La normatividad espuria mejora el aprendizaje del comportamiento de cumplimiento y aplicación en agentes artificiales.
La normatividad espuria mejora el comportamiento de cumplimiento y aplicación en agentes artificiales.
En nuestro artículo reciente exploramos cómo el aprendizaje por refuerzo profundo multiagente puede servir como un modelo de interacciones sociales complejas, como la formación de normas sociales. Esta nueva clase de modelos podría proporcionar un camino para crear simulaciones más ricas y detalladas del mundo.
Los humanos somos una especie ultra social. En comparación con otros mamíferos, nos beneficiamos más de la cooperación, pero también dependemos más de ella y enfrentamos mayores desafíos de cooperación. Hoy en día, la humanidad enfrenta numerosos desafíos de cooperación, incluyendo evitar conflictos por recursos, asegurar que todos puedan acceder a aire limpio y agua potable, eliminar la extrema pobreza y combatir el cambio climático. Muchos de los problemas de cooperación que enfrentamos son difíciles de resolver porque involucran complejas redes de interacciones sociales y biofísicas llamadas sistemas socioecológicos. Sin embargo, los humanos pueden aprender colectivamente a superar los desafíos de cooperación que enfrentamos. Logramos esto a través de una cultura en constante evolución, que incluye normas e instituciones que organizan nuestras interacciones con el medio ambiente y entre nosotros.
Sin embargo, las normas e instituciones a veces no logran resolver los desafíos de cooperación. Por ejemplo, los individuos pueden sobreexplotar recursos como los bosques y las pesquerías, lo que provoca su colapso. En estos casos, los formuladores de políticas pueden escribir leyes para cambiar las reglas institucionales o desarrollar otras intervenciones para tratar de cambiar las normas con la esperanza de lograr un cambio positivo. Pero las intervenciones políticas no siempre funcionan como se pretende. Esto se debe a que los sistemas socioecológicos del mundo real son considerablemente más complejos que los modelos que normalmente usamos para tratar de predecir los efectos de las políticas propuestas.
Los modelos basados en la teoría de juegos se aplican a menudo al estudio de la evolución cultural. En la mayoría de estos modelos, las interacciones clave que los agentes tienen entre sí se expresan en una “matriz de pagos”. En un juego con dos participantes y dos acciones A y B, una matriz de pagos define el valor de los cuatro posibles resultados: (1) ambos elegimos A, (2) ambos elegimos B, (3) elijo A mientras tú eliges B y (4) elijo B mientras tú eliges A. El ejemplo más famoso es el “Dilema del prisionero”, en el que las acciones se interpretan como “cooperar” y “defecto”. Los agentes racionales que actúan de acuerdo con su propio interés egoísta están condenados a defectar en el dilema del prisionero, aunque el mejor resultado de la cooperación mutua está disponible.
- Modelos de Lenguaje de Red Teaming con Modelos de Lenguaje
- El primer paso de MuZero de la investigación al mundo real.
- Acelerando la ciencia de la fusión a través del control de plasma aprendido
Los modelos basados en la teoría de juegos se han aplicado ampliamente. Investigadores de diversos campos los han utilizado para estudiar una amplia gama de fenómenos diferentes, incluyendo economías y la evolución de la cultura humana. Sin embargo, la teoría de juegos no es una herramienta neutral, sino que es un lenguaje de modelado profundamente opinado. Impone un requisito estricto de que todo debe finalmente convertirse en términos de la matriz de pagos (o una representación equivalente). Esto significa que el modelador debe conocer, o estar dispuesto a asumir, todo sobre cómo los efectos de las acciones individuales se combinan para generar incentivos. Esto a veces es apropiado, y el enfoque de la teoría de juegos ha tenido muchos éxitos notables, como en la modelación del comportamiento de las empresas oligopólicas y las relaciones internacionales de la era de la Guerra Fría. Sin embargo, la mayor debilidad de la teoría de juegos como lenguaje de modelado se expone en situaciones en las que el modelador no comprende completamente cómo se combinan las elecciones de los individuos para generar pagos. Desafortunadamente, esto tiende a ser el caso con los sistemas socioecológicos porque sus partes sociales y ecológicas interactúan de formas complejas que no entendemos completamente.
El trabajo que presentamos aquí es un ejemplo dentro de un programa de investigación que intenta establecer un marco de modelado alternativo, diferente de la teoría de juegos, para su uso en el estudio de los sistemas socioecológicos. Nuestro enfoque puede verse formalmente como una variedad de modelado basado en agentes. Sin embargo, su característica distintiva es la incorporación de elementos algorítmicos de la inteligencia artificial, especialmente el aprendizaje por refuerzo profundo multiagente.
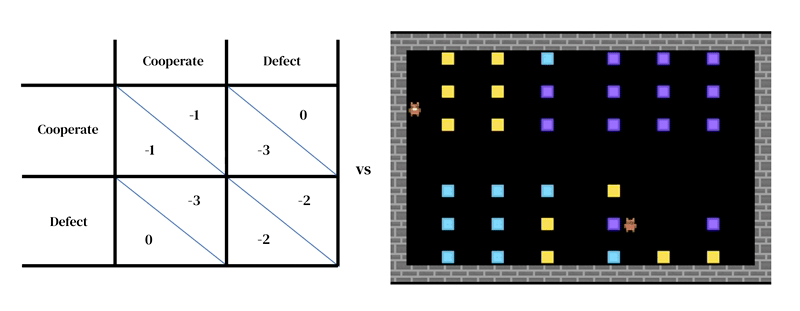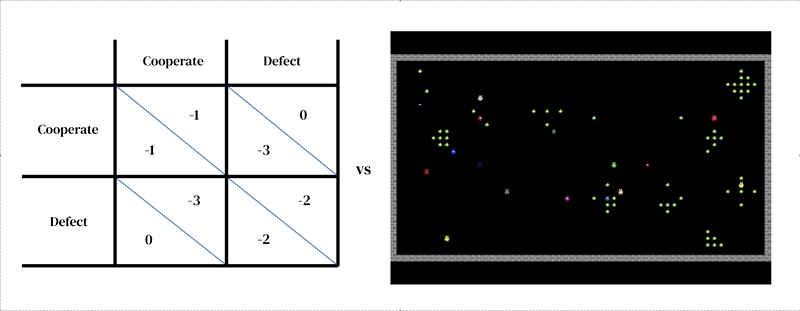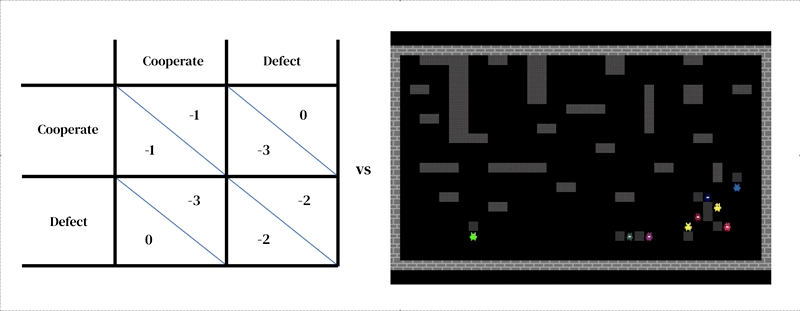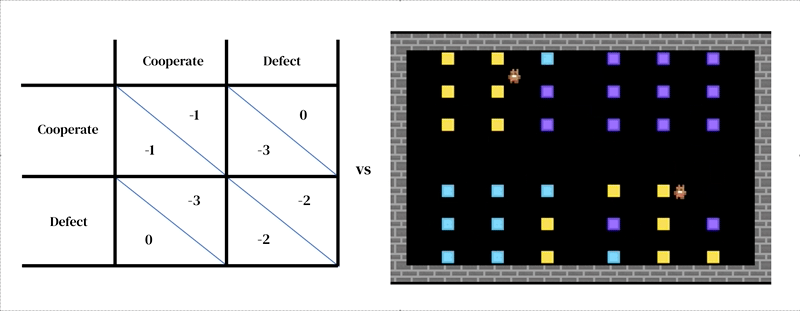
La idea central de este enfoque es que cada modelo consta de dos partes interconectadas: (1) un modelo dinámico y rico del entorno y (2) un modelo de toma de decisiones individuales.
El primero toma la forma de un simulador diseñado por el investigador: un programa interactivo que recibe un estado de entorno actual y las acciones de los agentes, y produce el siguiente estado de entorno, así como las observaciones de todos los agentes y sus recompensas instantáneas. El modelo de toma de decisiones individuales también se condiciona al estado del entorno. Es un agente que aprende a partir de su experiencia pasada, realizando una forma de prueba y error. Un agente interactúa con un entorno al recibir observaciones y producir acciones. Cada agente selecciona acciones de acuerdo con su política de comportamiento, que es una asignación de observaciones a acciones. Los agentes aprenden cambiando su política para mejorarla en cualquier dimensión deseada, típicamente para obtener más recompensas. La política se almacena en una red neuronal. Los agentes aprenden “desde cero”, a partir de su propia experiencia, cómo funciona el mundo y qué pueden hacer para obtener más recompensas. Logran esto ajustando los pesos de su red de manera que las imágenes que reciben como observaciones se transformen gradualmente en acciones competentes. Varios agentes de aprendizaje pueden habitar el mismo entorno entre ellos. En este caso, los agentes se vuelven interdependientes porque sus acciones se afectan mutuamente.
Al igual que otros enfoques de modelado basado en agentes, el aprendizaje profundo de refuerzo multiagente facilita la especificación de modelos que atraviesan niveles de análisis que serían difíciles de tratar con la teoría de juegos. Por ejemplo, las acciones pueden estar mucho más cerca de las primitivas motoras de bajo nivel (por ejemplo, ‘caminar hacia adelante’; ‘girar a la derecha’) que de las decisiones estratégicas de alto nivel de la teoría de juegos (por ejemplo, ‘cooperar’). Esta es una característica importante necesaria para capturar situaciones en las que los agentes deben practicar para aprender efectivamente cómo implementar sus elecciones estratégicas. Por ejemplo, en un estudio, los agentes aprendieron a cooperar turnándose para limpiar un río. Esta solución solo fue posible porque el entorno tenía dimensiones espaciales y temporales en las que los agentes tienen gran libertad para estructurar su comportamiento entre ellos. Curiosamente, aunque el entorno permitía muchas soluciones diferentes (como la territorialidad), los agentes convergieron en la misma solución de turnos que los jugadores humanos.
En nuestro último estudio, aplicamos este tipo de modelo a una pregunta abierta en la investigación sobre la evolución cultural: cómo explicar la existencia de normas sociales espurias y arbitrarias que parecen no tener consecuencias materiales inmediatas por su violación más allá de las impuestas socialmente. Por ejemplo, en algunas sociedades se espera que los hombres usen pantalones y no faldas; en muchas hay palabras o gestos que no deben usarse en compañía educada; y en la mayoría hay reglas sobre cómo peinarse o qué llevar en la cabeza. Llamamos a estas normas sociales ‘reglas absurdas’. Es importante destacar que, en nuestro marco de trabajo, tanto hacer cumplir como cumplir con las normas sociales deben ser aprendidos. Tener un entorno social que incluya una ‘regla absurda’ significa que los agentes tienen más oportunidades de aprender sobre el cumplimiento de normas en general. Esta práctica adicional les permite hacer cumplir las reglas importantes de manera más efectiva. En general, la ‘regla absurda’ puede ser beneficiosa para la población, un resultado sorprendente. Este resultado solo es posible porque nuestra simulación se centra en el aprendizaje: hacer cumplir y cumplir con las reglas son habilidades complejas que necesitan entrenamiento para desarrollarse.
Parte de la emoción que encontramos en este resultado sobre las reglas absurdas radica en que demuestra la utilidad del aprendizaje profundo de refuerzo multiagente en el modelado de la evolución cultural. La cultura contribuye al éxito o fracaso de las intervenciones políticas para los sistemas socioecológicos. Por ejemplo, fortalecer las normas sociales en torno al reciclaje es parte de la solución a algunos problemas ambientales. Siguiendo esta trayectoria, simulaciones más completas podrían llevar a una comprensión más profunda de cómo diseñar intervenciones para sistemas socioecológicos. Si las simulaciones se vuelven lo suficientemente realistas, incluso podría ser posible probar el impacto de las intervenciones, por ejemplo, buscar diseñar un código fiscal que fomente la productividad y la equidad.
Este enfoque proporciona a los investigadores herramientas para especificar modelos detallados de los fenómenos que les interesan. Por supuesto, al igual que todas las metodologías de investigación, se espera que tenga sus propias fortalezas y debilidades. Esperamos descubrir más sobre cuándo se puede aplicar de manera fructífera este estilo de modelado en el futuro. Si bien no existen soluciones milagrosas para el modelado, creemos que hay razones convincentes para recurrir al aprendizaje profundo de refuerzo multiagente al construir modelos de fenómenos sociales, especialmente cuando involucran aprendizaje.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Prediciendo el pasado con Ithaca
- GopherCite Enseñando a los modelos de lenguaje a respaldar respuestas con citas verificadas
- Un análisis empírico del entrenamiento de modelos de lenguaje grandes óptimos en cómputo
- La última investigación de DeepMind en ICLR 2022
- Comenzando con JAX
- Selección activa de políticas sin conexión.
- Un agente generalista






