Una introducción práctica a los LLMs
Introducción práctica a LLMs
3 niveles de uso de LLMs en la práctica
Este es el primer artículo de una serie sobre el uso de Modelos de Lenguaje Grande (LLMs) en la práctica. Aquí daré una introducción a los LLMs y presentaré 3 niveles de trabajo con ellos. En futuros artículos se explorarán aspectos prácticos de los LLMs, como el uso de la API pública de OpenAI, la biblioteca Python de Hugging Face Transformers, cómo ajustar los LLMs y cómo construir un LLM desde cero.
¿Qué es un LLM?
LLM es la abreviatura de Modelo de Lenguaje Grande, que es una innovación reciente en IA y aprendizaje automático. Este nuevo y poderoso tipo de IA se hizo viral en diciembre de 2022 con el lanzamiento de ChatGPT.
Para aquellos lo suficientemente iluminados como para vivir fuera del mundo del zumbido de la IA y los ciclos de noticias tecnológicas, ChatGPT es una interfaz de chat que se ejecutaba en un LLM llamado GPT-3 (ahora actualizado a GPT-3.5 o GPT-4 en el momento de escribir esto).
Si has utilizado ChatGPT, es obvio que esto no es tu chatbot tradicional de AOL Instant Messenger o el servicio de atención al cliente de tu tarjeta de crédito.
- 3 Conceptos que Debes Conocer sobre Estructuras de Datos en Python
- Aprovechando el poder de los grafos de conocimiento enriqueciendo un LLM con datos estructurados
- Encendiendo la Combustión Cognitiva Fusionando Arquitecturas Cognitivas y LLMs para Construir la Próxima Computadora
Este se siente diferente.
¿Qué hace que un LLM sea “grande”?
Cuando escuché el término “Modelo de Lenguaje Grande”, una de mis primeras preguntas fue, ¿cómo es esto diferente de un modelo de lenguaje “regular”?
Un modelo de lenguaje es más genérico que un modelo de lenguaje grande. Al igual que todos los cuadrados son rectángulos pero no todos los rectángulos son cuadrados. Todos los LLMs son modelos de lenguaje, pero no todos los modelos de lenguaje son LLMs.
De acuerdo, los LLMs son un tipo especial de modelo de lenguaje, pero ¿qué los hace especiales?
Hay 2 propiedades clave que distinguen a los LLMs de otros modelos de lenguaje. Una es cuantitativa y la otra es cualitativa.
- Cuantitativamente, lo que distingue a un LLM es el número de parámetros utilizados en el modelo. Los LLMs actuales tienen del orden de 10-100 mil millones de parámetros [1].
- Cualitativamente, algo notable sucede cuando un modelo de lenguaje se vuelve “grande”. Exhibe propiedades llamadas propiedades emergentes, como el aprendizaje de cero disparo [1]. Estas son propiedades que parecen aparecer repentinamente cuando un modelo de lenguaje alcanza un tamaño suficientemente grande.
Aprendizaje de cero disparo
La principal innovación de GPT-3 (y otros LLMs) es que es capaz de realizar aprendizaje de cero disparo en una amplia variedad de contextos [2]. Esto significa que ChatGPT puede realizar una tarea aunque no haya sido entrenado explícitamente para hacerlo.
Aunque esto puede no ser gran cosa para nosotros, seres humanos altamente evolucionados, esta capacidad de aprendizaje de cero disparo contrasta notablemente con el paradigma anterior de aprendizaje automático.
Anteriormente, un modelo necesitaba ser entrenado explícitamente en la tarea que pretendía realizar para tener un buen rendimiento. Esto podía requerir desde 1,000 hasta 1 millón de ejemplos de entrenamiento preetiquetados.
Por ejemplo, si quisieras que una computadora realizara traducción de idiomas, análisis de sentimientos e identificación de errores gramaticales. Cada una de estas tareas requeriría un modelo especializado entrenado en un gran conjunto de ejemplos etiquetados. Ahora, sin embargo, los LLMs pueden hacer todas estas cosas sin entrenamiento explícito.
¿Cómo funcionan los LLMs?
La tarea principal utilizada para entrenar la mayoría de los LLMs de última generación es la predicción de palabras. En otras palabras, dada una secuencia de palabras, ¿cuál es la distribución de probabilidad de la siguiente palabra?
Por ejemplo, dada la secuencia “Escucha a tu ____”, las palabras más probables podrían ser: corazón, instinto, cuerpo, padres, abuela, etc. Esto podría verse como la distribución de probabilidad mostrada a continuación.
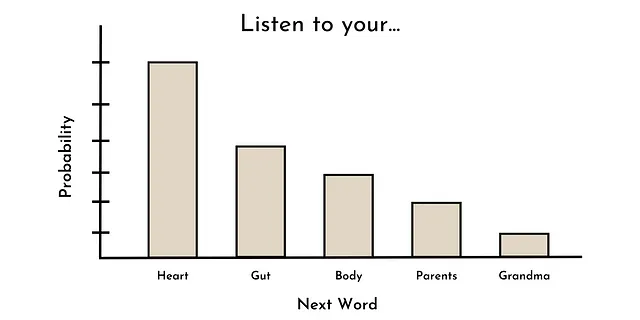
Curiosamente, esta es la misma forma en que muchos modelos de lenguaje (no grandes) han sido entrenados en el pasado (por ejemplo, GPT-1) [3]. Sin embargo, por alguna razón, cuando los modelos de lenguaje alcanzan un cierto tamaño (digamos ~10B de parámetros), estas habilidades (emergentes), como el aprendizaje sin ejemplos, pueden empezar a surgir [1].
Aunque no hay una respuesta clara sobre por qué ocurre esto (solo especulaciones por ahora), está claro que los LLMs son una tecnología poderosa con innumerables casos de uso potenciales.
3 Niveles de Uso de LLMs
Ahora pasamos a cómo utilizar esta tecnología poderosa en la práctica. Si bien hay innumerables casos de uso potenciales para los LLMs, aquí los categorizo en 3 niveles ordenados por el conocimiento técnico requerido y los recursos computacionales. Empezamos por el más accesible.
Nivel 1: Ingeniería de Prompt
El primer nivel de uso de los LLMs en la práctica es la ingeniería de prompt, que defino como el uso de un LLM tal como está, es decir, sin cambiar ningún parámetro del modelo. Aunque muchas personas técnicamente inclinadas parecen menospreciar la idea de la ingeniería de prompt, esta es la forma más accesible de utilizar los LLMs (tanto técnicamente como económicamente) en la práctica.
Existen 2 formas principales de realizar la ingeniería de prompt: la Forma Fácil y la Forma Menos Fácil.
Forma Fácil: ChatGPT (u otra interfaz conveniente de LLM) — El beneficio clave de este método es la conveniencia. Herramientas como ChatGPT proporcionan una forma intuitiva, sin costo y sin necesidad de programación para usar un LLM (no puede ser más fácil que eso).
Sin embargo, la conveniencia a menudo tiene un costo. En este caso, existen 2 inconvenientes clave en este enfoque. El primero es la falta de funcionalidad. Por ejemplo, ChatGPT no permite a los usuarios personalizar los parámetros de entrada del modelo (por ejemplo, la temperatura o la longitud máxima de respuesta), que son valores que modulan las salidas del LLM. El segundo inconveniente es que las interacciones con la interfaz de ChatGPT no se pueden automatizar fácilmente y, por lo tanto, aplicar a casos de uso a gran escala.
Aunque estos inconvenientes pueden ser determinantes para algunos casos de uso, ambos se pueden mitigar si llevamos la ingeniería de prompt un paso más allá.
Forma Menos Fácil: Interactuar directamente con el LLM — Podemos superar algunos de los inconvenientes de ChatGPT interactuando directamente con un LLM a través de interfaces programáticas. Esto podría ser a través de APIs públicas (por ejemplo, la API de OpenAI) o ejecutando un LLM localmente (usando bibliotecas como Transformers).
Aunque esta forma de realizar la ingeniería de prompt es menos conveniente (ya que requiere conocimientos de programación y posibles costos de API), proporciona una forma personalizable, flexible y escalable de utilizar los LLMs en la práctica. Los artículos futuros de esta serie discutirán formas tanto pagas como gratuitas de realizar este tipo de ingeniería de prompt.
Aunque la ingeniería de prompt (como se define aquí) puede manejar la mayoría de las aplicaciones potenciales de los LLMs, depender de un modelo genérico, tal como está, puede resultar en un rendimiento subóptimo para casos de uso específicos. Para estas situaciones, podemos pasar al siguiente nivel de uso de los LLMs.
Nivel 2: Ajuste Fino del Modelo
El segundo nivel de uso de un LLM es el ajuste fino del modelo, que definiré como tomar un LLM existente y modificarlo para un caso de uso particular cambiando al menos 1 parámetro del modelo (internamente), es decir, pesos y sesgos. En esta categoría, también incluiré el aprendizaje por transferencia, es decir, utilizar alguna parte de un LLM existente para desarrollar otro modelo.
La puesta a punto generalmente consta de 2 pasos. Paso 1: Obtener un LLM pre-entrenado. Paso 2: Actualizar los parámetros del modelo para una tarea específica dada (normalmente con miles) de ejemplos etiquetados de alta calidad.
Los parámetros del modelo son los que definen la representación interna del texto de entrada del LLM. Por lo tanto, al ajustar estos parámetros para una tarea particular, las representaciones internas se optimizan para la tarea de puesta a punto (o al menos esa es la idea).
Este enfoque es poderoso para el desarrollo de modelos porque un número relativamente pequeño de ejemplos y recursos computacionales pueden producir un rendimiento excepcional del modelo.
La desventaja, sin embargo, es que requiere significativamente más experiencia técnica y recursos computacionales que la ingeniería de indicaciones. En un artículo futuro, intentaré mitigar esta desventaja revisando técnicas de puesta a punto y compartiendo ejemplos de código Python.
Aunque la ingeniería de indicaciones y la puesta a punto del modelo probablemente puedan manejar el 99% de las aplicaciones de LLM, hay casos en los que uno debe ir aún más lejos.
Nivel 3: Construye tu propio LLM
La tercera y última forma de usar un LLM en la práctica es construir el tuyo propio. En términos de parámetros del modelo, esto es donde creas todos los parámetros del modelo desde cero.
Un LLM es principalmente un producto de sus datos de entrenamiento. Por lo tanto, para algunas aplicaciones, puede ser necesario seleccionar cuidadosamente corpus de texto personalizados y de alta calidad para el entrenamiento del modelo, por ejemplo, un corpus de investigación médica para el desarrollo de una aplicación clínica.
La mayor ventaja de este enfoque es que puedes personalizar completamente el LLM para tu caso de uso particular. Esta es la máxima flexibilidad. Sin embargo, como suele ser el caso, la flexibilidad tiene un costo en términos de conveniencia.
Dado que la clave para el rendimiento del LLM es la escala, construir un LLM desde cero requiere enormes recursos computacionales y experiencia técnica. En otras palabras, esto no va a ser un proyecto de fin de semana en solitario, sino más bien un equipo completo trabajando durante meses, si no años, con un presupuesto de 7-8F.
No obstante, en un artículo futuro de esta serie, exploraremos técnicas populares para desarrollar LLMs desde cero.
Conclusión
Aunque hay suficiente publicidad sobre los LLM en estos días, son una innovación poderosa en el campo de la IA. Aquí proporcioné una introducción sobre qué son los LLM y cómo se pueden utilizar en la práctica. El próximo artículo de esta serie dará una guía para principiantes sobre la API de Python de OpenAI para ayudar a impulsar su próximo caso de uso de LLM.
Recursos
Conéctese: Mi sitio web | Reserva una llamada | Pregúntame cualquier cosa
Redes sociales: YouTube 🎥 | LinkedIn | Twitter
Soporte: Conviértete en miembro ⭐️ | Invítame un café ☕️
Los Emprendedores de Datos
Una comunidad para emprendedores en el espacio de datos. 👉 ¡Únete al Discord!
VoAGI.com
[1] Encuesta de Modelos de Lenguaje Grandes. arXiv:2303.18223 [cs.CL]
[2] Documento de GPT-3. arXiv:2005.14165 [cs.CL]
[3] Radford, A., & Narasimhan, K. (2018). Mejorando la Comprensión del Lenguaje mediante el Pre-Entrenamiento Generativo. (Documento de GPT-1)
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Construyendo un Modelo de Lenguaje Pequeño (SLM) con el Algoritmo Jaro-Winkler para Mejorar y Potenciar los Errores de Ortografía
- Dominando lo desconocido con GPT-4 y el patrón de interacción invertida
- Reseña de Jasper AI (julio de 2023) ¿El mejor generador de escritura de IA?
- Cómo resolver problemas de dependencias de Python con Anaconda en Windows
- Mejora la predicción de datos tabulares con el modelo de lenguaje grande a través de la API de OpenAI
- ¡Deja de ignorar a Julia! Aprende ahora y agradece a tu yo más joven en el futuro
- Errores que los nuevos científicos de datos novatos deben evitar





