Difusión estable Intuición básica detrás de la IA generativa
La intuición básica detrás de la IA generativa es la difusión estable.
Este artículo proporciona una visión general de Stable Diffusion y se centra en desarrollar una comprensión básica de cómo funciona la inteligencia artificial generativa.

Introducción
El mundo de la IA ha cambiado drásticamente hacia el modelado generativo en los últimos años, tanto en Visión por Computadora como en Procesamiento del Lenguaje Natural. Dalle-2 y Midjourney han captado la atención de las personas, llevándolas a reconocer el trabajo excepcional que se está llevando a cabo en el campo de la IA Generativa.
La mayoría de las imágenes generadas por IA actualmente producidas se basan en Modelos de Difusión como su fundamento. El objetivo de este artículo es aclarar algunos de los conceptos que rodean la Difusión Estable y ofrecer una comprensión fundamental de la metodología empleada.
- Construyendo Modelos de Lenguaje Una Guía de Implementación Paso a Paso de BERT
- Generar música a partir de texto utilizando Google MusicLM
- LangFlow | Interfaz de usuario para LangChain para desarrollar aplicaciones con LLMs
Arquitectura Simplificada
Este diagrama de flujo muestra la versión simplificada de una arquitectura de Difusión Estable. Lo recorreremos pieza por pieza para construir una mejor comprensión de su funcionamiento interno. Elaboraremos sobre el proceso de entrenamiento para una mejor comprensión, con cambios sutiles en la inferencia.
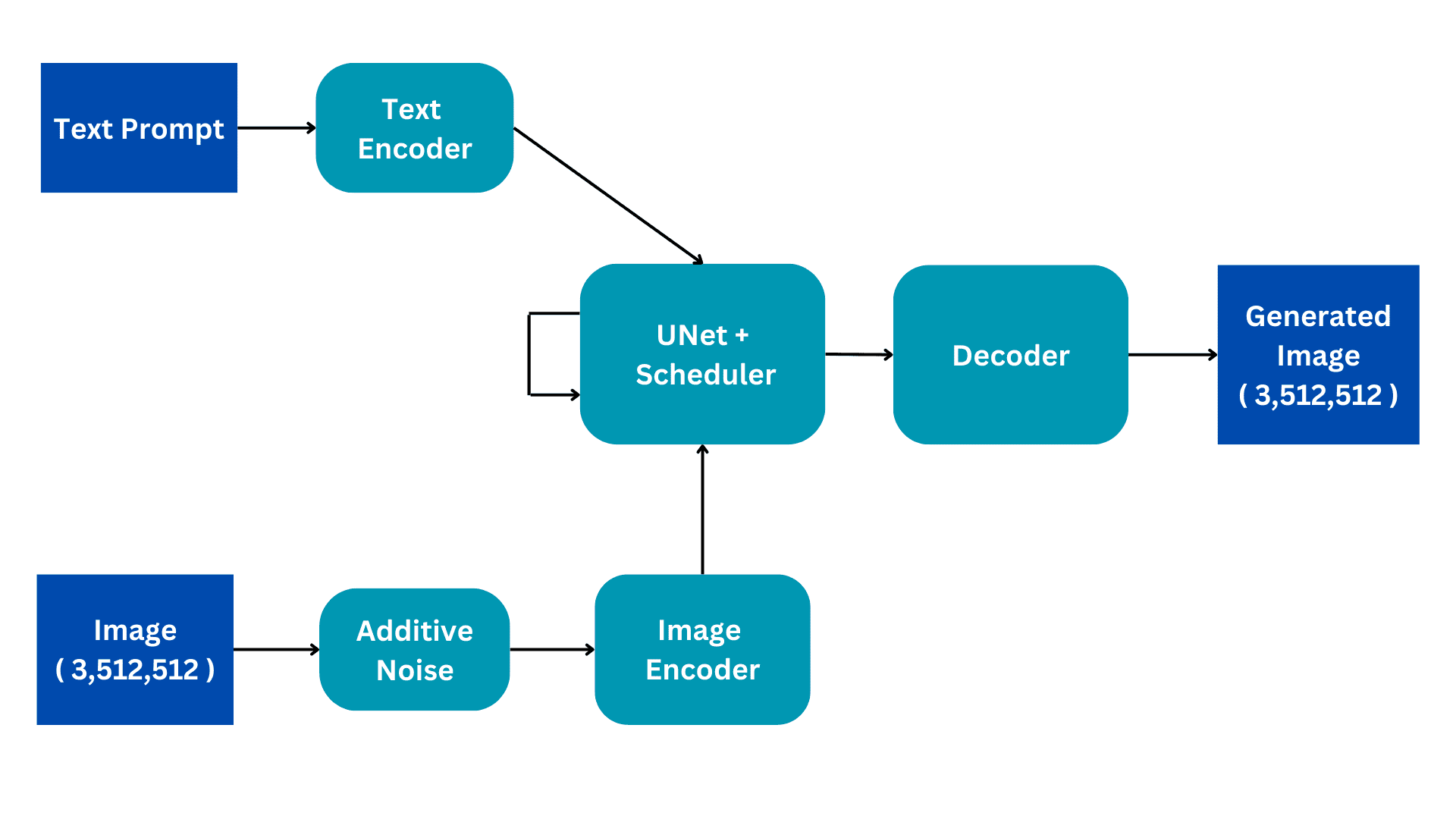
Entradas
Los modelos de Difusión Estable se entrenan en conjuntos de datos de Descripción de Imágenes en los que cada imagen tiene una descripción asociada o una indicación que describe la imagen. Por lo tanto, el modelo tiene dos entradas: una indicación textual en lenguaje natural y una imagen de tamaño (3,512,512) con 3 canales de color y dimensiones de tamaño 512.
Ruido Aditivo
La imagen se convierte en ruido completo mediante la adición de ruido gaussiano a la imagen original. Esto se hace en pasos consecutivos, por ejemplo, se agrega una pequeña cantidad de ruido a la imagen durante 50 pasos consecutivos hasta que la imagen esté completamente ruidosa. El proceso de difusión tiene como objetivo eliminar este ruido y reproducir la imagen original. Cómo se hace esto se explicará más adelante.
Codificador de Imágenes
El codificador de imágenes funciona como un componente de un Autoencoder Variacional, convirtiendo la imagen en un ‘espacio latente’ y redimensionándola a dimensiones más pequeñas, como (4, 64, 64), al mismo tiempo que incluye una dimensión de lote adicional. Este proceso reduce los requisitos computacionales y mejora el rendimiento. A diferencia de los modelos de difusión originales, la Difusión Estable incorpora el paso de codificación en la dimensión latente, lo que resulta en una reducción de la computación, así como en una disminución del tiempo de entrenamiento e inferencia.
Codificador de Texto
La indicación en lenguaje natural se transforma en una incrustación vectorizada por el codificador de texto. Este proceso emplea un modelo de lenguaje basado en Transformadores, como BERT o modelos de texto basados en GPT-CLIP. Los modelos mejorados de codificación de texto mejoran significativamente la calidad de las imágenes generadas. La salida resultante del codificador de texto consiste en una matriz de vectores de incrustación de 768 dimensiones para cada palabra. Para controlar la longitud de la indicación, se establece un límite máximo de 77. Como resultado, el codificador de texto produce un tensor con dimensiones de (77, 768).
UNet
Esta es la parte más computacionalmente costosa de la arquitectura y aquí ocurre el procesamiento principal de difusión. Recibe como entrada la codificación de texto y la imagen latente ruidosa. Este módulo tiene como objetivo reproducir la imagen original a partir de la imagen ruidosa que recibe. Esto se logra a través de varios pasos de inferencia que se pueden establecer como hiperparámetros. Normalmente, 50 pasos de inferencia son suficientes.
Consideremos un escenario simple donde una imagen de entrada se transforma en ruido al introducir gradualmente pequeñas cantidades de ruido en 50 pasos consecutivos. Esta adición acumulativa de ruido eventualmente transforma la imagen original en ruido completo. El objetivo de la UNet es revertir este proceso al predecir el ruido agregado en el paso anterior. Durante el proceso de eliminación de ruido, la UNet comienza prediciendo el ruido agregado en el paso 50 para el paso inicial. Luego, resta este ruido predicho de la imagen de entrada y repite el proceso. En cada paso subsiguiente, la UNet predice el ruido agregado en el paso anterior, restaurando gradualmente la imagen de entrada original a partir del ruido completo. A lo largo de este proceso, la UNet se basa internamente en el vector de incrustación textual como factor condicionante.
La UNet produce un tensor de tamaño (4, 64, 64) que se pasa a la parte del decodificador del Autoencoder Variacional.
Decodificador
El decodificador revierte la conversión de la representación latente realizada por el codificador. Toma una representación latente y la convierte de nuevo al espacio de la imagen. Por lo tanto, produce una imagen de tamaño (3,512,512), del mismo tamaño que el espacio de entrada original. Durante el entrenamiento, nuestro objetivo es minimizar la pérdida entre la imagen original y la imagen generada. Dado eso, dado una indicación textual, podemos generar una imagen relacionada con la indicación a partir de una imagen completamente ruidosa.
Uniendo todo
En la inferencia, no tenemos una imagen de entrada. Trabajamos solo en el modo de texto a imagen. Eliminamos la parte de Ruido Aditivo y en su lugar usamos un tensor generado aleatoriamente del tamaño requerido. El resto de la arquitectura se mantiene igual.
El UNet ha sido entrenado para generar una imagen a partir de ruido completo, aprovechando la incrustación de texto como indicador. Esta entrada específica se utiliza durante la etapa de inferencia, lo que nos permite generar imágenes sintéticas exitosamente a partir del ruido. Este concepto general sirve como la intuición fundamental detrás de todos los modelos generativos de visión por computadora. Muhammad Arham es un Ingeniero de Aprendizaje Profundo que trabaja en Visión por Computadora y Procesamiento de Lenguaje Natural. Ha trabajado en la implementación y optimización de varias aplicaciones de IA generativa que llegaron a los principales rankings globales en Vyro.AI. Le interesa construir y optimizar modelos de aprendizaje automático para sistemas inteligentes y cree en la mejora continua.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Conoce a ChatGLM2-6B la versión de segunda generación del modelo de chat de código abierto bilingüe (chino-inglés) ChatGLM-6B.
- Una Introducción a la Ingeniería de Prompt
- MosaicML acaba de lanzar su MPT-30B bajo la licencia Apache 2.0.
- ¿Qué es Machine Learning como Servicio? Beneficios y principales plataformas de MLaaS.
- Las GPUs NVIDIA H100 establecen el estándar para la IA generativa en el primer benchmark MLPerf.
- La carrera para evitar el peor escenario para el aprendizaje automático
- 8 cosas potencialmente sorprendentes que debes saber sobre los Modelos de Lenguaje Grandes (LLMs)






