Aprendizaje Profundo en Sistemas de Recomendación Una introducción.
Introducción al Aprendizaje Profundo en Sistemas de Recomendación.
Un recorrido por los avances tecnológicos más importantes detrás de los modernos sistemas de recomendación industrial

Los sistemas de recomendación se encuentran entre las aplicaciones de Machine Learning industrial que evolucionan más rápidamente en la actualidad. Desde el punto de vista empresarial, esto no es una sorpresa: mejores recomendaciones atraen a más usuarios. Es así de simple.
Sin embargo, la tecnología subyacente está lejos de ser simple. Desde el surgimiento del aprendizaje profundo, impulsado por la comercialización de las GPU, los sistemas de recomendación se han vuelto cada vez más complejos.
En este artículo, haremos un recorrido por algunos de los avances de modelado más importantes de la última década, reconstruyendo aproximadamente los puntos clave que marcaron el surgimiento del aprendizaje profundo en los sistemas de recomendación. Es una historia de avances tecnológicos, exploración científica y una carrera armamentística que abarca continentes y cooperaciones.
Asegúrate el cinturón. Nuestro recorrido comienza en Singapur en 2017.
- ¿Reemplazará la inteligencia artificial a los humanos?
- ¿Quiénes son los Científicos de Datos Ciudadanos y qué hacen?
- La trayectoria de ingeniería de datos del Sr. Pavan impulsa el éxito empresarial.
NCF (Universidad de Singapur, 2017)
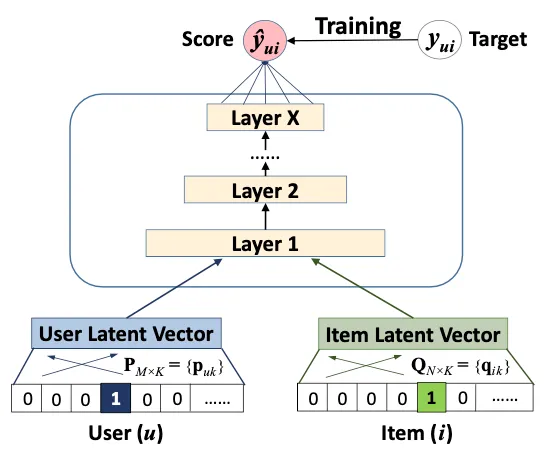
Cualquier discusión sobre el aprendizaje profundo en los sistemas de recomendación estaría incompleta sin mencionar uno de los avances más importantes en el campo, la Filtro Colaborativo Neural (NCF), presentado en He et al (2017) de la Universidad de Singapur.
Antes de NCF, el estándar de oro en los sistemas de recomendación era la factorización de matrices, en la que aprendemos vectores latentes (también conocidos como embeddings) tanto para los usuarios como para los elementos, y luego generamos recomendaciones para un usuario tomando el producto punto entre el vector del usuario y los vectores del elemento. Cuanto más cercano sea el producto punto a 1, como sabemos por álgebra lineal, mejor será la coincidencia predicha. Como tal, la factorización de matrices se puede ver simplemente como un modelo lineal de factores latentes.
La idea clave en NCF es reemplazar el producto interno en la factorización de matrices con una red neuronal. En la práctica, esto se hace primero concatenando los embeddings de usuario y elemento, y luego pasándolos a un perceptrón multicapa (MLP) con una única tarea que predice el compromiso del usuario, como un clic. Tanto los pesos de MLP como los pesos de embedding (que asignan identificadores a sus respectivos embeddings) se aprenden durante el entrenamiento del modelo mediante la retropropagación de los gradientes de pérdida.
La hipótesis detrás de NCF es que las interacciones usuario/elemento no son lineales, como se asume en la factorización de matrices, sino no lineales. Si eso es cierto, deberíamos ver un mejor rendimiento a medida que agregamos más capas al MLP. Y eso es precisamente lo que encuentra He et al. Con 4 capas, pueden superar a los mejores algoritmos de factorización de matrices en ese momento en un 5% en los conjuntos de datos de referencia Movielens y Pinterest.
He et al demostró que hay un inmenso valor del aprendizaje profundo en los sistemas de recomendación, marcando la transición pivotal lejos de la factorización de matrices y hacia los recomendadores profundos.
Wide & Deep (Google, 2016)
Nuestro recorrido continúa desde Singapur hasta Mountain View, California.
Aunque NCF revolucionó el dominio de los sistemas de recomendación, le falta un ingrediente importante que resultó ser extremadamente importante para el éxito de los recomendadores: características cruzadas. La idea de las características cruzadas se ha popularizado en el artículo de Google de 2016 “Aprendizaje amplio y profundo para sistemas de recomendación”.
¿Qué es una característica cruzada? Es una característica de segundo orden que se crea “cruzando” dos de las características originales. Por ejemplo, en Google Play Store, las características de primer orden incluyen la aplicación impresionada o la lista de aplicaciones instaladas por el usuario. Estas dos pueden combinarse para crear características cruzadas poderosas, como
AND(user_installed_app='netflix', impression_app='hulu')lo cual es 1 si el usuario tiene instalado Netflix y la aplicación impresionada es Hulu.
Las características cruzadas también pueden ser más generalizadas, como por ejemplo
AND(user_installed_category='video', impression_category='music')y así sucesivamente. Los autores argumentan que agregar características cruzadas de diferentes granularidades permite tanto la memorización (a partir de cruces más granulares) como la generalización (a partir de cruces menos granulares).
La elección arquitectónica clave en Wide&Deep es tener tanto un módulo amplio, que es una capa lineal que toma todas las características cruzadas directamente como entradas, y un módulo profundo, que es esencialmente un NCF, y luego combinar ambos módulos en una sola salida de tarea que aprende de los compromisos usuario/aplicación.
Y de hecho, Wide&Deep funciona notablemente bien: los autores encuentran un aumento en las adquisiciones de aplicaciones en línea del 1% al pasar de solo profundidad a ancho y profundidad. Considere que Google genera decenas de miles de millones en ingresos cada año desde su Play Store, y es fácil ver cuán impactante fue Wide&Deep.
DCN (Google, 2017)
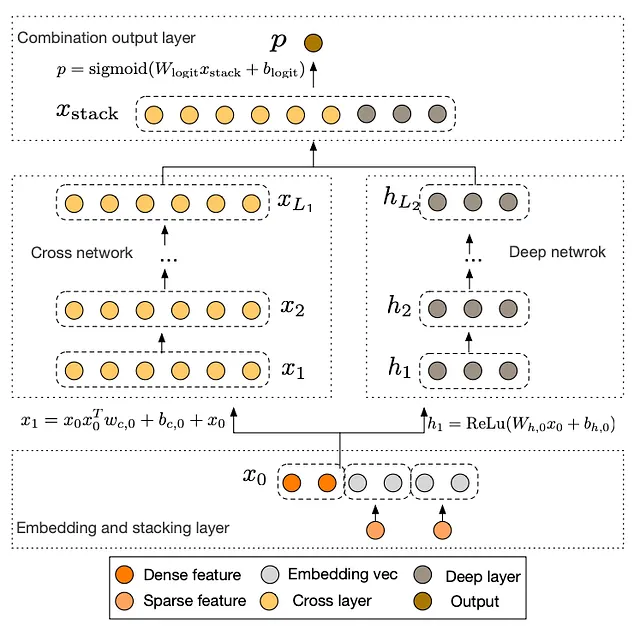
Wide&Deep ha demostrado la importancia de las características cruzadas, sin embargo, tiene una gran desventaja: las características cruzadas deben ser diseñadas manualmente, lo cual es un proceso tedioso que requiere recursos de ingeniería, infraestructura y experiencia en el dominio. Las características cruzadas al estilo Wide & Deep son costosas. No escalan.
Entra “redes neuronales profundas y cruzadas” (DCN), presentado en un artículo de 2017, también de Google. La idea clave en DCN es reemplazar el componente amplio en Wide&Deep con una “red neuronal cruzada”, una red neuronal dedicada a aprender características cruzadas de orden arbitrariamente alto.
¿Qué hace que una red neuronal cruzada sea diferente de una MLP estándar? Como recordatorio, en un MLP, cada neurona en la siguiente capa es una combinación lineal de todas las capas en la capa anterior:
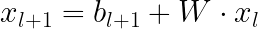
En contraste, en la red neuronal cruzada, la siguiente capa se construye formando combinaciones de segundo orden de la primera capa consigo misma:
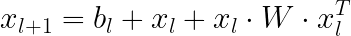
Por lo tanto, una red neuronal cruzada de profundidad L aprenderá características cruzadas en forma de polinomios de grados hasta L. Cuanto más profunda sea la red neuronal, se aprenderán interacciones de orden superior.
Y de hecho, los experimentos confirman que DCN funciona. En comparación con un modelo solo con el componente profundo, DCN tiene un logloss 0,1% menor (lo que se considera estadísticamente significativo) en el conjunto de datos de referencia de anuncios de visualización de Criteo. ¡Y eso sin ningún diseño manual de características, como en Wide&Deep!
(Habría sido bueno ver una comparación entre DCN y Wide&Deep. Lamentablemente, los autores de DCN no tenían un buen método para crear manualmente características cruzadas para el conjunto de datos de Criteo, y por lo tanto omitieron esta comparación).
DeepFM (Huawei, 2017)
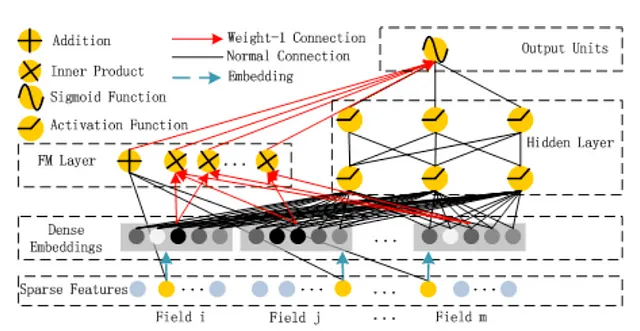
A continuación, nuestro recorrido nos lleva de Google en 2017 a Huawei en 2017.
La solución de Huawei para la recomendación profunda, “DeepFM”, también reemplaza el diseño de características manual en el componente amplio de Wide&Deep con una red neuronal dedicada que aprende características cruzadas. Sin embargo, a diferencia de DCN, el componente amplio no es una red neuronal cruzada, sino una capa de “máquina de factorización” (FM).
¿Qué hace la capa FM? Simplemente toma el producto punto de todos los pares de embeddings. Por ejemplo, si un recomendador de películas toma 4 características de identificación como entradas, como el id de usuario, el id de película, los ids de los actores y el id del director, entonces el modelo aprende embeddings para todas estas características de identificación, y la capa FM calcula 6 productos punto, correspondientes a las combinaciones usuario-película, usuario-actor, usuario-director, película-actor, película-director y actor-director. Es un regreso de la idea de la factorización de matrices. La salida de la capa FM se combina luego con la salida del componente profundo en una salida activada por sigmoide, lo que resulta en la predicción del modelo.
Y de hecho, como habrás adivinado, DeepFM ha demostrado funcionar. Los autores muestran que DeepFM supera a una gran cantidad de competidores (incluyendo el Wide&Deep de Google) en más del 0,37% y 0,42% en términos de AUC y Logloss, respectivamente, en datos internos de la empresa.
DLRM (Meta, 2019)
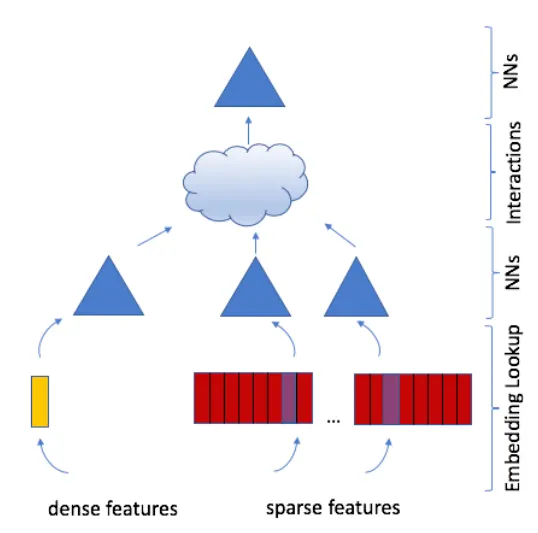
Dejemos a Google y Huawei por ahora. La siguiente parada en nuestro recorrido es Meta de 2019.
La arquitectura DLRM (“aprendizaje profundo para sistemas de recomendación”) de Meta, presentada en Naumov et al (2019), funciona de la siguiente manera: todas las características categóricas se transforman en embeddings utilizando tablas de embedding. Todas las características densas se pasan a una MLP que también calcula embeddings para ellas. Es importante destacar que todos los embeddings tienen la misma dimensión. Luego, simplemente calculamos el producto punto de todos los pares de embeddings, los concatenamos en un solo vector y pasamos ese vector a través de una MLP final con una sola tarea activada por sigmoide que produce la predicción.
DLRM es casi algo así como una versión simplificada de DeepFM: si tomamos DeepFM y eliminamos el componente profundo (manteniendo solo el componente FM), tenemos algo así como DLRM, pero sin la MLP densa de DLRM.
En los experimentos, Naumov et al muestran que DLRM supera a DCN en términos de precisión tanto en el entrenamiento como en la validación en el conjunto de datos de referencia de anuncios de display de Criteo. Este resultado indica que el componente profundo en DCN puede ser redundante, y todo lo que realmente necesitamos para hacer las mejores recomendaciones posibles son solo las interacciones de características, que en DLRM se capturan con los productos punto.
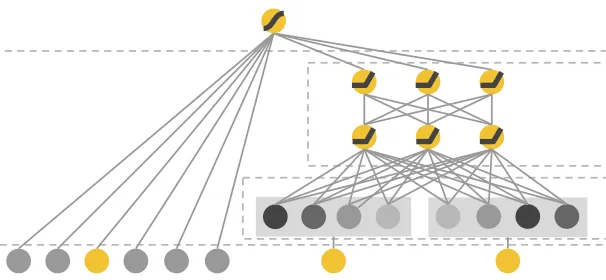
DHEN (Meta, 2022)
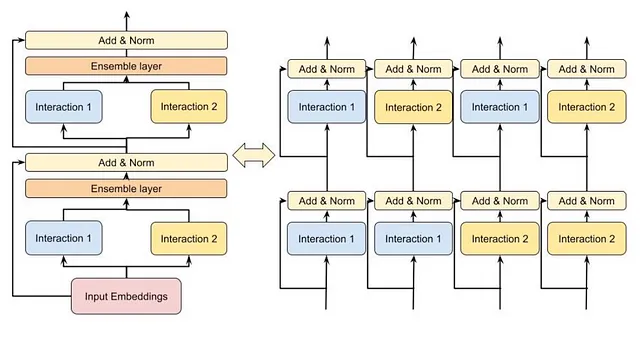
En contraste con DCN, las interacciones de características en DLRM están limitadas a ser de segundo orden solamente: son solo productos punto de todos los pares de embeddings. Volviendo al ejemplo de la película (con características de usuario, película, actores y director), las interacciones de segundo orden serían usuario-película, usuario-actor, usuario-director, película-actor, película-director y actor-director. Una interacción de tercer orden sería algo como usuario-película-director, actor-actor-usuario, director-actor-usuario, y así sucesivamente. ¡Ciertos usuarios pueden ser fanáticos de las películas de Steven Spielberg protagonizadas por Tom Hanks, y debería haber una función cruzada para eso! Lamentablemente, en el DLRM estándar, no la hay. Esa es una limitación importante.
Ingresa DHEN, el último documento fundamental en nuestro recorrido de los sistemas de recomendación modernos. DHEN significa “Red de Ensamblaje Jerárquico Profundo”, y la idea clave es crear una “jerarquía” de funciones cruzadas que crece más profundamente con el número de capas DHEN.
Es más fácil entender DHEN con un ejemplo simple primero. Supongamos que tenemos dos características de entrada que van a DHEN, y las denotamos como A y B (que podrían ser los IDs de usuario y video, por ejemplo). Un módulo DHEN de 2 capas crearía toda la jerarquía de funciones cruzadas hasta el segundo orden, a saber:
A, AxA, AxB, B, BxB,donde “x” es una sola interacción o una combinación de las siguientes 5 interacciones:
- producto punto,
- autoatención,
- convolución,
- lineal: y = Wx, o
- el módulo cruzado de DCN.
DHEN es una bestia y su complejidad computacional (debido a su naturaleza recursiva) es una pesadilla. Para hacer que funcione, los autores del artículo de DHEN tuvieron que inventar un nuevo paradigma de entrenamiento distribuido llamado “Paralelo de Datos Hibridos Fragmentados”, que logra un rendimiento 1.2X mayor que el estado del arte (en ese momento).
Pero lo más importante es que la bestia funciona: en sus experimentos con datos internos de tasa de clics, los autores miden una mejora del 0.27% en NE en comparación con DLRM, usando una pila de 8 (!) capas de DHEN.
Resumen
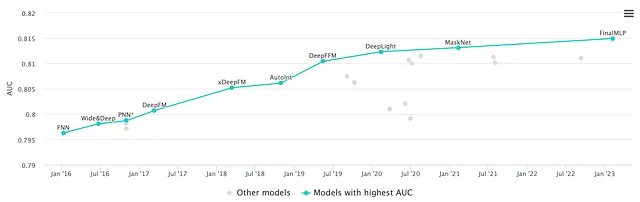
Y esto concluye nuestro recorrido. Permítanme resumir cada uno de estos hitos con un solo titular:
- NCF: Todo lo que necesitamos son incrustaciones para usuarios y elementos. MLP se encargará del resto.
- Wide&Deep: Las características cruzadas importan. De hecho, son tan importantes que las alimentamos directamente en la cabeza de la tarea.
- DCN: Las características cruzadas importan, pero no deben ser diseñadas a mano. Dejemos que la red neuronal cruzada maneje eso.
- DeepFM: Generemos características cruzadas en la capa FM en su lugar, y aún así mantengamos el componente profundo de Wide&Deep.
- DRLM: FM es todo lo que necesitamos, y también otro MLP dedicado para características densas.
- DHEN: FM no es suficiente. Necesitamos una jerarquía de interacciones de características de orden superior (más allá del segundo orden) y también una serie de optimizaciones para hacer que funcione en la práctica.
Y el viaje apenas comienza. En el momento de escribir esto, DCN ha evolucionado a DCN-M, DeepFM ha evolucionado a xDeepFM y el liderazgo de la competencia de Criteo ha sido reclamado por la última invención de Huawei, FinalMLP.
Dada la gran incentivación económica para mejores recomendaciones, es garantizado que continuaremos viendo nuevos avances en este dominio en un futuro previsible. Estén atentos.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- vLLM PagedAttention para una inferencia LLM 24 veces más rápida
- Las 10 herramientas poderosas de modelado de datos para conocer en 2023.
- Dominando la Ingeniería de Prompt para Desatar el Potencial de ChatGPT
- El Atlas de Literatura Biomédica podría ayudar a rastrear estudios falsificados.
- Gestión de dependencias de Python ¿Qué herramienta deberías elegir?
- Plugin Notable El plugin ChatGPT que automatiza el análisis de datos.
- De datos no estructurados a estructurados con LLMs






