Tendencias laborales en análisis de datos IA en análisis de las tendencias laborales
Tendencias laborales en el análisis de datos de IA Un análisis de las tendencias laborales
Por Mahantesh Pattadkal y Andrea De Mauro
La analítica de datos ha experimentado un notable crecimiento en los últimos años, impulsado por los avances en la forma en que los datos se utilizan en los procesos de toma de decisiones clave. La recopilación, almacenamiento y análisis de datos también han progresado significativamente debido a estos desarrollos. Además, la demanda de talento en analítica de datos ha aumentado considerablemente, convirtiendo el mercado laboral en una arena altamente competitiva para las personas que poseen las habilidades y experiencia necesarias.
La rápida expansión de las tecnologías basadas en datos ha llevado a un aumento en la demanda de roles especializados, como “ingeniero de datos”. Este aumento en la demanda se extiende más allá de la ingeniería de datos en sí misma e incluye posiciones relacionadas como científico de datos y analista de datos.
Reconociendo la importancia de estas profesiones, nuestra serie de entradas de blog tiene como objetivo recopilar datos del mundo real de publicaciones de empleo en línea y analizarlos para comprender la naturaleza de la demanda de estos trabajos, así como las diversas habilidades requeridas dentro de cada una de estas categorías.
- SQL en Pandas con Pandasql
- VoAGI Noticias, 5 de octubre 5 libros gratuitos para ayudarte a dominar Python • Los 7 mejores cuadernos de nube gratuitos para Ciencia de Datos
- Combatir la suplantación de identidad por la IA
En este blog, presentamos una aplicación basada en el navegador llamada “Tendencias de empleos en analítica de datos” para la visualización y análisis de las tendencias de empleo en el mercado de la analítica de datos. Después de extraer datos de las agencias de empleo en línea, utiliza técnicas de procesamiento del lenguaje natural (NLP) para identificar las habilidades clave requeridas en las publicaciones de empleo. La Figura 1 muestra una captura de pantalla de la aplicación de datos, explorando las tendencias en el mercado laboral de la analítica de datos.

Para la implementación, adoptamos la plataforma de ciencia de datos de bajo código: Plataforma KNIME Analytics. Esta plataforma de ciencia de datos de código abierto y gratuita se basa en la programación visual y ofrece una amplia gama de funcionalidades, desde operaciones de extracción, transformación y carga (ETL) hasta una amplia variedad de conectores de origen de datos para la combinación de datos, así como algoritmos de aprendizaje automático, incluido el aprendizaje profundo.
El conjunto de flujos de trabajo que respaldan la aplicación está disponible para su descarga gratuita en el KNIME Community Hub en “Tendencias de empleo en analítica de datos”. Una instancia basada en navegador se puede evaluar en “Tendencias de empleo en analítica de datos”.
Aplicación “Tendencias de empleo en analítica de datos”
Esta aplicación está generada por cuatro flujos de trabajo que se muestran en la Figura 2 y se ejecutan secuencialmente para la siguiente secuencia de pasos:
- Web scraping para recopilación de datos
- Análisis sintáctico y limpieza de datos (NLP)
- Modelado de temas
- Análisis de atribución de roles de trabajo: habilidades
Los flujos de trabajo están disponibles en el Espacio Público del KNIME Community Hub en “Tendencias de empleo en analítica de datos”.

- El flujo de trabajo “01_Web Scraping para recopilación de datos” navega por las publicaciones de empleo en línea y extrae la información textual en un formato estructurado
- El flujo de trabajo “02_Análisis sintáctico y limpieza de datos” realiza los pasos de limpieza necesarios y luego divide los textos largos en oraciones más pequeñas
- El flujo de trabajo “03_Modelado de temas y aplicación de exploración de datos” utiliza datos limpios para construir un modelo de temas y visualizar sus resultados dentro de una aplicación de datos
- El flujo de trabajo “04_Atribución de habilidades de trabajo” evalúa la asociación de habilidades en roles de trabajo, como científico de datos, ingeniero de datos y analista de datos, basado en los resultados del modelo LDA.
Web scraping para recopilación de datos
Con el fin de tener una comprensión actualizada de las habilidades requeridas en el mercado laboral, optamos por analizar publicaciones de empleo mediante web scraping de agencias de empleo en línea. Dadas las variaciones regionales y la diversidad de idiomas, nos enfocamos en las ofertas de trabajo en los Estados Unidos. Esto garantiza que una proporción significativa de las publicaciones de empleo se presente en inglés. También nos enfocamos en las publicaciones de empleo de febrero de 2023 a abril de 2023.
El flujo de trabajo KNIME “01_Web Scraping for Data Collection” en la Figura 3 recorre una lista de URL de búsquedas en los sitios web de agencias de empleo.
Para extraer las ofertas de trabajo relevantes relacionadas con la Analítica de Datos, utilizamos búsquedas con seis palabras clave que cubren colectivamente el campo de la analítica de datos, a saber: “big data”, “data science”, “business intelligence”, “data mining”, “machine learning” y “data analytics”. Las palabras clave de búsqueda se almacenan en un archivo de Excel y se leen a través del nodo Excel Reader.
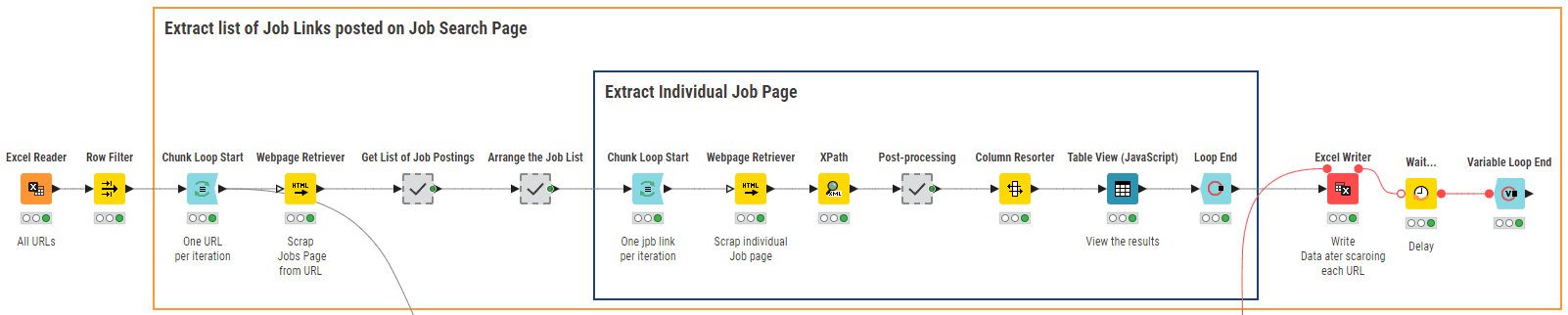
El nodo principal de este flujo de trabajo es el nodo Webpage Retriever. Se utiliza dos veces. La primera vez (bucle externo), el nodo recorre el sitio de acuerdo con la palabra clave proporcionada como entrada y produce la lista relacionada de URL para las ofertas de trabajo publicadas en los Estados Unidos en las últimas 24 horas. La segunda vez (bucle interno), el nodo recupera el contenido de texto de cada URL de oferta de trabajo. Los nodos de Xpath que siguen a los nodos Webpage Retriever analizan los textos extraídos para llegar a la información deseada, como el título del puesto, las calificaciones necesarias, la descripción del puesto, el salario y las calificaciones de la empresa. Finalmente, los resultados se escriben en un archivo local para su posterior análisis. La Figura 4 muestra una muestra de las ofertas de trabajo extraídas para febrero de 2023.

Análisis de NLP y limpieza de datos
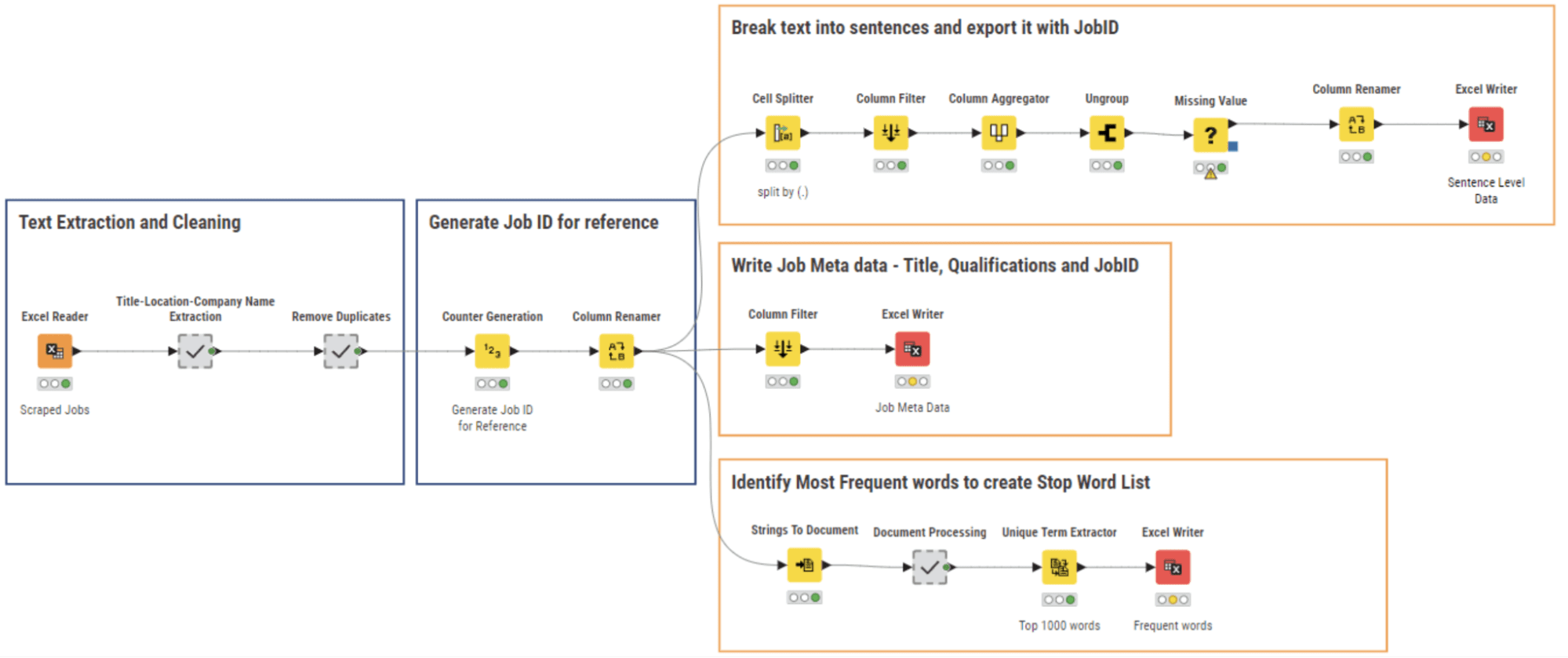
Como todos los datos recopilados recientemente, los resultados de nuestro web scraping necesitaban una limpieza. Realizamos un análisis de NLP junto con la limpieza de datos y escribimos los archivos de datos correspondientes utilizando el flujo de trabajo 02_NLP Parsing and cleaning que se muestra en la Figura 5.
Varios campos de los datos extraídos se han guardado en forma de concatenación de valores de cadena. Aquí, extraímos las secciones individuales utilizando una serie de nodos String Manipulation dentro del meta nodo “Extracción de Título-Lugar-Nombre de la Compañía” y luego eliminamos columnas innecesarias y nos deshicimos de las filas duplicadas.
Luego asignamos una ID única a cada texto de oferta de trabajo y fragmentamos todo el documento en oraciones a través del nodo Cell Splitter. También se extrajo y guardó la información meta para cada trabajo: título, ubicación y empresa, junto con el ID de trabajo.
Se extrajo la lista de las 1000 palabras más frecuentes de todos los documentos, para generar una lista de palabras vacías, que incluye palabras como “solicitante”, “colaboración”, “empleo”, etc… Estas palabras están presentes en cada oferta de trabajo y por lo tanto no agregan información para las siguientes tareas de NLP.
El resultado de esta fase de limpieza es un conjunto de tres archivos:
– Una tabla que contiene las oraciones de los documentos;
– Una tabla que contiene los metadatos de la descripción del trabajo;
– Una tabla que contiene la lista de palabras vacías.
Modelado de temas y exploración de resultados
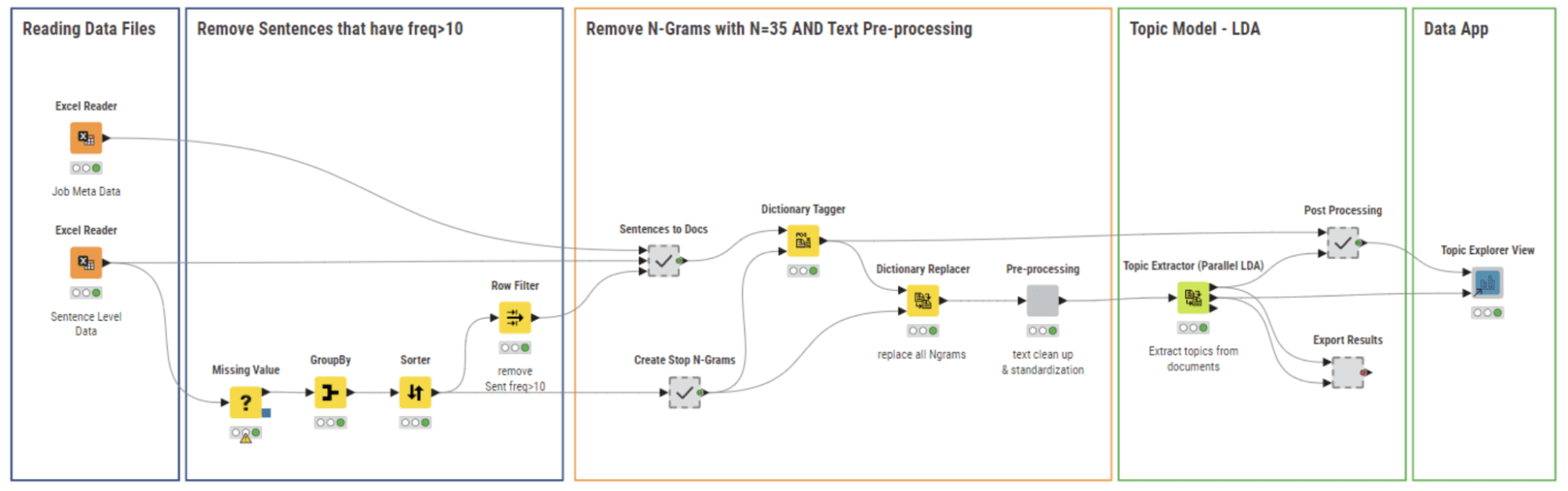
El flujo de trabajo 03_Topic Modeling and Exploration Data App (Figura 6) utiliza los archivos de datos limpiados del flujo de trabajo anterior. En esta etapa, nuestro objetivo es:
- Detectar y eliminar frases comunes (Stop Phrases) que aparecen en muchas ofertas de trabajo.
- Realizar pasos estándar de procesamiento de texto para preparar los datos para el modelado de temas.
- Construir el modelo de temas y visualizar los resultados.
Discutimos las tareas anteriores en detalle en las siguientes subsecciones.
3.1 Eliminar frases de detención con N-gramas
Muchas publicaciones de trabajo incluyen frases que se encuentran comúnmente en políticas de la empresa o acuerdos generales, como “política de no discriminación” o “acuerdos de confidencialidad”. La Figura 7 proporciona un ejemplo donde las publicaciones de trabajo 1 y 2 mencionan la política de “no discriminación”. Estas frases no son relevantes para nuestro análisis y, por lo tanto, deben ser eliminadas de nuestro corpus de texto. Nos referimos a ellas como “frases de detención” y empleamos dos métodos para identificarlas y filtrarlas.
El primer método es sencillo: calculamos la frecuencia de cada frase en nuestro corpus y eliminamos aquellas frases con una frecuencia mayor a 10.
El segundo método implica un enfoque de N-gramas, donde N puede estar en el rango de valores de 20 a 40. Seleccionamos un valor para N y evaluamos la relevancia de los N-gramas derivados del corpus contando el número de N-gramas que se clasifican como frases de detención. Repetimos este proceso para cada valor de N dentro del rango. Elegimos N=35 como el mejor valor para identificar el mayor número de frases de detención.

Usamos ambos métodos para eliminar las “frases de detención”, como se muestra en el flujo de trabajo representado en la Figura 7. Primero, eliminamos las frases más frecuentes, luego creamos N-gramas con N=35 y los etiquetamos en cada documento con el nodo Etiquetador de Diccionario, y por último, eliminamos estos N-gramas utilizando el nodo Sustituidor de Diccionario.
3.2 Preparar datos para el modelado de temas con técnicas de preprocesamiento de texto
Después de eliminar las frases de detención, realizamos el preprocesamiento de texto estándar para preparar los datos para el modelado de temas.
Primero, eliminamos los valores numéricos y alfanuméricos del corpus. Luego, eliminamos los signos de puntuación y las palabras comunes en inglés que no aportan significado. Además, utilizamos una lista personalizada de palabras de detención específicas del dominio laboral para filtrar palabras que no son relevantes para nuestro análisis. Por último, convertimos todos los caracteres a minúsculas.
Decidimos centrarnos en las palabras que tienen significado, por eso filtramos los documentos para incluir solo sustantivos y verbos. Esto se puede hacer asignando una etiqueta de Parte del Discurso (POS) a cada palabra en el documento. Utilizamos el nodo Etiquetador POS para asignar estas etiquetas y las filtramos en función de su valor, manteniendo específicamente las palabras con POS = Sustantivo y POS = Verbo.
Por último, aplicamos lematización de Stanford para asegurarnos de que el corpus esté listo para el modelado de temas. Todos estos pasos de preprocesamiento son realizados por el componente “Pre-procesamiento” mostrado en la Figura 6.
3.3 Construir un modelo de temas y visualizarlo
En la etapa final de nuestra implementación, aplicamos el algoritmo de Distribución Latente de Dirichlet (LDA) para construir un modelo de temas utilizando el nodo Extractora de Temas (LDA paralelo) mostrado en la Figura 6. El algoritmo LDA produce un número de temas (k), cada tema se describe a través de un número (m) de palabras clave. Los parámetros (k, m) deben ser definidos.
Como nota adicional, k y m no deben ser demasiado grandes, ya que queremos visualizar e interpretar los temas (conjuntos de habilidades) revisando las palabras clave (habilidades) y sus respectivos pesos. Exploramos un rango [1, 10] para k y fijamos el valor de m=15. Después de un análisis cuidadoso, encontramos que k=7 resultó en los temas más diversos y distintos con una mínima superposición de palabras clave. Por lo tanto, determinamos que k=7 es el valor óptimo para nuestro análisis.
Explorar los resultados del modelado de temas con una aplicación interactiva de datos
Para permitir que todos accedan a los resultados del modelado de temas y los exploren por sí mismos, desplegamos el flujo de trabajo (en la Figura 6) como una Aplicación de Datos en KNIME Business Hub y lo hicimos público para que todos puedan acceder a él. Puede consultarlo en: Tendencias de Empleo en Análisis de Datos.
La parte visual de esta aplicación de datos proviene del componente Vista del Explorador de Temas creado por Francesco Tuscolano y Paolo Tamagnini, disponible para su descarga gratuita desde el KNIME Community Hub, y proporciona una serie de visualizaciones interactivas de temas por tema y documento.
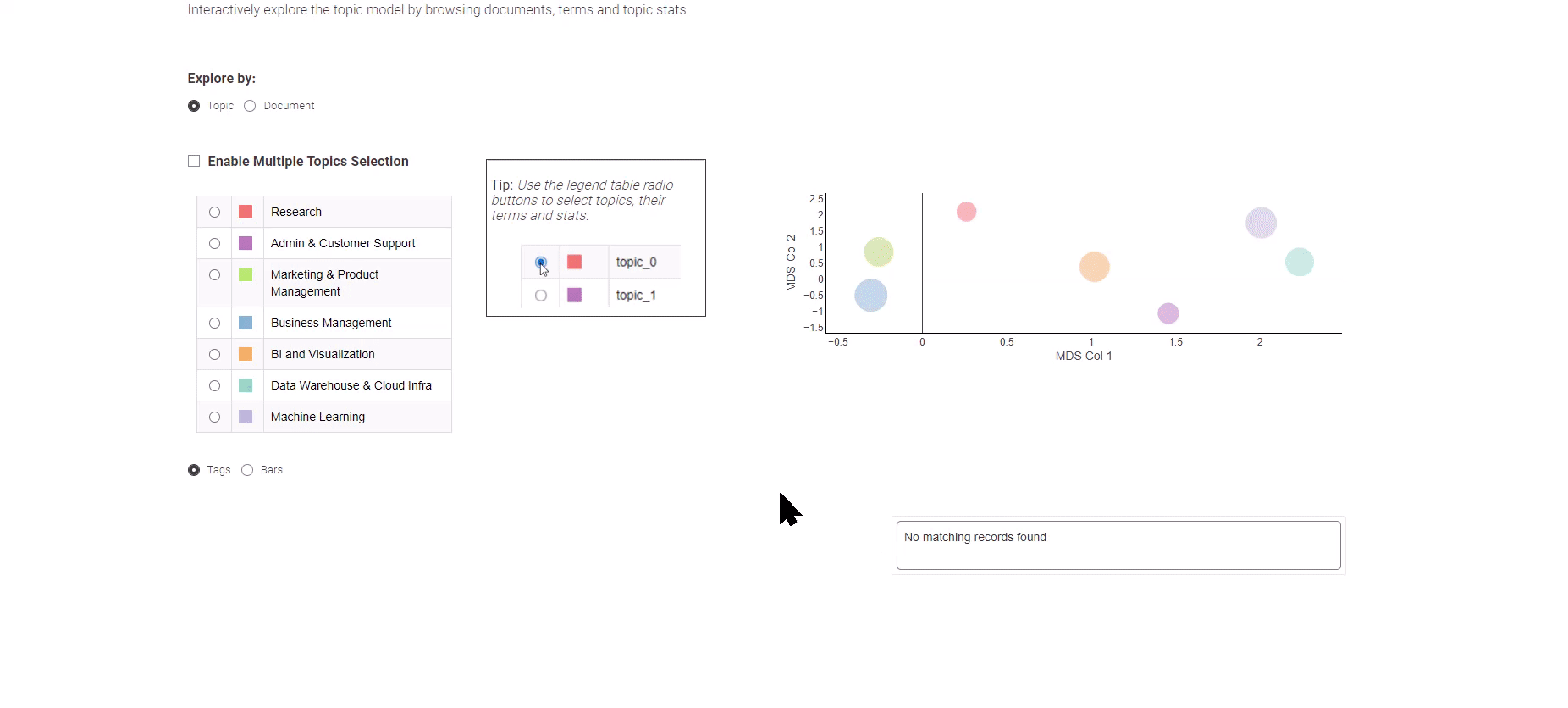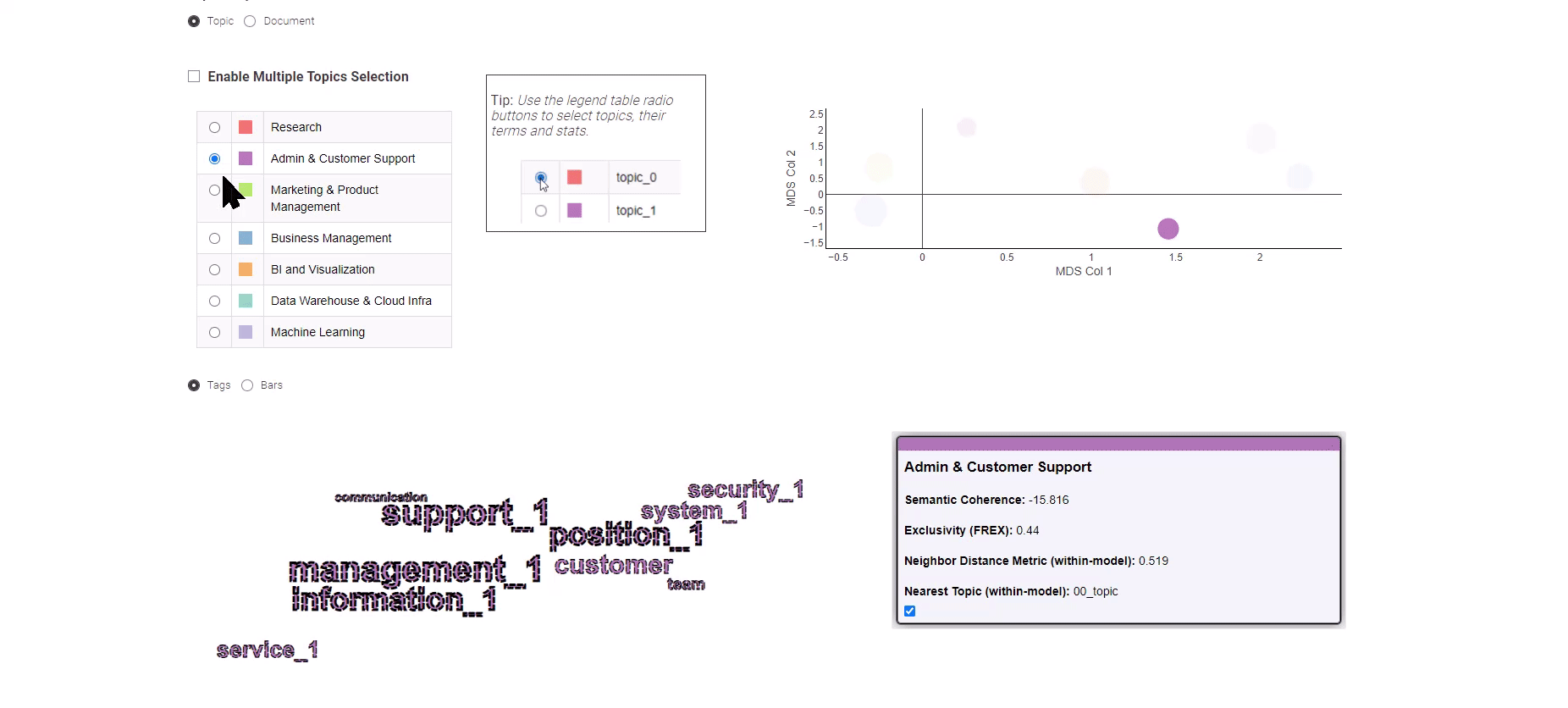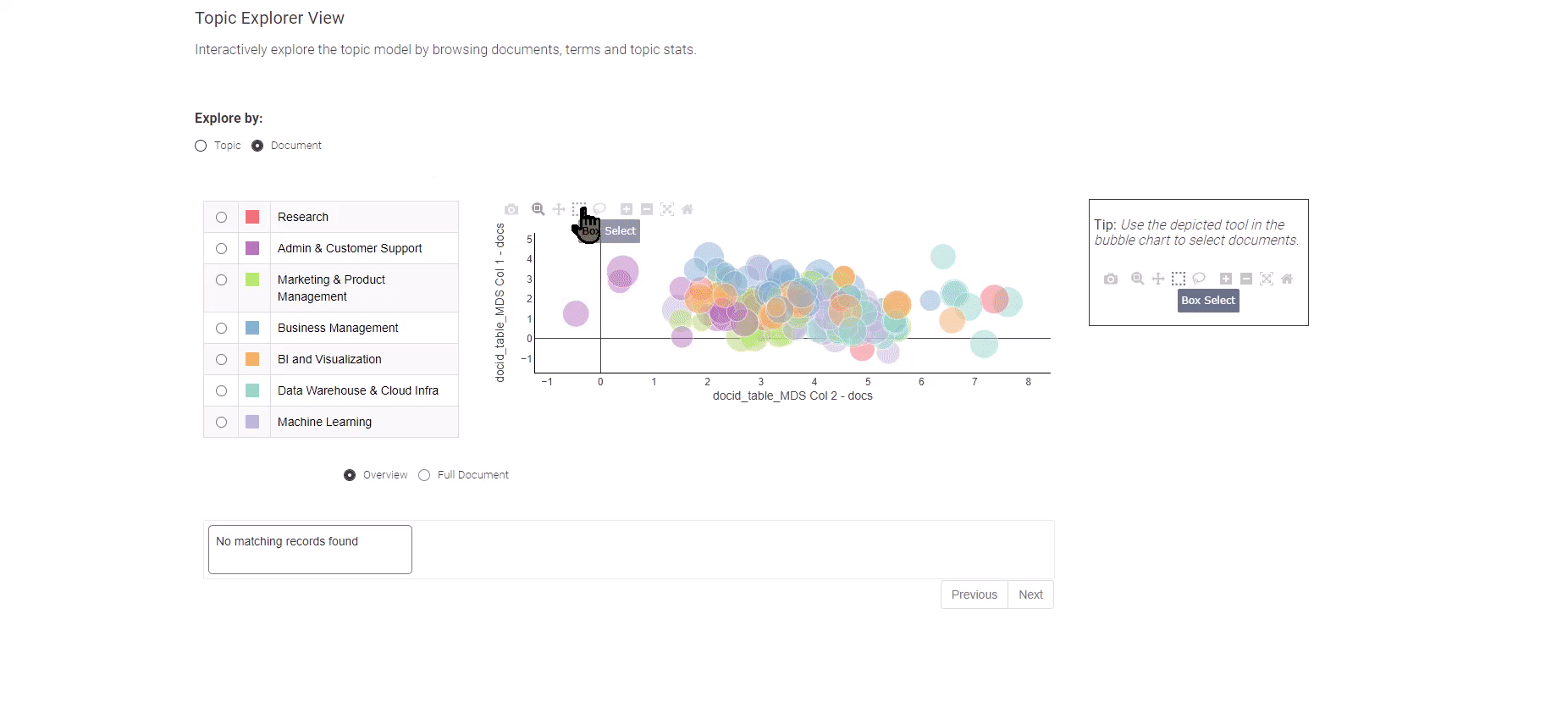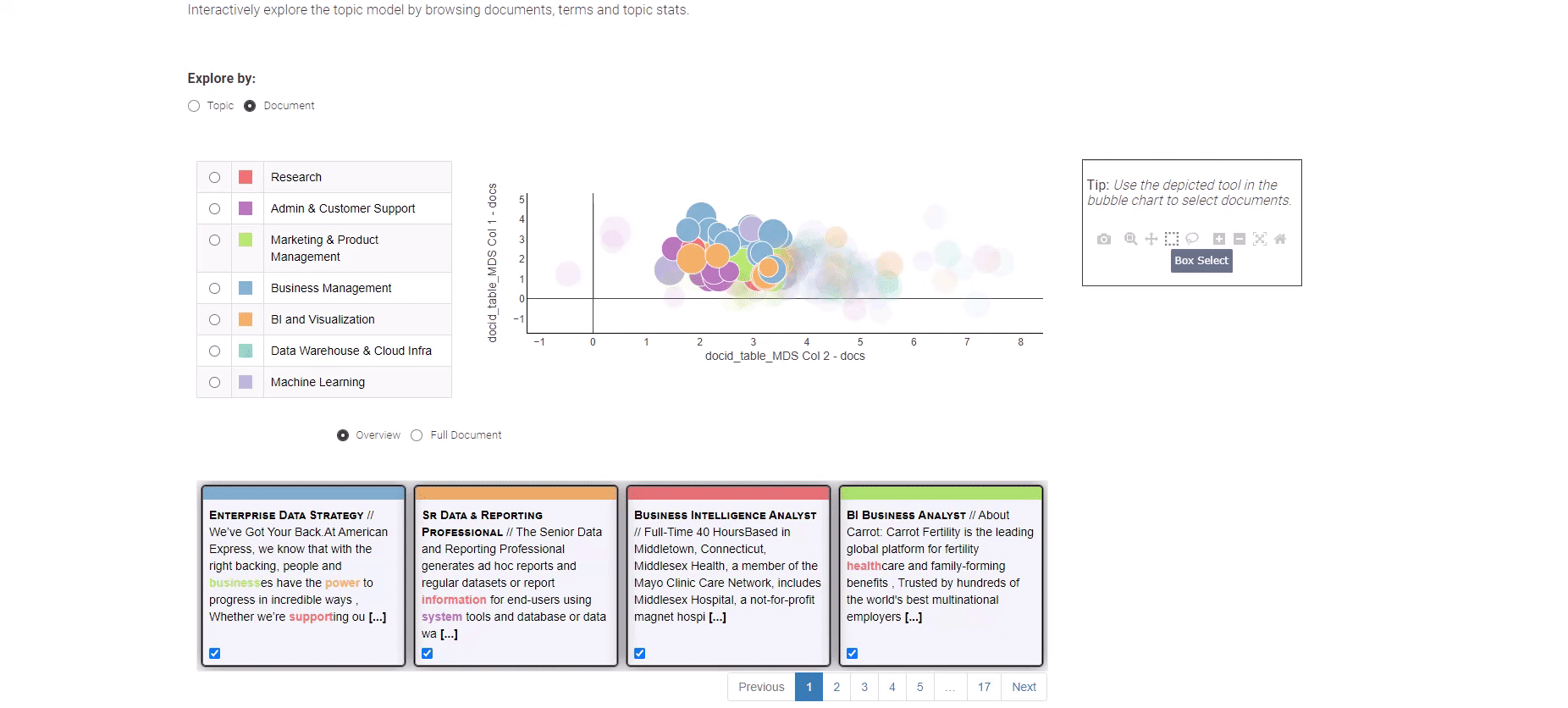 Figura 8: Tendencias laborales en análisis de datos para explorar los resultados del modelado de temas
Figura 8: Tendencias laborales en análisis de datos para explorar los resultados del modelado de temas
Presentado en la Figura 8, esta aplicación de datos ofrece una opción entre dos vistas distintas: la vista “Tema” y la vista “Documento”.
La vista “Tema” utiliza un algoritmo de Escalamiento Multidimensional para representar los temas en un gráfico bidimensional, ilustrando eficazmente las relaciones semánticas entre ellos. En el panel izquierdo, puedes seleccionar fácilmente un tema de interés, lo que mostrará las palabras clave principales correspondientes.
Para adentrarte en la exploración de las ofertas de trabajo individuales, simplemente opta por la vista “Documento”. La vista “Documento” presenta una representación condensada de todos los documentos en dos dimensiones. Utiliza el método de selección de cuadro para identificar los documentos de relevancia, y en la parte inferior, te espera un resumen de los documentos seleccionados
Explorando el mercado laboral de análisis de datos utilizando NLP
Aquí hemos proporcionado un resumen de la aplicación “Tendencias laborales en análisis de datos”, que se implementó y utilizó para explorar los requisitos de habilidades más recientes y los roles laborales en el mercado laboral de la ciencia de datos. Para este blog, restringimos nuestra área de acción a las descripciones de trabajo para Estados Unidos, escritas en inglés, desde febrero hasta abril de 2023.
Para comprender las tendencias laborales y ofrecer una revisión, la aplicación “Tendencias laborales en análisis de datos” recopila información de sitios de agencias de empleo, extrae texto de ofertas de trabajo en línea, extrae temas y palabras clave después de realizar una serie de tareas de NLP, y finalmente visualiza los resultados por tema y por documento para discernir los patrones en los datos.
La aplicación consiste en un conjunto de cuatro flujos de trabajo de KNIME que se ejecutan secuencialmente para el raspado web, el procesamiento de datos, el modelado de temas y las visualizaciones interactivas para permitir al usuario identificar las tendencias laborales.
Desplegamos el flujo de trabajo en KNIME Business Hub y lo hicimos público, para que todos puedan acceder a él. Puedes revisarlo en: Tendencias laborales en análisis de datos.
El conjunto completo de flujos de trabajo está disponible y se puede descargar de forma gratuita desde KNIME Community Hub en Tendencias laborales en análisis de datos. Los flujos de trabajo se pueden cambiar y adaptar fácilmente para descubrir tendencias en otros campos del mercado laboral. Solo es necesario cambiar la lista de palabras clave de búsqueda en el archivo de Excel, el sitio web y el rango de tiempo para la búsqueda.
¿Y los resultados? ¿Cuáles son las habilidades y los roles profesionales más buscados en el mercado laboral actual de la ciencia de datos? En nuestra próxima publicación de blog, te guiaremos a través de la exploración de los resultados de este modelado de temas. Juntos, examinaremos de cerca la intrigante interacción entre roles laborales y habilidades, obteniendo información valiosa sobre el mercado laboral de la ciencia de datos en el camino. ¡Manténte atento para una exploración enriquecedora!
Recursos
- Una revisión sistemática de los requisitos laborales de análisis de datos y cursos en línea por A. Mauro et al.
Mahantesh Pattadkal aporta más de 6 años de experiencia en consultoría en proyectos y productos de ciencia de datos. Con una Maestría en Ciencia de Datos, su experiencia brilla en Aprendizaje Profundo, Procesamiento del Lenguaje Natural y Aprendizaje Automático Explicable. Además, participa activamente en la Comunidad KNIME para colaborar en proyectos basados en ciencia de datos.
Andrea De Mauro tiene más de 15 años de experiencia construyendo equipos de análisis empresarial y ciencia de datos en empresas multinacionales como P&G y Vodafone. Además de su rol corporativo, disfruta enseñando Análisis de Marketing y Aprendizaje Automático Aplicado en varias universidades en Italia y Suiza. A través de su investigación y escritura, ha explorado el impacto empresarial y social de los Datos y la Inteligencia Artificial, convencido de que una mayor alfabetización analítica mejorará el mundo. Su último libro es ‘Data Analytics Made Easy’, publicado por Packt. Apareció en la lista global ‘Forty Under 40’ de la revista CDO en 2022.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- ¿Qué tan cerca estamos de la IA generalizada?
- Revelando patrones ocultos Una introducción al agrupamiento jerárquico
- Maximizar el rendimiento en aplicaciones de IA de borde
- La Inteligencia Artificial está controlando la lucha contra el robo de paquetes de UPS
- Dispositivo óptico portátil muestra promesa para detectar hemorragias postparto
- Vínculo de datos de dispositivos portátiles vincula la reducción del sueño y la actividad durante el embarazo con el riesgo de parto prematuro
- Procyon Photonics La startup dirigida por estudiantes de secundaria que podría revolucionar la informática






