Una nueva investigación de IA de Tel Aviv y la Universidad de Copenhague introduce un enfoque de conectar y usar para ajustar rápidamente modelos de difusión de texto a imagen utilizando una señal discriminativa.
Investigación de IA de Tel Aviv y la Universidad de Copenhague enfoque rápido para ajustar modelos de difusión de texto a imagen.


Los modelos de difusión de texto a imagen han demostrado un impresionante éxito en la generación de imágenes diversas y de alta calidad basadas en descripciones de texto de entrada. Sin embargo, enfrentan desafíos cuando el texto de entrada es léxicamente ambiguo o involucra detalles intrincados. Esto puede llevar a situaciones en las que el contenido de la imagen deseada, como una “plancha” para la ropa, se representa erróneamente como el metal “elemental”.
Para abordar estas limitaciones, los métodos existentes han utilizado clasificadores pre-entrenados para guiar el proceso de eliminación de ruido. Un enfoque implica mezclar la estimación de puntuación de un modelo de difusión con el gradiente de la probabilidad logarítmica de un clasificador pre-entrenado. En términos más simples, este enfoque utiliza información tanto de un modelo de difusión como de un clasificador pre-entrenado para generar imágenes que coincidan con el resultado deseado y se alineen con el juicio del clasificador sobre lo que la imagen debe representar.
Sin embargo, este método requiere un clasificador capaz de trabajar con datos reales y ruidosos.
- Investigadores de Google AI presentan MADLAD-400 un conjunto de datos de dominio web con tokens de 2.8T que abarca 419 idiomas.
- Este artículo de Alibaba Group presenta FederatedScope-LLM un paquete integral para el ajuste fino de LLMs en el aprendizaje federado
- Una técnica de mapeo de posturas podría evaluar de forma remota a pacientes con parálisis cerebral
Otras estrategias han condicionado el proceso de difusión en etiquetas de clase utilizando conjuntos de datos específicos. Si bien es efectivo, este enfoque está lejos de tener la capacidad expresiva completa de los modelos entrenados en extensas colecciones de pares imagen-texto de la web.
Una dirección alternativa implica el ajuste fino de un modelo de difusión o algunos de sus tokens de entrada utilizando un pequeño conjunto de imágenes relacionadas con un concepto o etiqueta específica. Sin embargo, este enfoque tiene desventajas, como un entrenamiento lento para nuevos conceptos, posibles cambios en la distribución de imágenes y una diversidad limitada capturada de un pequeño grupo de imágenes.
Este artículo informa de un enfoque propuesto que aborda estos problemas, proporcionando una representación más precisa de las clases deseadas, resolviendo la ambigüedad léxica y mejorando la representación de detalles finos. Esto se logra sin comprometer el poder expresivo del modelo de difusión pre-entrenado original o enfrentar las desventajas mencionadas. La visión general de este método se ilustra en la siguiente figura.
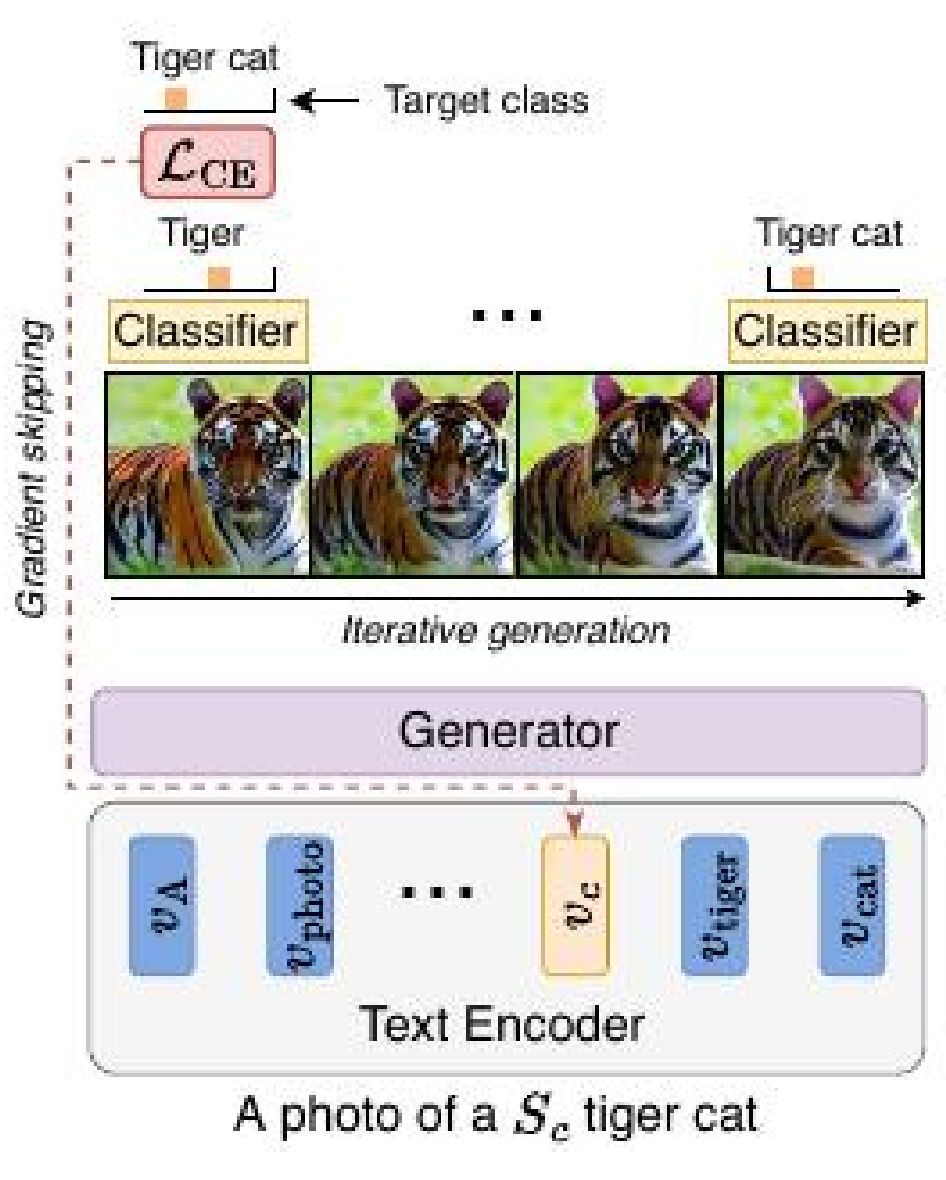

En lugar de guiar el proceso de difusión o alterar todo el modelo, este enfoque se centra en actualizar la representación de un solo token añadido correspondiente a cada clase de interés. Es importante destacar que esta actualización no implica ajustar el modelo en imágenes etiquetadas.
El método aprende la representación del token para una clase objetivo específica a través de un proceso iterativo de generación de nuevas imágenes con una mayor probabilidad de clase según un clasificador pre-entrenado. La retroalimentación del clasificador guía la evolución del token de clase designado en cada iteración. Se utiliza una nueva técnica de optimización llamada “gradient skipping”, en la que el gradiente se propaga únicamente a través de la etapa final del proceso de difusión. El token optimizado se incorpora como parte de la entrada de texto condicionante para generar imágenes utilizando el modelo de difusión original.
Según los autores, este método ofrece varias ventajas clave. Solo requiere un clasificador pre-entrenado y no exige un clasificador entrenado explícitamente en datos ruidosos, lo que lo diferencia de otras técnicas condicionales de clase. Además, destaca por su velocidad, lo que permite mejoras inmediatas en las imágenes generadas una vez que se entrena un token de clase, en contraste con métodos más lentos.
Se muestran a continuación los resultados seleccionados del estudio en la imagen siguiente. Estos estudios de caso proporcionan una visión comparativa de los enfoques propuestos y del estado del arte.

Este fue el resumen de una nueva técnica de IA no invasiva que explota un clasificador pre-entrenado para ajustar modelos de difusión de texto a imagen. Si estás interesado y quieres aprender más al respecto, por favor no dudes en consultar los enlaces citados a continuación.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Desplegando modelos de PyTorch con el servidor de inferencia Nvidia Triton
- Cómo construir gráficos de cascada con Plotly Graph Objects
- ¡Pide tus documentos con Langchain y Deep Lake!
- Inteligencia Artificial y la Estética de la Generación de Imágenes
- Hoja de referencia de Scikit-learn para Aprendizaje Automático
- Conoce FLM-101B Un decodificador de solo lectura de LLM de código abierto con 101 mil millones de parámetros
- En la cumbre en Washington DC, los líderes tecnológicos respaldan la regulación de la IA





