Presentando ⚔️ IA vs. IA ⚔️ un sistema de competencia de aprendizaje por refuerzo profundo para múltiples agentes
'Introducing ⚔️ AI vs. AI ⚔️ a deep reinforcement learning competition system for multiple agents.'
Estamos emocionados de presentar una nueva herramienta que creamos: ⚔️ IA vs. IA ⚔️, un sistema de competencia de aprendizaje por refuerzo profundo multiagentes.
Esta herramienta, alojada en Spaces, nos permite crear competencias multiagentes. Está compuesta por tres elementos:
- Un Espacio con un algoritmo de emparejamiento que ejecuta las peleas de modelos utilizando una tarea en segundo plano.
- Un conjunto de datos que contiene los resultados.
- Una tabla de clasificación que obtiene los resultados del historial de encuentros y muestra el ELO de los modelos.
Luego, cuando un usuario envía un modelo entrenado al Hub, se evalúa y clasifica frente a otros. Gracias a esto, podemos evaluar tus agentes contra agentes de otros en un entorno multiagente.
Además de ser una herramienta útil para alojar competencias multiagentes, creemos que esta herramienta también puede ser una técnica de evaluación sólida en entornos multiagentes. Al jugar contra muchas políticas, tus agentes se evalúan frente a una amplia gama de comportamientos. Esto debería darte una buena idea de la calidad de tu política.
- Ajuste de Fine-Tuning Eficiente en Parámetros usando 🤗 PEFT
- Generación de texto a partir de imágenes sin entrenamiento previo con BLIP-2
- Hugging Face y AWS se asocian para hacer que la IA sea más accesible
Veamos cómo funciona con nuestro primer anfitrión de competencia: SoccerTwos Challenge.
¿Cómo funciona IA vs. IA?
IA vs. IA es una herramienta de código abierto desarrollada en Hugging Face para clasificar la fuerza de los modelos de aprendizaje por refuerzo en un entorno multiagente.
La idea es obtener una medida relativa de habilidad en lugar de una medida objetiva haciendo que los modelos jueguen continuamente entre sí y utilizando los resultados de los encuentros para evaluar su rendimiento en comparación con todos los demás modelos y, por lo tanto, obtener una visión de la calidad de su política sin requerir métricas clásicas.
Cuanto más agentes se envíen para una tarea o entorno determinado, más representativa se vuelve la clasificación.
Para generar una clasificación basada en los resultados de los encuentros en un entorno competitivo, decidimos basar las clasificaciones en el sistema de clasificación ELO.
El concepto principal es que después de que termina un encuentro, la clasificación de ambos jugadores se actualiza en función del resultado y las clasificaciones que tenían antes del juego. Cuando un usuario con una clasificación alta vence a uno con una clasificación baja, no obtendrá muchos puntos. Del mismo modo, el perdedor no perderá muchos puntos en este caso.
Por el contrario, si un jugador con una clasificación baja gana sorprendentemente contra uno con una clasificación alta, tendrá un efecto más significativo en ambas clasificaciones.
En nuestro contexto, mantuvimos el sistema lo más simple posible sin agregar ninguna alteración a las cantidades ganadas o perdidas en función de las clasificaciones iniciales del jugador. Como tal, la ganancia y la pérdida siempre serán el opuesto perfecto (+10 / -10, por ejemplo), y la clasificación ELO promedio se mantendrá constante en la clasificación inicial. La elección de una clasificación ELO inicial de 1200 es completamente arbitraria.
Si quieres aprender más sobre ELO y ver algunos ejemplos de cálculo, escribimos una explicación en nuestro curso de Aprendizaje por Refuerzo Profundo aquí.
Utilizando esta clasificación, es posible generar encuentros entre modelos con fortalezas comparables automáticamente. Hay varias formas de crear un sistema de emparejamiento, pero aquí decidimos mantenerlo bastante simple al tiempo que garantizamos una cantidad mínima de diversidad en los enfrentamientos y también mantenemos la mayoría de los encuentros con clasificaciones opuestas bastante cercanas.
Así es como funciona el algoritmo:
- Reunir todos los modelos disponibles en el Hub. Los nuevos modelos obtienen una clasificación inicial de 1200, mientras que los demás mantienen la clasificación que han obtenido/perdido en sus encuentros anteriores.
- Crear una cola con todos estos modelos.
- Extraer el primer elemento (modelo) de la cola, y luego extraer otro modelo aleatorio en esta cola de los n modelos con las clasificaciones más cercanas al primer modelo.
- Simular este encuentro cargando ambos modelos en el entorno (por ejemplo, un ejecutable de Unity) y recopilando los resultados. Para esta implementación, enviamos los resultados a un conjunto de datos de Hugging Face en el Hub.
- Calcular la nueva clasificación de ambos modelos en función del resultado recibido y la fórmula ELO.
- Continuar extrayendo modelos de a dos y simulando los encuentros hasta que quede uno o cero modelos en la cola.
- Guardar las clasificaciones resultantes y volver al paso 1
Para ejecutar este proceso de emparejamiento continuamente, utilizamos hardware gratuito de Hugging Face Spaces con un programador para mantener el proceso de emparejamiento en ejecución como una tarea en segundo plano.
El Espacios también se utiliza para obtener las clasificaciones ELO de cada modelo que ya se ha jugado y, a partir de ello, mostrar un ranking de líderes en el que todos pueden comprobar el progreso de los modelos.
El proceso generalmente utiliza varios conjuntos de datos de Hugging Face para proporcionar persistencia de datos (aquí, historial de partidos y clasificaciones de modelos).
Dado que el proceso también guarda el historial de partidos, es posible ver los resultados exactos de cualquier modelo dado. Esto puede permitirte, por ejemplo, verificar por qué tu modelo tiene dificultades con otro, sobre todo utilizando otro Espacio de demostración para visualizar partidos como este.
Por ahora, este experimento se está ejecutando con el entorno MLAgent SoccerTwos para el Curso de Aprendizaje Profundo RL de Hugging Face, sin embargo, el proceso y la implementación, en general, son muy independientes del entorno y podrían utilizarse para evaluar de forma gratuita una amplia gama de configuraciones adversarias de múltiples agentes.
Por supuesto, es importante recordar una vez más que esta evaluación es una clasificación relativa entre las fortalezas de los agentes presentados, y las clasificaciones por sí mismas no tienen un significado objetivo contrario a otras métricas. Solo representa cuán bien o mal se desempeña un modelo en comparación con los otros modelos en el conjunto. Sin embargo, dado un conjunto de modelos lo suficientemente grande y variado (y suficientes partidos jugados), esta evaluación se convierte en una forma muy sólida de representar el rendimiento general de un modelo.
Nuestro primer experimento de desafío IA vs. IA: Desafío SoccerTwos ⚽
Este desafío es la Unidad 7 de nuestro Curso gratuito de Aprendizaje Profundo por Reforzamiento. Comenzó el 1 de febrero y finalizará el 30 de abril.
Si estás interesado, no es necesario participar en el curso para poder participar en la competencia. Puedes comenzar aquí 👉 https://huggingface.co/deep-rl-course/unit7/introduction
En esta Unidad, los lectores aprendieron los conceptos básicos del aprendizaje por refuerzo de múltiples agentes (MARL) entrenando a un equipo de fútbol 2 contra 2 ⚽
El entorno utilizado fue creado por el equipo de Unity ML-Agents. El objetivo es simple: tu equipo necesita marcar un gol. Para lograrlo, necesitan vencer al equipo contrario y colaborar con su compañero.
Además del ranking de líderes, creamos una demostración de Espacio donde las personas pueden elegir dos equipos y visualizarlos jugando 👉 https://huggingface.co/spaces/unity/SoccerTwos
Este experimento va bien, ya que tenemos 48 modelos en el ranking 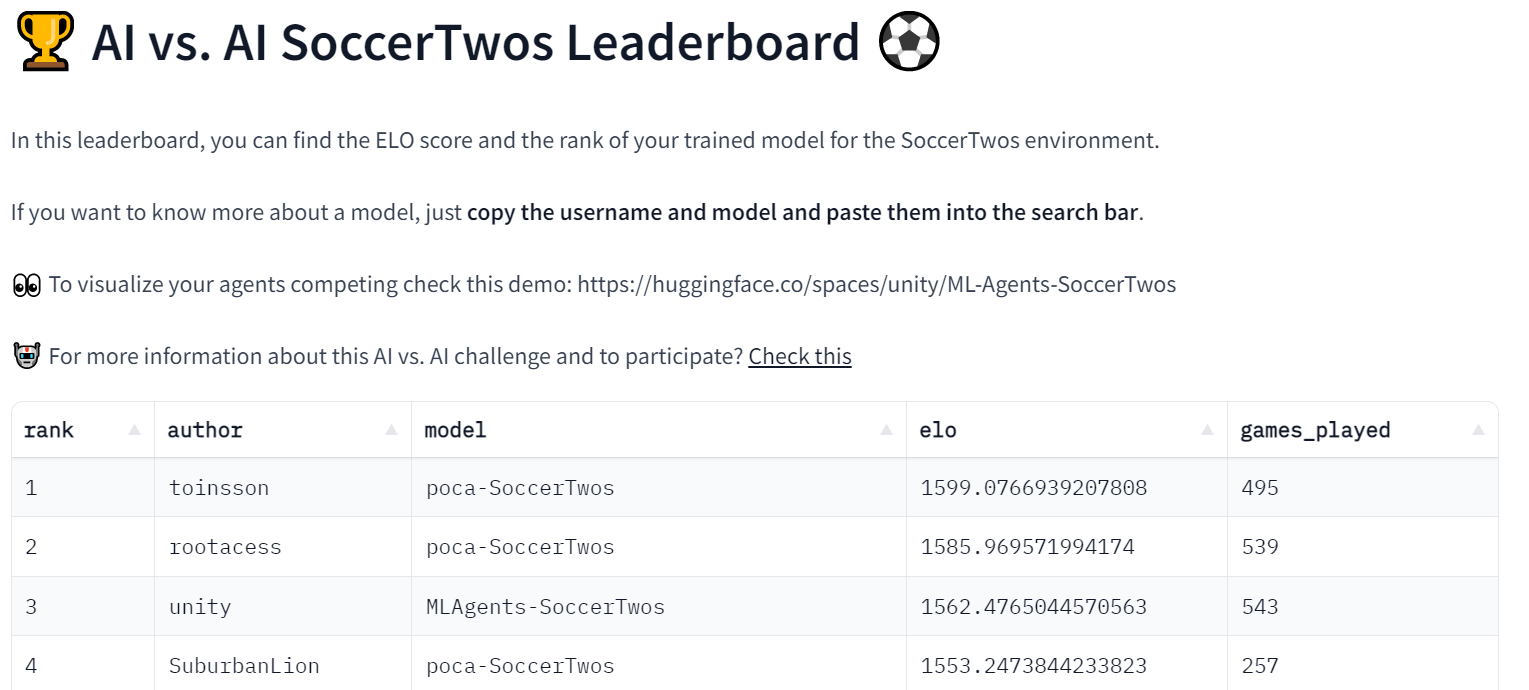
También creamos un canal de Discord llamado ai-vs-ai-competition para que las personas puedan interactuar con otros y compartir consejos.
Conclusión y próximos pasos
Dado que la herramienta que desarrollamos es independiente del entorno, queremos organizar más desafíos en el futuro con PettingZoo y otros entornos de múltiples agentes. Si tienes algunos entornos o desafíos que te gustaría realizar, no dudes en comunicarte con nosotros.
En el futuro, organizaremos múltiples competiciones de múltiples agentes con esta herramienta y los entornos que hemos creado, como SnowballFight.
Además de ser una herramienta útil para organizar competiciones de múltiples agentes, creemos que esta herramienta también puede ser una técnica de evaluación sólida en entornos de múltiples agentes: al jugar contra muchas políticas, tus agentes se evalúan frente a una amplia gama de comportamientos y tendrás una buena idea de la calidad de tu política.
La mejor manera de mantenerse en contacto es unirse a nuestro servidor de Discord para interactuar con nosotros y con la comunidad.
****************Cita****************
Cita: Si encontraste esto útil para tu trabajo académico, considera citar nuestro trabajo, en texto:
Cochet, Simonini, "Introducing AI vs. AI a deep reinforcement learning multi-agents competition system", Hugging Face Blog, 2023.
Cita en formato BibTeX:
@article{cochet-simonini2023,
author = {Cochet, Carl and Simonini, Thomas},
title = {Introducing AI vs. AI a deep reinforcement learning multi-agents competition system},
journal = {Hugging Face Blog},
year = {2023},
note = {https://huggingface.co/blog/aivsai},
}We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Swift 🧨Difusores – Difusión rápida y estable para Mac
- Directrices éticas para el desarrollo de la biblioteca Diffusers
- ControlNet en 🧨 Difusores
- Creando Inteligencia Artificial de Preservación de Privacidad con Substra
- Aprendizaje Federado utilizando Hugging Face y Flower
- Acelerando la Inferencia de Difusión Estable en CPUs Intel
- Inferencia rápida en modelos de lenguaje grandes BLOOMZ en el acelerador Habana Gaudi2





