lo hicieron en comparación con los puntos de referencia de inicialización aleatoria y entrenamiento desde cero”, dice Kim.
En el futuro, Kim y sus colaboradores esperan aplicar LiGO a modelos aún más grandes.
El trabajo fue financiado, en parte, por el MIT-IBM Watson AI Lab, Amazon, el Centro de Hardware de Investigación de IA de IBM, el Centro de Innovación Computacional en el Instituto Politécnico Rensselaer, y la Oficina de Investigación del Ejército de los Estados Unidos.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Hoja de ayuda de Bard para Ciencia de Datos
- El papel de las herramientas de código abierto en la aceleración del progreso de la ciencia de datos
- Integrando ChatGPT en los flujos de trabajo de Ciencia de Datos Consejos y Mejores Prácticas
- Zepes News, 31 de mayo Bard para la Hoja de Trucos de Ciencia de Datos • Las 10 mejores herramientas para detectar ChatGPT, GPT-4, Bard y otros LLMs.
- Lenguajes de Programación para Roles de Datos Específicos
- 10 Consejos y Trucos de Jupyter Notebook para Científicos de Datos
- Zepes News, 7 de junio ChatGPT para hojas de trucos de entrevistas de ciencia de datos • Lenguajes de programación para roles de datos específicos.






