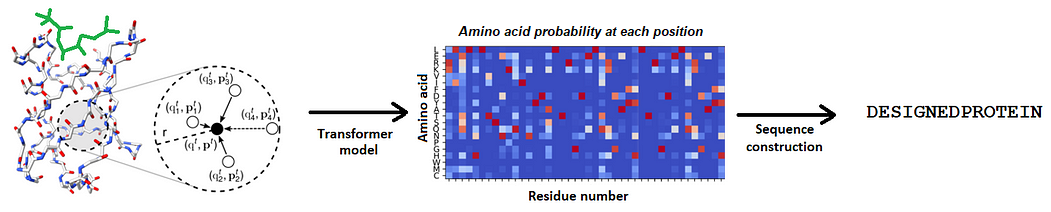
Conoce a Skywork-13B una familia de grandes modelos de lenguaje (LLMs) entrenados en un corpus de más de 3.2 billones de tokens extraídos tanto de textos en inglés como en chino.
Descubre a Skywork-13B una familia de poderosos modelos de lenguaje (LLMs) entrenados en un extenso corpus de más de 3.2 billones de tokens extraídos de textos tanto en inglés como en chino.


Los LLM bilingües están cobrando cada vez más importancia en nuestro mundo interconectado, donde la diversidad lingüística es un desafío común. Tienen el potencial de derribar barreras lingüísticas, promover la comprensión intercultural y mejorar el acceso a la información y servicios para personas que hablan diferentes idiomas. Los LLM bilingües se pueden utilizar para proporcionar servicios de traducción automática de alta calidad. Pueden traducir texto de un idioma a otro, ayudando a romper barreras lingüísticas y facilitar la comunicación entre diferentes culturas y regiones.
Con el crecimiento de la necesidad de estos modelos, hay un aumento en la tendencia de comercialización y la necesidad de más transparencia. Muchas organizaciones solo hacen públicos los puntos de control del modelo y omiten la información vital de un modelo. Para recuperar la transparencia en la IA, los investigadores de Kunlun Technology construyeron una familia de grandes modelos de lenguaje entrenados con más de 3,2 billones de tokens extraídos de textos en inglés y chinos, con una divulgación integral. Se llama Skywork – 13B.
La familia Skywork-13B incluye Skywork-13B-Base y Skywork-13BChat. El base es un modelo de base sólido con una capacidad de modelado del lenguaje chino de vanguardia, y el chat es una versión optimizada para conversaciones. A diferencia de otras organizaciones, ellos divulgan información detallada sobre el proceso de entrenamiento y la composición de los datos.
- Hablar solo sobre lo que has leído ¿Pueden los LLM generalizar más allá de sus datos de preentrenamiento?
- Explora técnicas avanzadas para la optimización de hiperparámetros con Amazon SageMaker Automatic Model Tuning
- Cómo enseñamos a Google Translate a reconocer los homónimos
También han publicado puntos de control intermedios, que proporcionan un recurso valioso para comprender cómo se desarrollan las capacidades del modelo durante el entrenamiento. Creen que esta divulgación permite a otros investigadores aprovechar los puntos de control para sus casos de uso. También han desarrollado un método novedoso que detecta el nivel de uso de datos en dominio durante la etapa de entrenamiento.
El equipo entrenó el modelo base Skywork-13B en SkyPile. En lugar de entrenarlo en SkyPile en su totalidad, siguieron un enfoque de entrenamiento en dos etapas. En la primera etapa, constituyeron la fase de entrenamiento previo principal, que implica entrenar el modelo desde cero en SkyPile-Main. En la segunda etapa, se optimizó con conocimientos relacionados con STEM (ciencia, tecnología, ingeniería y matemáticas) y habilidades de resolución de problemas mediante el entrenamiento continuo en SkyPile-STEM.
Durante el entrenamiento del modelo, el equipo examinó la pérdida de modelado de lenguaje en numerosos conjuntos de validación reservados, cada uno reflejando una distribución de datos distinta, creando conjuntos de validación separados para código, publicaciones académicas, publicaciones en redes sociales y textos web en chino e inglés. Afirman que seguir este enfoque conduce a una construcción fácil, simplicidad en la computación, alta sensibilidad al progreso del entrenamiento y agnosticismo del modelo.
El modelo Skywork-13B muestra el mejor rendimiento en general. Obtuvo la puntuación de perplejidad promedio más baja, 9,42. También exhibe el mejor rendimiento en cada dominio individual, logrando las puntuaciones de perplejidad más bajas en los dominios de tecnología, cine, gobierno y finanzas. Sobresale no solo al superar el rendimiento de modelos de un tamaño similar, sino también al superar significativamente a modelos mucho más grandes como InternLM-20B y Aquila2-34B.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Retrocediendo en el tiempo la IA descifra enigmas romanos ancestrales
- Leslie Orne, Presidenta y CEO de Trinity Life Sciences — Innovaciones en Ciencias de la Vida, Estrategias basadas en Datos, IA en Farmacia, Liderazgo Ejecutivo, Transacciones Estratégicas, Planificación de Marca y Equilibrio entre el Trabajo y la Vida
- Encontrar respuestas (sobre la mejor manera de encontrar respuestas)
- Aplicación de Smartphone aumenta la seguridad en la cirugía de hígado
- ¿Cómo está impactando la inteligencia artificial en la vida familiar ahora y en el futuro?
- Tendencias tecnológicas innovadoras que mejoran las campañas de marketing
- Diseccionando el currículum que me consiguió mi trabajo de científico de datos en tecnología