Una Introducción Suave al Aprendizaje Profundo Bayesiano
Introducción al Aprendizaje Profundo Bayesiano
¡Bienvenido al apasionante mundo de la Programación Probabilística! Este artículo es una introducción suave al campo, solo necesitas una comprensión básica de Aprendizaje Profundo y estadísticas bayesianas.
Al final de este artículo, deberías tener una comprensión básica del campo, sus aplicaciones y cómo difiere de los métodos de aprendizaje profundo más tradicionales.
Si, al igual que yo, has oído hablar de Aprendizaje Profundo Bayesiano, y supones que implica estadísticas bayesianas, pero no sabes exactamente cómo se utiliza, estás en el lugar correcto.
Limitaciones del Aprendizaje Profundo Tradicional
Una de las principales limitaciones del aprendizaje profundo tradicional es que, aunque son herramientas muy poderosas, no proporcionan una medida de su incertidumbre.
Chat GPT puede decir información falsa con confianza absoluta. Los clasificadores emiten probabilidades que a menudo no están calibradas.
- Olvida ChatGPT, este nuevo asistente de IA está a años luz y cambiará la forma en que trabajas para siempre
- Revisión de Synthesys ¿El mejor generador de videos de IA? (agosto de 2023)
- Despacho basado en datos
La estimación de la incertidumbre es un aspecto crucial de los procesos de toma de decisiones, especialmente en áreas como la salud y los automóviles autónomos. Queremos que un modelo sea capaz de estimar cuándo está muy inseguro acerca de clasificar a un sujeto con cáncer cerebral, y en este caso requerimos un diagnóstico adicional por parte de un experto médico. De manera similar, queremos que los autos autónomos sean capaces de reducir la velocidad cuando identifican un nuevo entorno.
Para ilustrar lo mal que una red neuronal puede estimar el riesgo, veamos una Red Neuronal Clasificadora muy simple con una capa softmax al final.
La función softmax tiene un nombre muy comprensible, es una función Soft Max, lo que significa que es una versión “más suave” de una función máxima. La razón de esto es que si hubiéramos elegido una función máxima “dura”, tomando la clase con la probabilidad más alta, tendríamos un gradiente cero para todas las demás clases.
Con softmax, la probabilidad de una clase puede ser cercana a 1, pero nunca exactamente 1. Y debido a que la suma de las probabilidades de todas las clases es 1, todavía fluye un poco de gradiente hacia las otras clases.
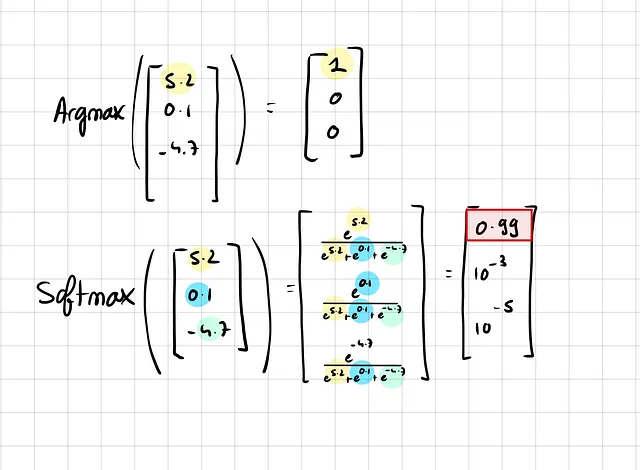
Sin embargo, la función softmax también presenta un problema. Produce probabilidades que están pobremente calibradas. Pequeños cambios en los valores antes de aplicar la función softmax son aplastados por la exponencial, lo que provoca cambios mínimos en las probabilidades de salida.
Esto a menudo resulta en sobreconfianza, con el modelo otorgando altas probabilidades para ciertas clases incluso frente a la incertidumbre, una característica inherente a la naturaleza ‘máxima’ de la función softmax.
Comparar una Red Neuronal Tradicional (NN) con una Red Neuronal Bayesiana (BNN) puede resaltar la importancia de la estimación de la incertidumbre. La certeza de una BNN es alta cuando encuentra distribuciones familiares de los datos de entrenamiento, pero a medida que nos alejamos de las distribuciones conocidas, la incertidumbre aumenta, proporcionando una estimación más realista.
Esto es cómo puede lucir una estimación de la incertidumbre:
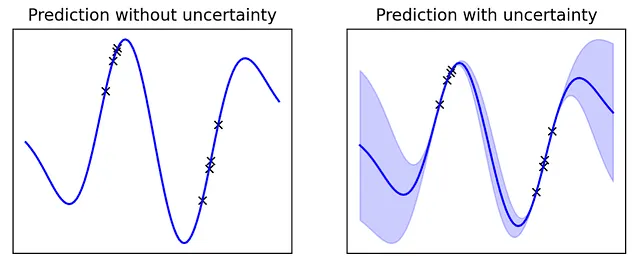
Puedes ver que cuando estamos cerca de la distribución que hemos observado durante el entrenamiento, el modelo está muy seguro, pero a medida que nos alejamos de la distribución conocida, la incertidumbre aumenta.
Breve Resumen de las Estadísticas Bayesianas
Hay un teorema central que debes conocer en las estadísticas bayesianas: El Teorema de Bayes.

- La probabilidad a priori es la distribución de theta que consideramos más probable antes de cualquier observación. Por ejemplo, para un lanzamiento de moneda podríamos asumir que la probabilidad de obtener una cara es una distribución gaussiana alrededor de p = 0.5
- Si queremos poner el menor sesgo inductivo posible, también podríamos decir que p es uniforme entre [0,1].
- La v verosimilitud se refiere a dado un parámetro theta, qué tan probable es que hayamos obtenido nuestras observaciones X, Y
- La verosimilitud marginal es la verosimilitud integrada sobre todos los theta posibles. Se llama “marginal” porque marginalizamos theta al promediarlo sobre todas las probabilidades.
La idea clave para entender las Estadísticas Bayesianas es que se parte de una priori, que es nuestra mejor suposición de cómo podría ser el parámetro (es una distribución). Y con las observaciones que se hacen, se ajusta esa suposición y se obtiene una distribución posterior.
Es importante tener en cuenta que tanto la priori como la posteriori no son estimaciones puntuales de theta, sino distribuciones de probabilidad.
Para ilustrar esto:
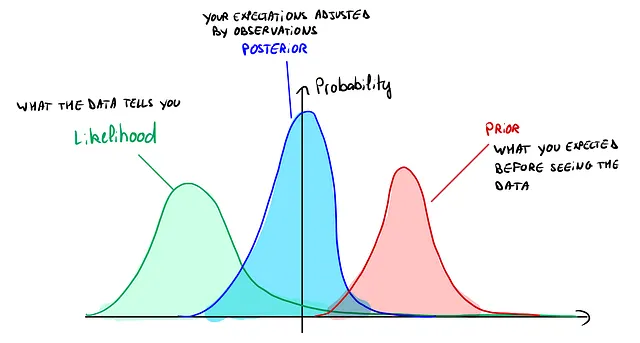
En esta imagen se puede ver que la priori se desplaza hacia la derecha, pero la verosimilitud equilibra nuestra priori hacia la izquierda, y la posteriori se encuentra en algún punto intermedio.
Introducción al Aprendizaje Profundo Bayesiano
El Aprendizaje Profundo Bayesiano es un enfoque que combina dos poderosas teorías matemáticas: Estadísticas Bayesianas y Aprendizaje Profundo.
La distinción esencial con respecto al Aprendizaje Profundo tradicional radica en el tratamiento de los pesos del modelo:
En el Aprendizaje Profundo tradicional, se entrena un modelo desde cero, se inicializa aleatoriamente un conjunto de pesos y se entrena el modelo hasta que converge a un nuevo conjunto de parámetros. Se aprende un único conjunto de pesos.
Por el contrario, el Aprendizaje Profundo Bayesiano adopta un enfoque más dinámico. Se comienza con una creencia priori sobre los pesos, asumiendo a menudo que siguen una distribución normal. A medida que exponemos nuestro modelo a los datos, ajustamos esta creencia y actualizamos la distribución posterior de los pesos. En esencia, se aprende una distribución de probabilidad sobre los pesos en lugar de un único conjunto.
Durante la inferencia, promediamos las predicciones de todos los modelos, ponderando sus contribuciones en función de la posteriori. Esto significa que si un conjunto de pesos es altamente probable, su predicción correspondiente tiene más peso.
Vamos a formalizar todo esto:

La inferencia en el Aprendizaje Profundo Bayesiano integra todos los posibles valores de theta (pesos) utilizando la distribución posterior.
También podemos ver que en las Estadísticas Bayesianas, las integrales están en todas partes. Esta es en realidad la principal limitación del marco bayesiano. Estas integrales son a menudo intractables (no siempre conocemos una primitiva de la posteriori). Por lo tanto, tenemos que hacer aproximaciones muy costosas computacionalmente.
Ventajas del Aprendizaje Profundo Bayesiano
Ventaja 1: Estimación de incertidumbre
- Arguably the most prominent benefit of Bayesian Deep Learning is its capacity for uncertainty estimation. In many domains including healthcare, autonomous driving, language models, computer vision, and quantitative finance, the ability to quantify uncertainty is crucial for making informed decisions and managing risk.
Ventaja 2: Mejora en la eficiencia del entrenamiento
- Closely tied to the concept of uncertainty estimation is improved training efficiency. Since Bayesian models are aware of their own uncertainty, they can prioritize learning from data points where the uncertainty — and hence, potential for learning — is highest. This approach, known as Active Learning, leads to impressively effective and efficient training.
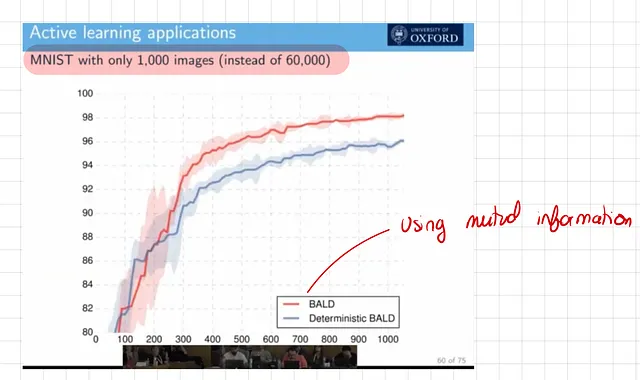
Como se muestra en el gráfico a continuación, una Red Neuronal Bayesiana utilizando Aprendizaje Activo logra una precisión del 98% con solo 1,000 imágenes de entrenamiento. En contraste, los modelos que no aprovechan la estimación de incertidumbre tienden a aprender a un ritmo más lento.
Ventaja 3: Sesgo inductivo
Otra ventaja del Aprendizaje Profundo Bayesiano es el uso efectivo de sésgos inductivos a través de priors. Los priors nos permiten codificar nuestras creencias o suposiciones iniciales sobre los parámetros del modelo, lo cual puede ser particularmente útil en escenarios donde existe conocimiento del dominio.
Considera la Inteligencia Artificial generativa, donde la idea es crear nuevos datos (como imágenes médicas) que se asemejen a los datos de entrenamiento. Por ejemplo, si estás generando imágenes del cerebro, y ya conoces la disposición general de un cerebro: materia blanca en el interior, materia gris en el exterior; este conocimiento puede ser incluido en tu prior. Esto significa que puedes asignar una probabilidad más alta a la presencia de materia blanca en el centro de la imagen y materia gris hacia los lados.
En esencia, el Aprendizaje Profundo Bayesiano no solo permite a los modelos aprender de los datos, sino que también les permite comenzar a aprender desde un punto de conocimiento, en lugar de comenzar desde cero. Esto lo convierte en una herramienta potente para una amplia gama de aplicaciones.

Limitaciones del Aprendizaje Profundo Bayesiano
Parece que el Aprendizaje Profundo Bayesiano es increíble. Entonces, ¿por qué este campo es tan subestimado? De hecho, a menudo hablamos de la Inteligencia Artificial Generativa, Chat GPT, SAM o redes neuronales más tradicionales, pero casi nunca escuchamos sobre el Aprendizaje Profundo Bayesiano, ¿por qué?
Limitación 1: El Aprendizaje Profundo Bayesiano es lento
La clave para entender el Aprendizaje Profundo Bayesiano es que “promediamos” las predicciones del modelo, y siempre que haya un promedio, hay una integral sobre el conjunto de parámetros.
Pero calcular una integral a menudo es intratable, esto significa que no hay una forma cerrada o explícita que haga que el cálculo de esta integral sea rápido. Por lo tanto, no podemos calcularla directamente, tenemos que aproximar la integral mediante el muestreo de algunos puntos, y esto hace que la inferencia sea muy lenta.
Imagina que para cada punto de datos x tenemos que promediar la predicción de 10,000 modelos, y que cada predicción puede tomar 1 segundo en ejecutarse, terminamos con un modelo que no es escalable con una gran cantidad de datos.
En la mayoría de los casos empresariales, necesitamos inferencia rápida y escalable, por eso el Aprendizaje Profundo Bayesiano no es tan popular.
Limitación 2: Errores de Aproximación
En el Aprendizaje Profundo Bayesiano, a menudo es necesario utilizar métodos aproximados, como la Inferencia Variacional, para calcular la distribución posterior de los pesos. Estas aproximaciones pueden conducir a errores en el modelo final. La calidad de la aproximación depende de la elección de la familia variacional y la medida de divergencia, lo cual puede ser desafiante de elegir y ajustar correctamente.
Limitación 3: Aumento de la Complejidad e Interpretabilidad del Modelo
Aunque los métodos bayesianos ofrecen medidas mejoradas de incertidumbre, esto conlleva un aumento en la complejidad del modelo. Las BNN (Redes Neuronales Bayesianas) pueden ser difíciles de interpretar porque en lugar de un solo conjunto de pesos, ahora tenemos una distribución de pesos posibles. Esta complejidad puede generar desafíos para explicar las decisiones del modelo, especialmente en campos donde la interpretabilidad es fundamental.
Existe un creciente interés por la XAI (Inteligencia Artificial Explicable), y las Redes Neuronales Profundas Tradicionales ya son difíciles de interpretar porque es difícil dar sentido a los pesos, el Aprendizaje Profundo Bayesiano es aún más desafiante.
Si tienes comentarios, ideas para compartir, quieres trabajar conmigo o simplemente quieres decir hola, por favor completa el siguiente formulario y comencemos una conversación.
Di Hola 🌿
No dudes en dar un aplauso o seguirme para más contenido.
Referencias
- Ghahramani, Z. (2015). Aprendizaje automático probabilístico e inteligencia artificial. Nature, 521(7553), 452–459. Enlace
- Blundell, C., Cornebise, J., Kavukcuoglu, K., & Wierstra, D. (2015). Incertidumbre en los pesos de las redes neuronales. Preimpresión de arXiv arXiv:1505.05424. Enlace
- Gal, Y., & Ghahramani, Z. (2016). Dropout como una aproximación bayesiana: Representando la incertidumbre del modelo en el aprendizaje profundo. En conferencia internacional sobre aprendizaje automático (pp. 1050–1059). Enlace
- Louizos, C., Welling, M., & Kingma, D. P. (2017). Aprendizaje de redes neuronales dispersas mediante regularización L0. Preimpresión de arXiv arXiv:1712.01312. Enlace
- Neal, R. M. (2012). Aprendizaje bayesiano para redes neuronales (Vol. 118). Springer Science & Business Media. Enlace
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Lectura de playa una breve historia de los modelos pre-entrenados
- La evolución de OpenAI Una carrera hacia GPT5
- ¿Qué puedes hacer cuando la inteligencia artificial miente sobre ti?
- OpenAI presenta 6 emocionantes características de ChatGPT para revolucionar la experiencia del usuario
- Clasificación Multietiqueta Una Introducción con Scikit-Learn de Python
- Fraude impulsado por IA ‘Deepfake’ La batalla continua de Kerala contra los estafadores
- Principales herramientas de IA para contabilidad 2023





