Investigadores de la Universidad de Wisconsin-Madison proponen Eventful Transformers un enfoque rentable para el reconocimiento de video con una pérdida mínima de precisión.
Investigadores de la Universidad de Wisconsin-Madison proponen Eventful Transformers, un enfoque rentable para el reconocimiento de video con una pérdida mínima de precisión.


Los Transformers originalmente diseñados para el modelado del lenguaje han sido investigados recientemente como una posible arquitectura para tareas relacionadas con la visión. Con un rendimiento de última generación en aplicaciones que incluyen identificación de objetos, clasificación de imágenes y clasificación de videos, los Vision Transformers han demostrado una excelente precisión en una variedad de problemas de reconocimiento visual. El alto costo de procesamiento de los Vision Transformers es una de sus principales desventajas. A veces, los Vision Transformers requieren órdenes de magnitud más procesamiento que las redes convolucionales estándar (CNN), hasta cientos de GFlops por imagen. La gran cantidad de datos involucrados en el procesamiento de videos aumenta aún más estos gastos. El potencial de esta tecnología, por lo demás interesante, se ve obstaculizado por los altos requisitos computacionales que impiden que los Vision Transformers se utilicen en dispositivos con pocos recursos o que requieren baja latencia.
Una de las primeras técnicas para aprovechar la redundancia temporal entre las entradas sucesivas y reducir el costo de los Vision Transformers cuando se utilizan con datos de video se presenta en este trabajo realizado por investigadores de la Universidad de Wisconsin-Madison. Imagine un Vision Transformer que se aplica a una secuencia de video cuadro a cuadro o clip a clip. Este Transformer puede ser un modelo sencillo a nivel de cuadro (como un detector de objetos) o una etapa de transición en un modelo espacio-temporal (como el modelo factorizado inicial). Ven los Transformers como aplicados a varias entradas diferentes (cuadros o clips) a lo largo del tiempo, a diferencia del procesamiento de lenguaje, donde una entrada de Transformer representa una secuencia completa. Las películas naturales tienen un alto grado de redundancia temporal y pocas variaciones entre cuadros. Sin embargo, las redes profundas, como los Transformers, se calculan con frecuencia “desde cero” en cada cuadro a pesar de esto.
Este método es ineficiente ya que descarta cualquier dato potencialmente útil de conclusiones anteriores. Su idea principal es que pueden aprovechar mejor las secuencias redundantes reciclando cálculos intermedios de pasos de tiempo anteriores. Inferencia inteligente. El costo de inferencia de los Vision Transformers (y las redes profundas en general) a menudo está determinado por el diseño. Sin embargo, los recursos disponibles pueden cambiar con el tiempo en aplicaciones del mundo real (por ejemplo, debido a procesos competidores o cambios en el suministro de energía). Por lo tanto, se requieren modelos que permitan la modificación en tiempo real del costo computacional. La adaptabilidad es uno de los principales objetivos de diseño en este estudio, y el enfoque está diseñado para proporcionar control en tiempo real sobre el costo de cálculo. Para una ilustración de cómo cambian el presupuesto calculado durante una película, consulte la Figura 1 (sección inferior).
- ¿Reemplazarán los LLMs a los Grafos de Conocimiento? Los investigadores de Meta proponen ‘Head-to-Tail’ un nuevo punto de referencia para medir el conocimiento factual de los Modelos de Lenguaje Grandes
- Entrena a tu primer agente de RL basado en Deep Q Learning Una guía paso a paso
- Introducción a la Estadística utilizando el lenguaje de programación R
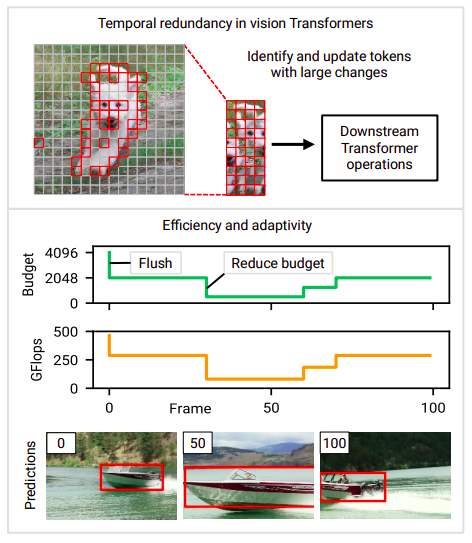
Estudios anteriores han analizado la redundancia temporal y la adaptabilidad de las CNN. Sin embargo, debido a las diferencias arquitectónicas significativas entre los Transformers y las CNN, estos enfoques suelen ser incompatibles con la visión de los Transformers. Los Transformers, en particular, introducen una novedosa primitiva: la autoatención, que se desvía de varias metodologías basadas en CNN. A pesar de este obstáculo, los Vision Transformers ofrecen una gran posibilidad. Es desafiante transferir las ganancias de esparsidad en las CNN, específicamente, la esparsidad adquirida al tener en cuenta la redundancia temporal, en aceleraciones tangibles. Para lograr esto, se deben imponer grandes restricciones en la estructura de esparsidad o se deben utilizar núcleos de cálculo especiales. En cambio, es más sencillo transferir la esparsidad a un tiempo de ejecución más corto utilizando operadores convencionales debido a la naturaleza de las operaciones de los Transformers, centradas en la manipulación de vectores de tokens. Transformers con eventos.
Con el fin de facilitar una inferencia efectiva y adaptable, sugieren Eventful Transformers, un nuevo tipo de Transformer que aprovecha la redundancia temporal entre las entradas. La palabra “Eventful” se acuñó para describir sensores llamados cámaras de eventos, que generan salidas dispersas en respuesta a cambios en la escena. Los Eventful Transformers actualizan selectivamente las representaciones de tokens y los mapas de autoatención en cada paso de tiempo para realizar un seguimiento de los cambios a nivel de token a lo largo del tiempo. Los módulos de gateo son bloques en un Eventful Transformer que permiten el control en tiempo de ejecución de la cantidad de tokens actualizados. Su enfoque funciona con una variedad de aplicaciones de procesamiento de video y se puede utilizar con modelos preconstruidos (a menudo sin necesidad de volver a entrenar). Su investigación muestra que los Eventful Transformers, creados a partir de modelos de última generación, reducen considerablemente los costos de cálculo al mantener en su mayoría la precisión del modelo original.
Su código fuente, que contiene módulos de PyTorch para crear Eventful Transformers, está disponible para el público. Las limitaciones de la página del proyecto de Wisionlab se encuentran en wisionlab.com/project/eventful-transformers. En la CPU y GPU, muestran mejoras en el tiempo de ejecución. Su enfoque, basado en operadores estándar de PyTorch, quizás no sea el mejor desde un punto de vista técnico. Están seguros de que las relaciones de mejora de velocidad podrían aumentarse aún más con más trabajo para reducir la sobrecarga (como construir un kernel CUDA fusionado para su lógica de enrutamiento). Además, su enfoque resulta en ciertas sobrecargas de memoria inevitables. No sorprendentemente, mantener ciertos tensores en memoria es necesario para reutilizar cálculos de pasos de tiempo anteriores.
Echa un vistazo al Paper. Todo el crédito de esta investigación va a los investigadores de este proyecto. Además, no olvides unirte a nuestra SubReddit de ML de más de 29k seguidores, comunidad de Facebook de más de 40k seguidores, canal de Discord y boletín de correo electrónico, donde compartimos las últimas noticias de investigación en IA, proyectos interesantes de IA y más.
Si te gusta nuestro trabajo, te encantará nuestro boletín de noticias.
La publicación Investigadores de la Universidad de Wisconsin-Madison proponen Eventful Transformers: un enfoque rentable para el reconocimiento de video con una pérdida mínima de precisión apareció primero en MarkTechPost.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Investigadores de Alibaba presentan la serie Qwen-VL un conjunto de modelos de visión-lenguaje a gran escala diseñados para percibir y comprender tanto texto como imágenes
- Escalando la Agrupación Aglomerativa para Grandes Volúmenes de Datos
- Diferenciación automática con Python y C++ para el aprendizaje profundo
- Este artículo de IA de GSAi China presenta un estudio exhaustivo de agentes autónomos basados en LLM
- Revolucionando la Interacción Humano-Máquina La Emergencia de la Ingeniería de Instrucciones
- Router Langchain Cómo crear asistencia de programación utilizando Langchain
- ¿Qué es EDI? Sobre el Intercambio Electrónico de Datos (EDI)





