La Evolución de los Datos Tabulares Desde el Análisis hasta la IA
La Evolución de los Datos Tabulares de Análisis a IA
Descubre cómo el espacio de datos tabulares está siendo transformado por las competencias de Kaggle, la comunidad de código abierto y la inteligencia artificial generativa.

Introducción
Los datos tabulares se refieren a los datos organizados en filas y columnas. Esto abarca desde archivos CSV y hojas de cálculo hasta bases de datos relacionales. Los datos tabulares han existido durante décadas y son uno de los tipos de datos más comunes utilizados en el análisis de datos y el aprendizaje automático.
Tradicionalmente, los datos tabulares se han utilizado simplemente para organizar e informar información. Sin embargo, en la última década, su uso ha evolucionado significativamente debido a varios factores clave:
- Competencias de Kaggle: Kaggle surgió en 2010 [1] y popularizó la ciencia de datos y las competencias de aprendizaje automático utilizando conjuntos de datos tabulares del mundo real. Esto expuso a muchos científicos de datos e ingenieros de aprendizaje automático al poder de analizar y construir modelos en datos tabulares.
- Contribuciones de código abierto: Gracias a importantes bibliotecas de código abierto como Pandas, DuckDB, SDV y Scikit-learn, manipular, preprocesar y construir modelos predictivos en datos tabulares ahora es increíblemente fácil. Además, los conjuntos de datos de código abierto brindan a los principiantes un acceso fácil para practicar con conjuntos de datos del mundo real.
- Inteligencia artificial generativa: Los avances recientes en inteligencia artificial generativa, especialmente los grandes modelos de lenguaje, ahora permiten la generación de datos tabulares realistas y facilitan a prácticamente cualquier persona realizar análisis de datos y construir aplicaciones de aprendizaje automático.
En el ensayo, discutiremos cada uno de estos factores con más detalle y veremos ejemplos de cómo las empresas e investigadores están utilizando datos tabulares de formas innovadoras en la actualidad. La conclusión principal será la importancia de analizar y preparar los datos tabulares de la manera correcta para aprovechar los beneficios del aprendizaje automático y la inteligencia artificial.
Este ensayo es parte del Informe de AI de Kaggle 2023, una competencia en la que los participantes escriben un ensayo sobre uno de los siete temas. La consigna les pide que describan lo que la comunidad ha aprendido en los últimos dos años de trabajo y experimentación.
Competencias de Datos Tabulares de Kaggle
La Competencia de Kaggle ha tenido un profundo impacto en el campo de la ciencia de datos y de la ingeniería de aprendizaje automático. Además, las competencias tabulares han introducido nuevas técnicas, herramientas y diversas tareas tabulares.
Además del aprendizaje y desarrollo de conocimientos, ganar competencias a menudo conlleva premios en efectivo, lo que proporciona una mayor motivación para participar. Por ejemplo:
- En promedio, las competencias de Kaggle ofrecen premios en efectivo de alrededor de $21,246 y tienen aproximadamente 1,498 equipos participantes.
- Los premios en efectivo más grandes han llegado a ser de hasta $125,000, lo que ofrece a los ganadores un incentivo significativo para esforzarse aún más y ampliar los límites de lo que es posible con los datos tabulares.
Nota: Utilizaremos el conjunto de datos Meta Kaggle para nuestro análisis y ejemplos de código. El conjunto de datos está bajo licencia Apache 2.0 y se actualiza diariamente.
import pandas as pdcomptags = pd.read_csv("/kaggle/input/meta-kaggle/CompetitionTags.csv")tags = pd.read_csv("/kaggle/input/meta-kaggle/Tags.csv")comps = pd.read_csv("/kaggle/input/meta-kaggle/Competitions.csv")tabular_competition_ids = comptags.query("TagId == 14101")['CompetitionId']tabular_competitions = comps.set_index('Id').loc[tabular_competition_ids]tabular_competitions.describe()[["RewardQuantity","TotalTeams"]]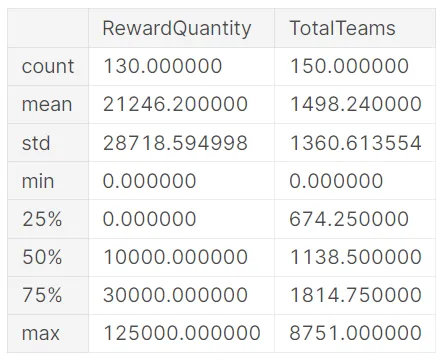
En la última década, Kaggle ha organizado numerosas competencias centradas en datos tabulares, y varias desde 2015 ofrecen premios en efectivo de hasta $100,000 para el equipo ganador.
import plotly.express as pxtabular_competitions["EnabledDate"] = pd.to_datetime( tabular_competitions["EnabledDate"], format="%m/%d/%Y %H:%M:%S")tabular_competitions["EnabledDate"] = tabular_competitions["EnabledDate"].dt.yeartabular_competitions.sort_values(by="EnabledDate", inplace=True)fig = px.bar( tabular_competitions, x="EnabledDate", y="RewardQuantity", title="Distribución de Premios de las Competencias Tabulares a lo largo de los Años", labels={"RewardQuantity": "Dinero del Premio($)", "EnabledDate": "Año"},)fig.show()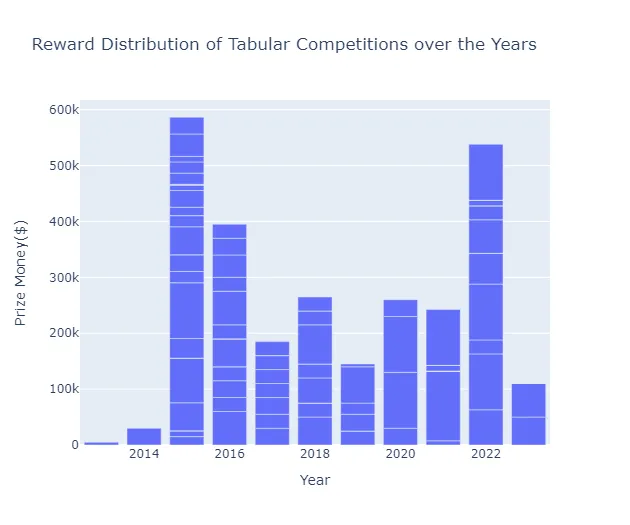
El número de competencias de datos tabulares ha crecido significativamente durante este período, con una actividad particularmente alta en 2015 y 2022.
fig = px.histogram( tabular_competitions, x="EnabledDate", nbins=20, title="Número de competencias tabulares a lo largo de los años", labels={"EnabledDate": "Año"},)fig.show()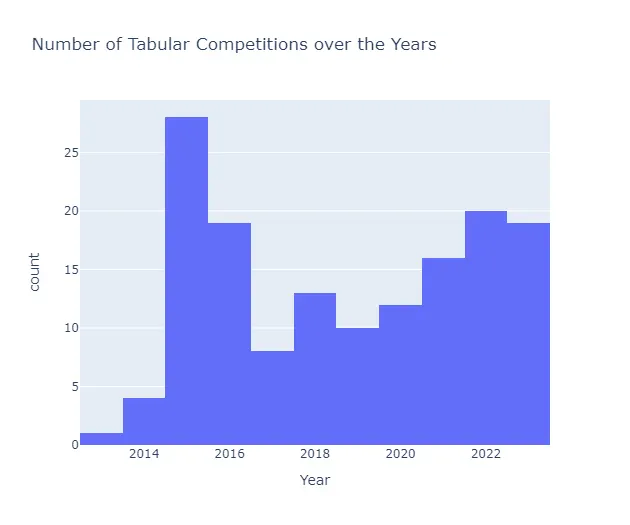
Serie de juegos de datos tabulares
Debido a la gran demanda de problemas de datos tabulares, el personal de Kaggle inició un experimento en 2021 [2] lanzando un concurso mensual llamado Serie de Juegos de Datos Tabulares. Estas competencias tenían como objetivo proporcionar una plataforma consistente para que los competidores perfeccionaran sus habilidades en datos tabulares.
Las competencias de la Serie de Juegos de Datos Tabulares se basaban en conjuntos de datos sintéticos que replicaban la estructura de datos públicos o datos de competencias anteriores de Kaggle. Los conjuntos de datos sintéticos se crearon utilizando una red generativa de aprendizaje profundo llamada CTGAN.[3]
- Exposición: Muchos practicantes de aprendizaje automático tuvieron su primer contacto con el trabajo en datos tabulares a través de la Serie de Juegos de Datos Tabulares. Esto les ayudó a familiarizarse con conceptos como carga de datos, ingeniería de características y ajuste de modelos.
- Técnicas: Las competencias de Kaggle mostraron técnicas como la ingeniería de características, la ampliación de datos y la modelización en conjunto que son particularmente útiles para datos tabulares. Los competidores utilizaron estas técnicas para obtener puntuaciones más altas, estableciendo ejemplos para otros.
- Comunidad: Las discusiones dentro de las competencias de Kaggle proporcionaron un terreno fértil para compartir técnicas e ideas sobre cómo manejar mejor los datos tabulares. Esto ayudó a formar una comunidad de práctica en torno a los datos tabulares.
- Democratización: Las competencias de Kaggle han hecho que el aprendizaje automático en datos tabulares sea más accesible para un público más amplio, no solo para expertos en datos. Los participantes tienen acceso gratuito tanto a CPU como a GPU, así como a conjuntos de datos grandes, y cualquiera puede participar en la competencia.
La Serie de Juegos de Datos Tabulares aún está en curso, actualmente en la Temporada 3 con el Episodio 18. Esto demuestra que los premios en efectivo no son la única motivación para los participantes, ya que estas competencias no ofrecen premios monetarios ni sistemas de puntuación. En cambio, la serie se dedica a entusiastas de los datos que desean perfeccionar sus habilidades practicando diversos tipos de datos tabulares.
Soluciones de la competencia
El examen de las soluciones ganadoras ha revelado que no es necesario utilizar herramientas sofisticadas o modelos de aprendizaje profundo para obtener altas posiciones. Incluso modelos más simples como la regresión lineal, con una cuidadosa ingeniería de características, pueden ganar premios. La clave está en encontrar técnicas simples pero efectivas para resolver el problema dado.
Por ejemplo, el ganador [4] de la competencia de Pronóstico de Densidad de Microempresas de GoDaddy [5] utilizó la Regresión Lineal. Esto no es sorprendente, ya que las soluciones ganadoras a menudo se basan en modelos simples pero implican una extensa selección de características, validación cruzada, ampliación de datos y técnicas de conjunto.
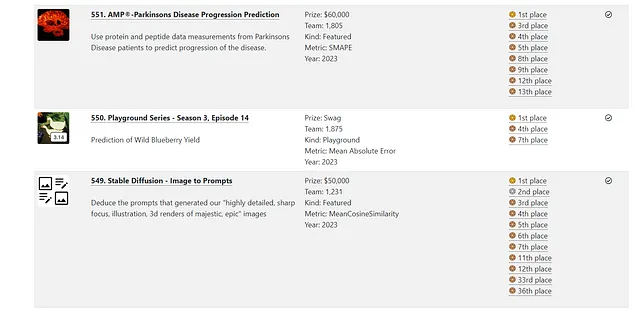
Contribuciones de código abierto relacionadas con datos tabulares
Las contribuciones de código abierto relacionadas con datos tabulares han sido invaluables para avanzar en el campo y permitir aplicaciones del mundo real. Las contribuciones se dividen en dos categorías principales:
- Conjuntos de datos de código abierto
- Herramientas de código abierto
Conjuntos de datos de código abierto
Kaggle debe su éxito a las generosas contribuciones de colaboradores de código abierto que comparten conjuntos de datos tabulares del mundo real para problemas de aprendizaje automático. Estos conjuntos de datos, que abarcan diversos dominios y casos de uso, proporcionan datos valiosos para el entrenamiento y la evaluación de modelos en la comunidad de aprendizaje automático. Numerosas empresas y organizaciones han compartido abiertamente sus datos tabulares propietarios para impulsar el avance en este campo. La cantidad y diversidad de conjuntos de datos disponibles en Kaggle han sido un impulsor fundamental para la innovación en el trabajo con datos tabulares.
El conjunto de datos de Kaggle [6] es el lugar de referencia tanto para principiantes como para expertos que buscan conjuntos de datos específicos. Su amplia colección de conjuntos de datos tabulares ayuda a cientos de miembros de la comunidad a practicar nuevas técnicas y manejar nuevos tipos de datos a diario.
Herramientas de código abierto
Las comunidades de desarrolladores han hecho posible varias herramientas de código abierto importantes para analizar, manipular y modelar datos tabulares. Herramientas como Pandas, Numpy, scikit-learn, TensorFlow, XGBoost y muchas otras han sido elementos clave para trabajar con datos tabulares a gran escala. Estas bibliotecas proporcionan un conjunto completo de funcionalidades que han permitido que el aprendizaje automático con datos tabulares sea accesible para una amplia audiencia. Las contribuciones continuas de la comunidad aseguran que estas herramientas sigan mejorando y se mantengan al día con los nuevos requisitos.
Además, ahora existen herramientas eficientes como DuckDB y PySpark, que ofrecen una forma fácil de usar pero poderosa para analizar y procesar grandes conjuntos de datos tabulares.
%pip install duckdb -qCon DuckDB, puedes importar fácilmente un archivo CSV y ejecutar consultas SQL en cuestión de segundos.
import duckdbduckdb.sql('SELECT * FROM "/kaggle/input/meta-kaggle/Competitions.csv" LIMIT 5')
┌───────┬────────────────┬──────────────────────┬───┬──────────────────────┬──────────┬───────────────────┐│ Id │ Slug │ Title │ … │ EnableSubmissionMo… │ HostName │ CompetitionTypeId ││ int64 │ varchar │ varchar │ │ boolean │ varchar │ int64 │├───────┼────────────────┼──────────────────────┼───┼──────────────────────┼──────────┼───────────────────┤│ 2408 │ Eurovision2010 │ Forecast Eurovisio… │ … │ false │ NULL │ 1 ││ 2435 │ hivprogression │ Predict HIV Progre… │ … │ false │ NULL │ 1 ││ 2438 │ worldcup2010 │ World Cup 2010 - T… │ … │ false │ NULL │ 1 ││ 2439 │ informs2010 │ INFORMS Data Minin… │ … │ false │ NULL │ 1 ││ 2442 │ worldcupconf │ World Cup 2010 - C… │ … │ false │ NULL │ 1 │├───────┴────────────────┴──────────────────────┴───┴──────────────────────┴──────────┴───────────────────┤│ 5 filas 42 columnas (6 mostradas) │└─────────────────────────────────────────────────────────────────────────────────────────────────────────┘Realiza acciones rápidas y múltiples en datos tabulares utilizando la API relacional de Python. Su sintaxis es similar a la de pandas, lo que facilita su uso.
rel = duckdb.read_csv('/kaggle/input/meta-kaggle/Competitions.csv')rel.filter("RewardQuantity > 100000").project( "EnabledDate,RewardQuantity").order("RewardQuantity").limit(5)
┌─────────────────────┬────────────────┐│ EnabledDate │ RewardQuantity ││ varchar │ double │├─────────────────────┼────────────────┤│ 07/25/2019 21:10:14 │ 120000.0 ││ 11/02/2021 16:00:27 │ 125000.0 ││ 11/14/2016 08:02:32 │ 150000.0 ││ 11/22/2021 18:53:57 │ 150000.0 ││ 05/11/2022 18:46:43 │ 150000.0 │└─────────────────────┴────────────────┘Inteligencia Artificial Generativa para Datos Tabulares
La Inteligencia Artificial Generativa es un subcampo de la inteligencia artificial impulsado por redes neuronales como los Autoencoders Variacionales y las Redes Generativas Antagónicas (GANs) que pueden generar imágenes fotorrealistas, componer piezas originales de música, escribir artículos de noticias e historias e incluso diseñar objetos. Estos modelos se entrenan en conjuntos de datos grandes, lo que les permite descubrir los patrones subyacentes, las estructuras y las distribuciones estadísticas presentes en los datos.
Los modelos de Inteligencia Artificial Generativa han avanzado significativamente en el campo de trabajo con datos tabulares. Capacidades como la ampliación de datos, la detección de anomalías y la generación de datos sintéticos han ayudado a abordar problemas como la escasez de datos, la privacidad y el sesgo.
Sin embargo, los avances recientes como ChatGPT y otros modelos de lenguaje grandes (LLMs) también se están utilizando ahora como asistentes para tareas de datos tabulares. Algunas de las formas en que la Inteligencia Artificial Generativa está transformando nuestros flujos de trabajo incluyen:
- Asistencia en código: Los LLMs como ChatGPT pueden ayudar con tareas de codificación como la ingeniería de características, el preprocesamiento, la modelización y la evaluación de tuberías de aprendizaje automático para datos tabulares. Pueden sugerir fragmentos de código, funciones y scripts completos.
- Comprensión de datos: La Inteligencia Artificial Generativa puede proporcionar información sobre las distribuciones de datos, las correlaciones, los valores faltantes, los valores atípicos, las variables objetivo y más.
- Análisis profundo: Realiza pruebas estadísticas, crea visualizaciones y obtiene otras métricas resumidas que brindan a los profesionales un análisis exhaustivo de conjuntos de datos tabulares para informar las decisiones de modelado.
- Web scraping: Las herramientas de Inteligencia Artificial Generativa pueden ayudarte a obtener nuevos datos tabulares de sitios web/aplicaciones, asistiendo en tareas de adquisición de datos.
Aunque persisten problemas como la seguridad, el sesgo y las capacidades limitadas, los modelos de lenguaje grandes están comenzando a transformar la forma en que los científicos de datos e ingenieros de aprendizaje automático trabajan con datos tabulares en su día a día. Cada vez más se convierten en asistentes que manejan diversas tareas analíticas y de codificación, liberando a los profesionales para centrarse en trabajos de nivel superior.
ChatGPT para Datos Tabulares
ChatGPT [7] se ha convertido rápidamente en un asistente invaluable para casi todas las etapas de trabajo con datos tabulares, desde ayudar con la limpieza de datos y la ingeniería de características hasta generar código de modelo complejo, interpretar métricas, producir informes de análisis de datos e incluso ayudar en la generación de datos sintéticos para tareas como la ampliación de datos y la detección de anomalías.
Con ChatGPT, puedes construir y entrenar fácilmente un modelo de aprendizaje automático simplemente escribiendo una descripción detallada. Además, puedes utilizar múltiples complementos para automatizar tareas complejas como ejecutar el código y acceder a internet.
Consulta “Una guía para usar ChatGPT en proyectos de ciencia de datos” [8] para aprender cómo utilizar ChatGPT en un proyecto de ciencia de datos de principio a fin.
Herramientas de Inteligencia Artificial Generativa para Datos Tabulares
Las herramientas de Inteligencia Artificial Generativa, como PandasAI [9], han facilitado enormemente el análisis de datos, la limpieza de conjuntos de datos y la visualización de datos para cualquier persona. Estas herramientas utilizan modelos de lenguaje grandes como gpt-3.5-turbo [10] para generar resultados perspicaces. Además, también puedes conectarte con modelos de código abierto alojados en Hugging Face para realizar análisis de IA.
%pip install pandasai -q
from kaggle_secrets import UserSecretsClientfrom pandasai import PandasAIfrom pandasai.llm.openai import OpenAIuser_secrets = UserSecretsClient()secret_value_0 = user_secrets.get_secret("OPENAI_API_KEY")llm = OpenAI(api_token=secret_value_0)pandas_ai = PandasAI(llm)Para ver las cinco principales competiciones con la mayor RewardQuantity, le pedimos a ChatGPT que las muestre escribiendo una indicación.
pandas_ai.run(tabular_competitions, prompt='¿Puedes proporcionar una lista de las cinco principales competiciones con la mayor RewardQuantity? Por favor, muestra solo el nombre de la competición, la fecha y la recompensa correspondiente.')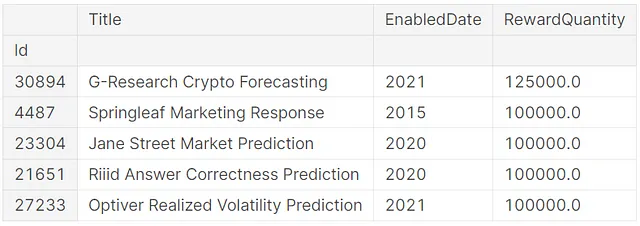
Incluso puedes pedirle que realice tareas complejas o genere visualizaciones.
pandas_ai.run(tabular_competitions, prompt='Por favor, enumera todas las competencias que contengan "Market".')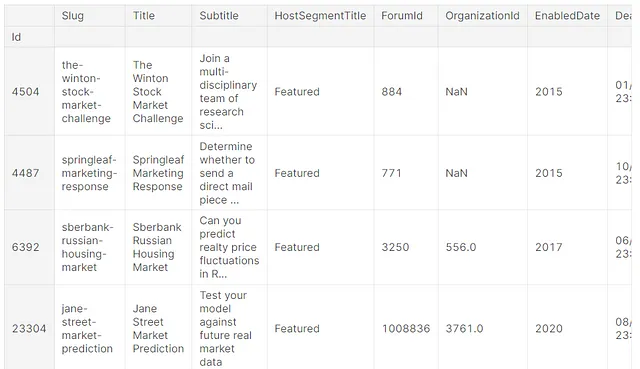
Esto es solo el comienzo, ya que veremos muchas nuevas herramientas de IA que facilitarán la vida de los científicos de datos y desarrolladores al automatizar tareas y proporcionar asistencia.
Conclusión
Aunque se ha logrado un progreso significativo en el aprovechamiento de datos tabulares para aplicaciones de aprendizaje automático e IA, es probable que solo hayamos visto el comienzo. En el futuro, podemos esperar nuevas herramientas potentes impulsadas por agentes de IA avanzados [11] que automatizarán todo el flujo de trabajo para tareas de aprendizaje automático tabulares, desde la ingestión y limpieza de datos hasta la ingeniería de características, entrenamiento de modelos, evaluación e implementación en aplicaciones web. Con los avances continuos en IA generativa y procesamiento de lenguaje natural, estos agentes podrán recibir indicaciones de alto nivel para completar proyectos completos de ciencia de datos tabulares, desde los datos hasta las ideas.
Este ensayo destaca el impacto significativo de las competiciones de Kaggle, las comunidades de código abierto y la IA generativa en nuestro enfoque para trabajar con datos tabulares en tareas como el análisis de datos y el aprendizaje automático. Para profundizar en el tema, puedes leer los ensayos ganadores del concurso Kaggle AI Report 2023.[12]
Referencia
[1] Colaboradores de Wikipedia, “Kaggle,” Wikipedia, junio 2023, [En línea]. Disponible: https://es.wikipedia.org/wiki/Kaggle
[2] “Tabular Playground Series – Jan 2021 | Kaggle.” https://www.kaggle.com/competitions/tabular-playground-series-jan-2021
[3] Sdv-Dev, “GitHub – sdv-dev/CTGAN: Conditional GAN for generating synthetic tabular data.,” GitHub. https://github.com/sdv-dev/CTGAN
[4] KAGGLEQRDL, “#1 solution – generalization with linear regression,” 16 de marzo de 2023. https://www.kaggle.com/competitions/godaddy-microbusiness-density-forecasting/discussion/395131
[5] “GoDaddy – Microbusiness Density Forecasting | Kaggle,” 15 de diciembre de 2022. https://www.kaggle.com/competitions/godaddy-microbusiness-density-forecasting/overview
[6] “Encuentra conjuntos de datos abiertos y proyectos de aprendizaje automático | Kaggle.” https://www.kaggle.com/datasets
[7] “Presentando ChatGPT,” OpenAI, noviembre 2022. https://openai.com/blog/chatgpt
[8] A. A. Awan, “Una guía para usar ChatGPT en proyectos de ciencia de datos,” marzo de 2023, [En línea]. Disponible: https://www.datacamp.com/tutorial/chatgpt-data-science-projects
[9] Gventuri, “GitHub – gventuri/pandas-ai: Pandas AI es una biblioteca de Python que integra capacidades de inteligencia artificial generativa en Pandas, haciendo que los dataframes sean conversacionales,” GitHub. https://github.com/gventuri/pandas-ai
[10] “GPT-3.5,” OpenAI. https://platform.openai.com/docs/models/gpt-3-5
[11] R. Cotton, “Introducción a los agentes de IA: comenzando con Auto-GPT, AgentGPT y BabyAGI,” mayo de 2023, [En línea]. Disponible: https://www.datacamp.com/tutorial/introduction-to-ai-agents-autogpt-agentgpt-babyagi
[12] “Informe de IA de Kaggle 2023.” mayo de 2023, [En línea]. Disponible: https://www.kaggle.com/competitions/2023-kaggle-ai-report/leaderboard
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Las complejidades de la implementación de la resolución de entidades
- La IA generativa impulsa una nueva era en la industria automotriz, desde el diseño y la ingeniería hasta la producción y las ventas
- Visual Effects Multiplier Wylie Co. apuesta todo por el rendimiento de GPU para obtener ganancias de 24 veces
- Superando los límites del análisis de datos con SQL en S4 HANA y Domo Una perspectiva de Aprendizaje Automático
- Top 50 Herramientas de Escritura de IA para Probar (Agosto 2023)
- Presentando el plan de estudios del Bootcamp ODSC West comienza ahora
- Construye aplicaciones de IA generativa listas para producción para la búsqueda empresarial utilizando tuberías de Haystack y Amazon SageMaker JumpStart con LLMs






