Aprendizaje Automático Hecho Intuitivo
Intuitive Machine Learning
ML: todo lo que necesitas saber sin matemáticas complicadas

¿Qué es el Aprendizaje Automático?
Seguro, la teoría real detrás de modelos como ChatGPT es admitidamente muy difícil, pero la intuición subyacente detrás del Aprendizaje Automático (ML) es, bueno, ¡intuitiva! Entonces, ¿qué es ML?
El Aprendizaje Automático permite a las computadoras aprender utilizando datos.
Pero, ¿qué significa esto? ¿Cómo utilizan las computadoras los datos? ¿Qué significa que una computadora aprenda? Y en primer lugar, ¿a quién le importa? Empecemos con la última pregunta.
Hoy en día, los datos nos rodean. Por lo tanto, es cada vez más importante utilizar herramientas como ML, ¡ya que puede ayudar a encontrar patrones significativos en los datos sin necesidad de programar explícitamente! En otras palabras, al utilizar ML, podemos aplicar algoritmos genéricos a una amplia variedad de problemas con éxito.
- Guía para principiantes para construir tus propios modelos de lenguaje grandes desde cero.
- Simplifica la creación y mantenimiento de DAG en Airflow con Hamilton en 8 minutos
- Conoce Magic123 Un novedoso proceso de conversión de imagen a 3D que utiliza una optimización en dos etapas, de áspero a refinado, para producir geometría y texturas 3D de alta calidad y alta resolución.
Existen algunas categorías principales de Aprendizaje Automático, siendo algunos de los tipos principales el aprendizaje supervisado (SL), el aprendizaje no supervisado (UL) y el aprendizaje por refuerzo (RL). Hoy solo describiré el aprendizaje supervisado, aunque en futuras publicaciones espero poder profundizar más en el aprendizaje no supervisado y el aprendizaje por refuerzo.
Resumen de aprendizaje supervisado en 1 minuto
Mira, entiendo que quizás no quieras leer todo este artículo. En esta sección te enseñaré lo más básico (que para muchas personas es todo lo que necesitas saber) antes de profundizar más en las secciones posteriores.
El aprendizaje supervisado implica aprender a predecir alguna etiqueta utilizando diferentes características.
Imagina que estás tratando de descubrir una forma de predecir el precio de los diamantes utilizando características como el quilate, el corte, la claridad y más. Aquí, el objetivo es aprender una función que tome como entrada las características de un diamante específico y devuelva el precio asociado.
Así como los humanos aprenden por ejemplo, en este caso las computadoras harán lo mismo. Para poder aprender una regla de predicción, este agente de ML necesita “ejemplos etiquetados” de diamantes, que incluyan tanto sus características como su precio. La supervisión se produce porque se te proporciona la etiqueta (precio). En realidad, es importante considerar que tus ejemplos etiquetados sean realmente verdaderos, ya que es una suposición del aprendizaje supervisado que los ejemplos etiquetados son “verdades fundamentales”.
Ok, ahora que hemos repasado los conceptos más fundamentales, podemos adentrarnos un poco más en todo el proceso de ciencia de datos/ML.
Configuración del problema
Utilicemos un ejemplo extremadamente relacionable, que está inspirado en este libro de texto. Imagina que estás varado en una isla, donde la única comida es una fruta rara conocida como “Melón-Justin”. Aunque nunca has comido Melón-Justin en particular, has comido muchas otras frutas, y sabes que no quieres comer frutas que se hayan echado a perder. También sabes que normalmente puedes saber si una fruta se ha echado a perder mirando el color y la firmeza de la fruta, por lo que extrapolas y asumes que esto también se aplica al Melón-Justin.
En términos de ML, utilizaste conocimientos previos de la industria para determinar dos características (color, firmeza) que crees que predecirán con precisión la etiqueta (si el Melón-Justin se ha echado a perder o no).
Pero, ¿cómo sabrás qué color y qué firmeza corresponden a que la fruta esté echada a perder? ¿Quién sabe? Solo necesitas probarlo. En términos de ML, necesitamos datos. Más específicamente, necesitamos un conjunto de datos etiquetados que consista en Melones-Justin reales y su etiqueta asociada.
Recopilación/Procesamiento de datos
Entonces pasas los próximos días comiendo melones y registrando el color, la firmeza y si el melón estaba echado a perder o no. Después de unos días dolorosos de comer constantemente melones que se han echado a perder, tienes el siguiente conjunto de datos etiquetados:
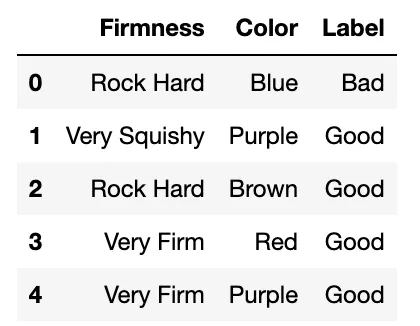
Cada fila representa una sandía específica y cada columna es el valor de la característica/etiqueta para la sandía correspondiente. Pero debemos tener en cuenta que tenemos palabras, ya que las características son categóricas en lugar de numéricas.
Realmente necesitamos números para que nuestra computadora los procese. Existen diversas técnicas para convertir características categóricas en características numéricas, que van desde la codificación one-hot hasta los embeddings y más.
Lo más sencillo que podemos hacer es convertir la columna “Etiqueta” en una columna “Buena”, que tiene valor 1 si la sandía es buena y 0 si es mala. Por ahora, supongamos que existe una metodología para convertir el color y la firmeza a una escala de -10 a 10, de manera que tenga sentido. Como un punto adicional, piensa en las suposiciones al poner una característica categórica como el color en esa escala. Después de este preprocesamiento, nuestro conjunto de datos podría verse así:
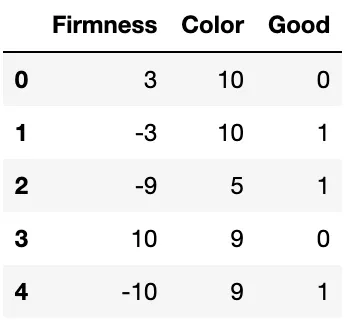
Ahora tenemos un conjunto de datos etiquetados, lo que significa que podemos utilizar un algoritmo de aprendizaje supervisado. Nuestro algoritmo debe ser un algoritmo de clasificación, ya que estamos prediciendo una categoría buena (1) o mala (0). La clasificación está en oposición a los algoritmos de regresión, que predicen un valor continuo como el precio de un diamante.
Análisis Exploratorio de Datos
Pero, ¿qué algoritmo? Existen varios algoritmos de clasificación supervisada, que van desde la regresión logística básica hasta algunos algoritmos de aprendizaje profundo más complejos. Bueno, primero echemos un vistazo a nuestros datos realizando un análisis exploratorio de datos (EDA, por sus siglas en inglés):
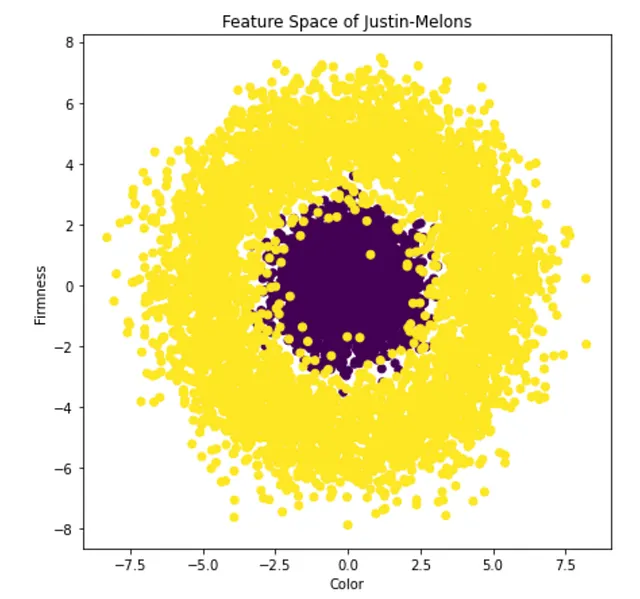
La imagen de arriba es una representación del espacio de características; tenemos dos características y simplemente colocamos cada ejemplo en un gráfico con los dos ejes siendo las dos características. Además, hacemos los puntos de color púrpura si la sandía asociada es buena, y de color amarillo si es mala. ¡Claramente, con un poco de EDA, hay una respuesta obvia!
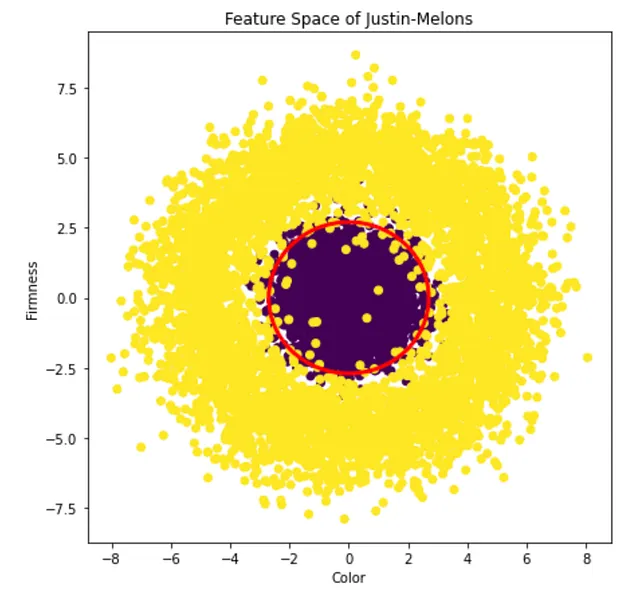
Probablemente deberíamos clasificar todos los puntos dentro del círculo rojo como sandías buenas, mientras que los que están fuera del círculo deberían clasificarse como sandías malas. Intuitivamente, ¡esto tiene sentido! Por ejemplo, no quieres una sandía que sea completamente sólida, pero tampoco quieres que sea excesivamente blanda. Más bien, quieres algo intermedio, y lo mismo probablemente sea cierto para el color también.
Determinamos que queríamos un límite de decisión que fuera un círculo, pero esto se basó simplemente en una visualización preliminar de los datos. ¿Cómo determinaríamos esto de manera sistemática? Esto es especialmente relevante en problemas más grandes, donde la respuesta no es tan simple. Imagina cientos de características. No hay forma posible de visualizar el espacio de características de 100 dimensiones de manera razonable.
¿Qué estamos aprendiendo?
El primer paso es definir tu modelo. Hay un montón de modelos de clasificación. Dado que cada uno tiene su propio conjunto de suposiciones, es importante tratar de hacer una buena elección. Para enfatizar esto, comenzaré haciendo una elección realmente mala.
Una idea intuitiva es hacer una predicción ponderando cada uno de los factores:
Fórmula de Justin Cheigh usando Embed Fun
Por ejemplo, supongamos que nuestros parámetros w1 y w2 son 2 y 1, respectivamente. También supongamos que nuestra sandía de entrada, Justin Melon, tiene Color = 4 y Firmeza = 6. Entonces nuestra predicción Good = (2 x 4) + (1 x 6) = 14.
Nuestra clasificación (14) ni siquiera es una de las opciones válidas (0 o 1). Esto se debe a que en realidad se trata de un algoritmo de regresión. De hecho, es un caso simple del algoritmo de regresión más simple: regresión lineal.
Entonces, convirtamos esto en un algoritmo de clasificación. Una forma sencilla sería esta: utilizar la regresión lineal y clasificar como 1 si la salida es mayor que un término de sesgo b. De hecho, podemos simplificar agregando un término constante a nuestro modelo de manera que clasifiquemos como 1 si la salida es mayor que 0.
En matemáticas, dejemos que PRED = w1 * Color + w2 * Firmeza + b. Entonces obtenemos:
Fórmula por Justin Cheigh usando Embed Fun
Esto es ciertamente mejor, ya que al menos estamos realizando una clasificación, pero hagamos un gráfico de PRED en el eje x y nuestra clasificación en el eje y:
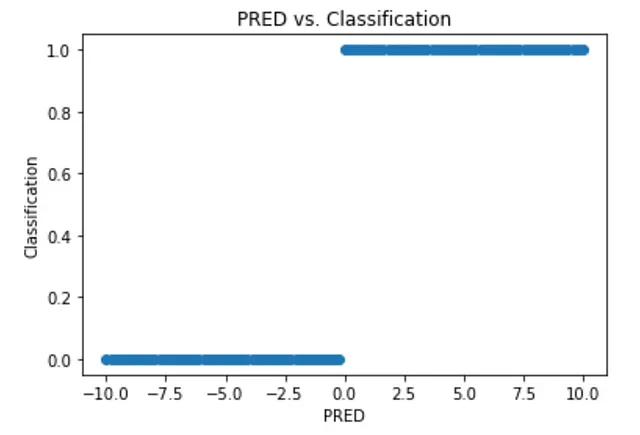
Esto es un poco extremo. Un ligero cambio en PRED podría cambiar por completo la clasificación. Una solución es que la salida de nuestro modelo represente la probabilidad de que el Justin-Melon sea bueno, lo cual podemos hacer suavizando la curva:
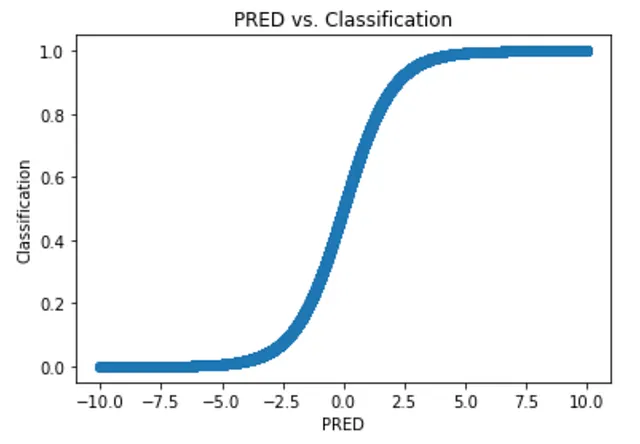
Esta es una curva sigmoide (o una curva logística). Entonces, en lugar de tomar PRED y aplicar esta activación por partes (Bueno si PRED ≥ 0), podemos aplicar esta función de activación sigmoide para obtener una curva suavizada como la de arriba. En general, nuestro modelo logístico se ve así:
Fórmula por Justin Cheigh usando Embed Fun
Aquí, el símbolo sigma representa la función de activación sigmoide. Genial, así que tenemos nuestro modelo, ¡y solo necesitamos averiguar cuáles son los mejores pesos y sesgos! Este proceso se conoce como entrenamiento.
Entrenamiento del Modelo
Genial, ¡así que todo lo que necesitamos hacer es averiguar cuáles son los mejores pesos y sesgos! Pero esto es mucho más fácil decirlo que hacerlo. Hay un número infinito de posibilidades, ¿y qué significa realmente “mejor”?
Comencemos con la última pregunta: ¿qué es lo mejor? Aquí hay una forma simple pero poderosa: los pesos más óptimos son aquellos que obtienen la mayor precisión en nuestro conjunto de entrenamiento.
Entonces, solo necesitamos encontrar un algoritmo que maximice la precisión. Sin embargo, matemáticamente es más fácil minimizar algo. En pocas palabras, en lugar de definir una función de valor, donde un valor más alto es “mejor”, preferimos definir una función de pérdida, donde una pérdida más baja es mejor. Aunque las personas suelen usar algo como la entropía cruzada binaria para la pérdida de clasificación (binaria), nosotros simplemente usaremos un ejemplo simple: minimizar el número de puntos clasificados incorrectamente.
Para hacer esto, utilizamos un algoritmo conocido como descenso del gradiente. A grandes rasgos, el descenso del gradiente funciona como un esquiador miope tratando de bajar una montaña. Una propiedad importante de una buena función de pérdida (y una que nuestra función de pérdida rudimentaria realmente carece) es la suavidad. Si trazáramos nuestro espacio de parámetros (valores de parámetros y pérdida asociada en el mismo gráfico), el gráfico se vería como una montaña.
Entonces, primero comenzamos con parámetros aleatorios y, por lo tanto, probablemente comenzamos con una pérdida mala. Como un esquiador tratando de bajar la montaña lo más rápido posible, el algoritmo mira en todas las direcciones, tratando de encontrar la forma más empinada de ir (es decir, cómo cambiar los parámetros para reducir la pérdida al máximo). Pero, el esquiador es miope, por lo que solo mira un poco en cada dirección. Iteramos este proceso hasta que llegamos al fondo (personas observadoras pueden notar que en realidad podríamos terminar en un mínimo local). En este punto, los parámetros con los que terminamos son nuestros parámetros entrenados.
Una vez que entrenas tu modelo de regresión logística, te das cuenta de que tu rendimiento sigue siendo realmente malo y que tu precisión es solo del 60% (¡apenas mejor que adivinar!). Esto se debe a que estamos violando una de las suposiciones del modelo. La regresión logística matemáticamente solo puede producir un límite de decisión lineal, ¡pero sabíamos por nuestro EDA que el límite de decisión debería ser circular!
Con esto en mente, pruebas modelos diferentes y más complejos, ¡y obtienes uno que alcanza el 95% de precisión! Ahora tienes un clasificador completamente entrenado capaz de diferenciar entre buenos Justin-Melons y malos Justin-Melons, ¡y finalmente puedes comer todas las frutas deliciosas que quieras!
Conclusión
Demos un paso atrás. En alrededor de 10 minutos, has aprendido mucho sobre el aprendizaje automático, incluida prácticamente toda la tubería de aprendizaje supervisado. Entonces, ¿qué sigue?
Bueno, ¡eso depende de ti! Para algunos, este artículo fue suficiente para tener una idea general de lo que realmente es el ML. Para otros, este artículo puede dejar muchas preguntas sin respuesta. ¡Eso es genial! Quizás esta curiosidad te permita explorar aún más este tema.
Por ejemplo, en el paso de recolección de datos asumimos que simplemente comerías una gran cantidad de melones durante unos días, sin tener realmente en cuenta ninguna característica específica. Esto no tiene sentido. Si comes un melón verde y blandito llamado Justin-Melon y te enferma violentamente, probablemente te alejarías de esos melones. En realidad, aprenderías a través de la experiencia, actualizando tus creencias a medida que avanzas. Este marco es más similar al aprendizaje por refuerzo.
Y ¿qué pasaría si supieras que un solo Justin-Melon en mal estado podría matarte al instante y que sería demasiado arriesgado probar uno sin estar seguro? Sin estas etiquetas, no podrías realizar un aprendizaje supervisado. Pero tal vez todavía haya una forma de obtener información sin etiquetas. Este marco es más similar al aprendizaje no supervisado.
En las próximas publicaciones del blog, espero expandir de manera análoga sobre el aprendizaje por refuerzo y el aprendizaje no supervisado.
¡Gracias por leer!
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Bootcamp Intensivo de Aprendizaje Automático para el Desarrollo de Habilidades
- Usé ChatGPT (todos los días) durante 5 meses. Aquí hay algunas joyas ocultas que cambiarán tu vida.
- AI Engaña a los Estafadores La Ingeniosa Batalla Contra las Llamadas Automáticas
- Creando una Infografía con Matplotlib
- ¿Cuál es la diferencia entre la covarianza y la correlación?
- Trabajos que la IA no puede reemplazar
- Conoce SDFStudio un marco unificado y modular para la reconstrucción de superficies neuronales implícitas basado en el proyecto Nerfstudio.






